=Start=
缘由:
学习、提高需要
正文:
参考解答:
信息早期的“数据安全”多指“数据库安全”,主要是针对存储状态的静态数据在数据库层面开展的安全保护,侧重于对数据库中的数据进行访问控制和加密存储,该阶段的数据安全多为对关系型数据库中存储的结构化数据的安全管理。伴随着云计算和大数据技术的发展和普及,组织也开始关注对半结构化数据和非结构化数据的价值挖掘,数据逐渐成为组织机构的重要资产,在业务发展、企业运营等关键环节中产生着更多的价值。
然而,在云计算和大数据环境以及多样化的工作方式、BYOD等新型模式的冲击下,组织的电子化数据不再仅仅存储于单一的信息系统和工作环境中,数据会经由组织及组织相关的业务流程及应用,在各业务系统、云平台、工作终端、员工的个人终端等不同的系统环境中进行流转和处理。同时,数据作为组织的重要资产面临着内外部的双重风险–外部日益复杂的攻击形式(甚至是国与国之间的安全对抗)以及恶意或误操作引发的内部风险,对组织的数据安全能力提出了更高的要求。
一方面,传统“边界安全防护”的思想所指导的安全工作聚焦于对承载数据的资产对象(如网络、系统)的独立安全控制,重点关注资产对象之间的边界安全,而大数据环境下数据在各安全边界之间的流转则是在打破原有的安全边界,边界安全防护的思想无法实现对数据的有效保护。另一方面,伴随着大数据产业的发展,对数据的安全保护面临着诸多合法合规要求,与国家安全、经济利益和个人隐私保护等利益相关的数据往往都需要符合数据的留存地点、留存时长等要求,数据的价值特性决定了大数据环境下安全工作的开展需要考虑对合法合规要求的符合。
组织需要围绕数据的生命周期、结合大数据业务的需求以及监管法规的要求,持续不断的提升组织整体的数据安全能力,以数据为核心的安全是大数据环境下的组织数据安全工作开展的核心。
数据安全成熟度模型介绍
整体介绍数据安全成熟度模型(Data Security Maturity Model, DSMM)的架构如图1所示,模型包含以下三个维度:
- 数据生命周期维度:组织在数据生命周期各阶段开展的数据安全实践构成了数据安全的过程域。
- 数据安全能力维度:组织完成数据安全过程域所需要具备的能力。
- 能力成熟度等级维度:对组织的数据安全能力进行成熟度等级评估的标准。
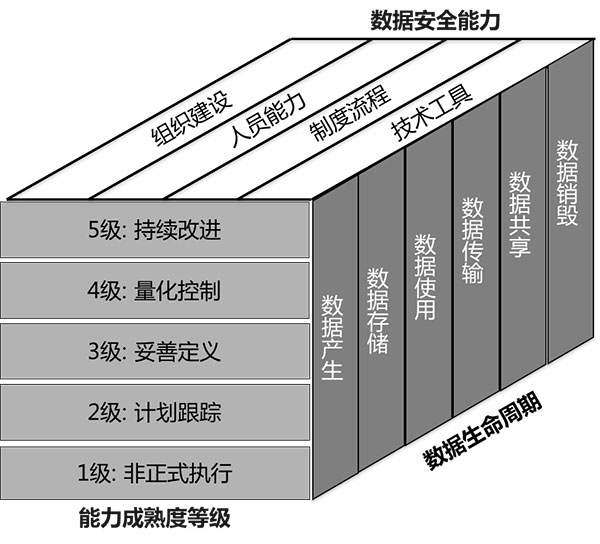
图1 数据安全成熟度模型架构
通过对模型的应用可以帮助组织机构了解其整体的数据安全风险,有针对性制定解决方案;建立组织内部整体的数据安全管理体系;明确自身的数据安全管理水平并确定后期建设的方向。
数据生命周期
数据生命周期基于大数据环境下数据在组织业务中的流转情况,定义了数据的六个生命周期阶段,各阶段的定义如下:
- 数据产生:指新的数据产生或现有数据内容发生显著改变或更新的阶段;
- 数据存储:指非动态数据以任何数字格式进行物理存储的阶段;
- 数据使用:指组织在内部针对动态数据进行的一系列活动的组合;
- 数据传输:指数据在组织内部从一个实体通过网络流动到另一个实体的过程;
- 数据共享:指数据经由组织与外部组织及个人产生交互的阶段;
- 数据销毁:指利用物理或者技术手段使数据永久或临时性的不可用的过程。
数据安全能力
通过对各项安全过程所需具备安全能力的量化,可供组织评估每项安全过程的实现能力。数据安全能力从组织建设、人员能力、制度流程及技术工具四个维度展开:
- 组织建设:数据安全组织的架构建立、职责分配和沟通协作。
- 人员能力:执行数据安全工作的人员的意识及专业能力。
- 制度流程:组织关键数据安全领域的制度规范和流程落地建设。
- 技术工具:通过技术手段和产品工具固化安全要求或自动化实现安全工作。
能力成熟度等级
能力成熟度等级维度组织的数据安全成熟度模型具有5个成熟度等级,如下表所述:

参考链接:
=END=
《 “[collect]数据安全能力成熟度模型” 》 有 45 条评论
美团数据仓库-数据脱敏
https://tech.meituan.com/data-mask.html
数据脱敏:保证银行数据安全的重要手段
http://www.prnews.cn/press_release/51034.htm
动态脱敏的技术演进面临五个技术壁垒
https://mp.weixin.qq.com/s/hDTQUoUjSrjhQrwPIfR_ew
针对Amazon S3存储的扫描/下载工具
==
S3Scanner: Scan for open S3 buckets and dump
https://github.com/sa7mon/S3Scanner
Public S3 Bucket Search Engine
http://blog.rojanrijal.com/2017/12/public-s3-bucket-search-engine-open.html
https://github.com/tomdev/teh_s3_bucketeers
大数据安全保护思考
http://www.freebuf.com/articles/database/160564.html
`
随着大数据时代的来临,企业数据开始激增,各种数据在云端、移动设备、关系型数据库、大数据库平台、pc端、采集器端等多个位置分散。对数据安全来说,挑战也更大了。在大型互联网企业里,传统方法已经很难绘制出一张敏感数据流转图了。因此在新的形势下,一是在工具层面要有新的手段支撑,包括完整的敏感数据视图、高风险场景识别、数据违规/滥用预警、数据安全事件的发现检测和阻止等。二是目前企业也存在着合规的问题了,以往合规对于互联网来说没那么重要,但随着网安法的出台,数据安全也摆上了日程。另外对于跨境企业来说,还面临着海外的数据安全法规。
对数据安全的综合治理,核心思路其实就是一个:数据流动地图,抓住这条主线,也就是以数据为核心的安全保护。大数据时代,基于边界的方法已经过时了,你无法阻挡数据的流动。而在新的时代,还有很多未能解决的难题,换句话说,作为一个安全人员,你是在挖洞的如云高手中杀出一条血路,还是在这个需要探索的领域做先头兵?
`
浅析金融大数据安全
http://www.freebuf.com/articles/database/109775.html
大数据安全第3期 | 国内外大数据安全与个人隐私安全标准
https://mp.weixin.qq.com/s/-f5hym2xdoE_QgwOEYV2DQ
`
目前,国内外有多个标准化组织正在开展大数据和大数据安全相关标准化工作,国际上主要有国际标准化组织/国际电工委员会下的ISO/IEC JTC1 WG9(大数据工作组)ISO/IEC JTC1 SC27(信息安全技术分委员会)、国际电信联盟电信标准化部门(ITU-T)、美国国家标准与技术研究院(NIST)等;国内正在开展大数据和大数据安全相关标准化工作的标准化组织,主要有全国信息技术标准化委员会(以下简称“全国信标委”,委员会编号为TC28)和全国信安标委(TC260)以及国家网络安全各个行业主管部门的监管和技术等行业标准。
本篇文章先分享一下目前已经发布和正在准备发布的相关标准列表,之后会和大家就内容进行标准研究和分析。
`
等保2.0之如何确定信息系统安全保护等级
https://mp.weixin.qq.com/s/VrVBE7I4pCOd5BOnwIAs9A
腾讯云发布《数据安全白皮书》 建设云端数据安全保护标准
https://mp.weixin.qq.com/s/txfyLTZebRJrOZ5P6v43FQ
国家标准《个人信息安全规范》全文
https://mp.weixin.qq.com/s/M5GWn3SXJt7OxAfI06_81A
关于GDPR,数据科学家和数据工程师需要知道些什么
http://www.infoq.com/cn/articles/effective-data-management-age-GDPR
https://www.infoq.com/articles/effective-data-management-age-GDPR
http://ec.europa.eu/justice/data-protection/reform/files/regulation_oj_en.pdf
https://medium.com/@domingal79/running-a-gdpr-project-practical-step-by-step-guide-56f95180abf2
小白谈数据脱敏 #可以参考一下里面的简单的脱敏代码
http://yoursite.com/2017/11/03/Data-Desensitization/
以“威胁应对”为中心,看企业信息安全能力建设
https://www.sec-un.org/%E4%BB%A5%E5%A8%81%E8%83%81%E5%BA%94%E5%AF%B9%E4%B8%BA%E4%B8%AD%E5%BF%83%E7%9C%8B%E4%BC%81%E4%B8%9A%E4%BF%A1%E6%81%AF%E5%AE%89%E5%85%A8%E8%83%BD%E5%8A%9B%E5%BB%BA%E8%AE%BE-%E6%9D%8E/
`
笔者将以威胁为中心的信息安全能力建设问题总结为以下四句话,并进行详细阐述:
1. 全面感知是基础
2. 异常行为是线索
3. 分析能力是关键
4. 响应处置是根本
`
数据脱敏——基于Java自定义注解实现日志字段脱敏
https://blog.csdn.net/huyuyang6688/article/details/77759844
https://github.com/DannyHoo/desensitized
基于注解的字段脱敏处理
https://blog.csdn.net/liuc0317/article/details/48787793
谷歌首席工程师:对大型复杂数据进行分析的实用建议
https://mp.weixin.qq.com/s/7JB3Y7GC7ZwmXp5aMTK4EQ
`
技巧:操作、检查数据的想法和技巧。
处理:关于数据处理方法、检查思路、检查方向的建议。
社交:如何和他人合作并传达自己的数据和见解。
`
The GDPR Checklist
https://gdprchecklist.io/
https://github.com/privacyradius/gdpr-checklist
互联网公司数据安全保护新探索
https://mp.weixin.qq.com/s/56JwbVbWgHCqUAJARQ43mA
`
在互联网公司的数据安全领域,无论是传统理论提出的数据安全生命周期,还是安全厂商提供的解决方案,都面临着落地困难的问题。其核心点在于对海量数据、复杂应用环境下的可操作性不佳。
一、应用系统
1.1 扫号及爬虫
1.2 水印
1.3 数据蜜罐
1.4 大数据行为审计
1.5 数据脱敏
二、数据仓库
2.1 数据脱敏
2.2 隐私保护
2.3 大数据资产地图
2.4 数据库扫描器
`
互联网企业:如何建设数据安全体系?
https://mp.weixin.qq.com/s/y89__2zjZavVo3Zq_E3GrA
https://tech.meituan.com/Data_Security_System_Construction.html
`
一、背景
Facebook数据泄露事件
二、概念
这里特别强调一下,“隐私保护”和“数据安全”是两个完全不同的概念。
隐私保护:对于安全专业人员来说是一个更加偏向合规的事情,主要是指数据过度收集和数据滥用方面对法律法规的遵从性。
数据安全:是实现隐私保护的最重要手段之一。
三、全生命周期建设
数据采集
全站HTTPS
Keyless CDN
跨IDC自动加密
反爬
帐号安全
UUID
前台业务处理
全程ticket鉴权
用户token&服务token
SSO
可信计算
服务化(访问DB必须通过API)
RPC鉴权
RPC加密
SQL审计
数据存储
密钥HSM化
统一KMS
结构化(静态数据加密)
per-file加密
文件系统加密
访问和维护
运维堡垒机
debug脱敏
监控日志脱敏
RD/运维分离
生产转测试脱敏
后台数据分析
ETL加密
数仓加密
审计大盘
匿名化算法
展示和使用
水印
DLP
beyondCorp模型
展示脱敏
数仓堡垒机
共享和再分发
隐私声明
授权审核
脱敏
防止下游缓存
安全SDK
数据销毁
安全删除
`
金融企业数据安全建设实践系列(一)
https://mp.weixin.qq.com/s/fiQqdARZ9NBeKI85mUPJOQ
金融企业数据安全建设实践系列(二)
https://mp.weixin.qq.com/s/k1dmW2UBLYLrrOpmtaAoag
DPO社群对数据堂事件的精彩点评
https://mp.weixin.qq.com/s/1addFBb2ye3iumsXNh9fxg
至今为止GDPR《通用数据保护规范》解释的最清楚的文章
https://mp.weixin.qq.com/s/-XzsGAsCl89xo9gb80M3Vw
个人数据保护最严条例发布,你的安全建设做到哪一步?
https://mp.weixin.qq.com/s/i9JqWHkIR9yfm5LaHixFBA
深度整理 | 欧盟《一般数据保护法案》(GDPR)核心要点
http://www.freebuf.com/column/170881.html
从Google隐私政策修订看企业应对GDPR的策略
https://mp.weixin.qq.com/s/nZ5Lx6Uvooedi3p5ODWZ_A
【知识库】互联网企业的信息安全成熟度模型
https://mp.weixin.qq.com/s/YsWwq2qDDFHJAjWF1XAf_g
`
IT领域的成熟度模型
首先说到IT领域的成熟度模型,一般参考CMM或者COBIT。但是这两个模型都不太适合快速发展的互联网企业,因为CMM适用于软件开发,与企业的信息安全成熟度模型相差甚远。COBIT虽然是针对企业IT的成熟度模型,笔者以前也经常会将此模型映射到信息安全维度来做评价,但是落在互联网企业中有些格格不入,或者说COBIT过多地强调以规章制度建设作为过度的中间层,而忽视了互联网企业对安全、体验与效率的高要求。
成熟度模型的六个级别
0级 无级别
1级 定义级
2级 管理级
3级 工具级
4级 平台级
5级 优化级
`
手把手教你如何设计日志脱敏插件
https://mp.weixin.qq.com/s/ZeLkV5oUWzVl8QIyJFH0zA
企业数据安全建设的经历与实践
https://mp.weixin.qq.com/s/ItvWWhC0iYOpG6nQ3WPfvg
`
1.为什么做
2.该怎么做
3.落地改造
4.问题与效果
`
华为数据安全管理实践学习笔记
https://paper.tuisec.win/detail/701f515c2d31d00
http://www.lewisec.com/2016/09/05/%E5%8D%8E%E4%B8%BA%E6%95%B0%E6%8D%AE%E5%AE%89%E5%85%A8%E7%AE%A1%E7%90%86%E5%AE%9E%E8%B7%B5%E5%AD%A6%E4%B9%A0%E7%AC%94%E8%AE%B0/
`
1. 原则
2. 信息分级分类
3. 融入业务流程
4. 安全服务举例
5. 安全流程
资产清单是管理的抓手,只有明确了要保护什么,才能有的放矢。但梳理信息资产清单,并设计可落地的分级分类措施,这是难点。如何让员工短时间内学会并准确执行分级分类的要求?如何以流程化的方式确保分级分类的落地?这才是管理的核心问题。
`
国家千人计划教授任奎:数据安全的现状与趋势(全文)
https://mp.weixin.qq.com/s/G0lLc4PZtomkBd5s3l5qgw
分析:数据泄露如何影响股市股价(Analysis: How data breaches affect stock market share prices)
https://www.comparitech.com/blog/information-security/data-breach-share-price-2018/
一个人的安全部之大话企业数据安全保护
http://www.freebuf.com/articles/database/185288.html
`
1.设计思路
2.数据安全威胁
3.规划内容
3.1 访问控制
3.2 身份认证
3.3 数据加密&脱敏
3.4 容灾备份/恢复
3.5 安全审计
3.6 全面防护
4. 最后
`
大数据安全入门-Hadoop
http://blackwolfsec.cc/2018/09/29/Hadoop/
我看到的数据安全
https://weibo.com/ttarticle/p/show?id=2309404300856420895077
`
第一类安全需求:资产安全:更强调对静态资产本身价值的保护。防范的是企业资产损失。资产安全是企业最早遇到的安全需求.
第二类安全需求:业务安全;随着市场化进程的加深,企业业务面临更多来自客户的不确定性因素和竞争对手的恶性竞争。如何保证业务的可持续性,减少外部环境带来的业务风险,以及具备和竞争对手恶意竞争的对抗能力,保护企业业务竞争力。对企业而言,业务安全远远大于资产安全,因为一个企业存在的目的是通过业务持续盈利,资产风险更多是成本问题,业务风险是影响自己业务模式是否可行的生存问题。
第三类安全需求:生产安全;随着工业化进程的发展,企业生产的产品越来越复杂,可能是个由原材料、材料、半成品、组件、再到产品的复杂过程,即使内部每个过程,工艺也需要多个环节,形成复杂的上下游生产流通的供应链体系;如果各种生产资料管理不善、生产过程管理不善,可能带来高危事件如爆炸的损失远远高于生产资料本身资产属性价值的损失;同时产出的产品如果因为生产资料和生产过程管理不善产生的质量问题,也可能会输出到外界形成高危的社会公众安全风险(如有毒食品、过期疫苗),因此在生产过程中需要管控整个的安全;生产安全不仅可能既带来远大于资产的损失(如爆炸可能带来远大于生产资料价值的损失),也可能带来业务安全风险(如输出带毒奶粉导致奶粉行业一蹶不振)。
1) 以前的数据安全,强调的是资产属性价值保护;本质而言谈的是信息在数据载体上的安全;而我们强调的是数据作为生产资料,在生产过程中的整个安全管理体系。关注对数据可能带来的风险进行控制。
2) 以前的数据安全,站在资产视角以保护的视角居多,防范的主要是外部威胁;或者内部人员的恶意行为;而我们强调的是需要建立针对数据流动和使用的风险控制体系,需要一整套的规范、数据分类管理体系、场景控制流程、可追溯体系、数据风险识别和度量体系、检测体系;主要是防范内部各种涉及数据的生产系统以及人员的不规范行为,导致的各类数据风险(数据自身以及数据带给其他主体和客体的f风险,当然也内降低内部人员的恶意行为以及外部威胁混入内部伪装成内部人员带来威胁的可能)
`
成为数据科学家需要哪些技能?(翻译)
https://mp.weixin.qq.com/s/8DdqbGQ9PpPHMZ29Wrg-SA
https://towardsdatascience.com/what-are-the-skills-needed-to-become-a-data-scientist-in-2018-d037012f1db2
数据科学家面试常见的77个问题
https://mp.weixin.qq.com/s/rumh7lKSpi1Lf9mg4z_42g
http://www.datasciencecentral.com/profiles/blogs/66-job-interview-questions-for-data-scientists
大数据与数据脱敏
https://zhuanlan.zhihu.com/p/20824603
`
K-Anonymity
L-Diversity
T-Closeness
常见的数据变形处理方式如下:
隐藏(Hiding)
哈希(Hashing)
映射(Permutation)
偏移(Shift)
枚举(Enumeration)
阶段(Truncation)
保留前n位(Prefix-preserving)
掩码(Mask)
取整(Floor)
`
数据脱敏——什么是数据脱敏
https://blog.csdn.net/huyuyang6688/article/details/77689459
美团数据仓库-数据脱敏
https://tech.meituan.com/data_mask.html
https://github.com/huifenqi/arch/blob/master/decisions/0038-data-masking.md
浅析数据安全脱敏工具
https://www.freebuf.com/column/161463.html
大数据平台数据脱敏介绍
https://cloud.tencent.com/info/758f744d532616e1f5a0858dc90ba524.html
大数据隐私保护技术之脱敏技术探究
https://www.freebuf.com/articles/database/120040.html
`
脱敏方法现在有很多种,比如k-匿名,L多样性,数据抑制,数据扰动,差分隐私等。
k-匿名:
匿名化原则是为了解决链接攻击所造成的隐私泄露问题而提出的。链接攻击是这样的,一般企业因为某些原因公开的数据都会进行简单的处理,比如删除姓名这一列,但是如果攻击者通过对发布的数据和其他渠道获得的信息进行链接操作,就可以推理出隐私数据。
k-匿名是数据发布时保护私有信息的一种重要方法。 k-匿名技术是1998 年由Samarati和Sweeney提出的 ,它要求发布的数据中存在至少为k的在准标识符上不可区分的记录,使攻击者不能判别出隐私信息所属的具体个体,从而保护了个人隐私, k-匿名通过参数k指定用户可承受的最大信息泄露风险。
但容易遭受同质性攻击和背景知识攻击。
L-多样性
L多样性是在k-匿名的基础上提出的,外加了一个条件就是同一等价类中的记录至少有L个“较好表现”的值,使得隐私泄露风险不超过 1/L,”较好表现“的意思有多种设计,比如这几个值不同,或者信息熵至少为logL等等..
但容易遭受相似性攻击。
数据抑制
数据抑制又称为隐匿,是指用最一般化的值取代原始属性值,在k-匿名化中,若无法满足k-匿名要求,则一般采取抑制操作,被抑制的值要不从数据表中删除,要不相应属性值用“ ** ”表示。
数据扰动
数据扰动是通过对数据的扰动变形使数据变得模糊来隐藏敏感的数据或规则,即将数据库 D 变形为一个新的数据库 D′ 以供研究者或企业查询使用,这样诸如个人信 息等敏感的信息就不会被泄露。通常,D′ 会和 D 很相似,从 D′ 中可以挖掘出和 D 相同的信息。这种方法通过修改原始数据,使得敏感性信息不能与初始的对象联系起来或使得敏感性信息不复存在,但数据对分析依然有效。
差分隐私
差分隐私应该是现在比较火的一种隐私保护技术了,是基于数据失真的隐私保护技术,采用添加噪声的技术使敏感数据失真但同时保持某些数据或数据属性不变,要求保证处理后的数据仍然可以保持某些统计方 面的性质,以便进行数据挖掘等操作。
差分隐私保护可以保证,在数据集中添加或删除一条数据不会影响到查询输出结果,因此即使在最坏情况下,攻击者已知除一条记录之外的所有敏感数据,仍可以保证这一条记录的敏感信息不会被泄露。
`
企业安全建设之探索安全数据分析平台
https://xz.aliyun.com/t/3294
`
0x01 背景
0x02 技术架构简单介绍
0x03 各大公司数据平台技术架构对比
0x04 我的安全数据分析平台
0x05 模型部署和系统落地
0x06 Reference
`
《数据库安全应用指南》重磅发布 数据安全不再为难
http://www.4hou.com/data/14694.html
`
安全行业的行业特性用三个字形容就是“小、碎、大”:“小”指的是现有市场容量小,现在只有400亿的市场;“碎”指的是安全团队结构细、不会出现大公司垄断、碎片化的区域市场;“大”指的是未来大,因为从过去的计算机安全,到现在的网络安全,未来将是万物互联时代的Digital Security,前景无限。
数据安全建设实践落地的四个实施阶段(组织建立→能力评估→制度设计→技术设计),这一过程需要做到以“数据”为中心,遵循数据摸底、数据管控、行为稽核的路线,来完成整个数据安全治理动作。
`
征文 | 蔚晨:数据驱动的安全防控体系探究
https://mp.weixin.qq.com/s/GlVHssqRefXpMvFg70kFLA
`
一、数据安全面临的三个问题
伴随信息技术的高速发展,安全风险日益变化,单纯从基础安全防护视角出发,只能满足部分数据安全需求,难以应对新型的安全风险,主要有以下几个层面原因:
第一,信息化建设与安全防护是两个相对独立的松耦合过程。数据的生命周期和价值大部分在信息系统中实现,信息系统是保障数据资产安全的第一道防线。然而,信息化建设侧重于信息系统的业务功能和流程实现,聚焦数据的流转与加工,对安全防护的关注有限,仅提供开发视角的安全防护,通过开发规范和安全组件实现。安全防护呈现专业化趋势,针对信息系统面临的风险,使用独立于信息系统的基础安全防护系统提供防护。对于数据资产的保护而言,信息化建设与安全防护没有形成有效合力。
第二,安全风险日益复杂,不同的基础安全防护系统间缺乏应对安全风险的联动机制。当前,多层面的安全风险不断增加,攻击行为呈现分布化、规模化、复杂化等趋势,依靠单一的基础安全防护系统提供防护,难以应对当前安全需求和态势,迫切需要多个基础安全防护系统协同防护才能应对。基础安全防护关注数据在单一场景下的安全,进行专项防护,形成防护孤岛,防护数据难关联,缺乏联动机制。
第三,基础安全防护通过保障信息系统的安全,从而实现信息系统中数据资产的安全,属于间接防护。信息系统处于安全状态时,数据资产仍存在安全风险。内部人员相对外部攻击者更容易接近重要信息系统,内部人员有更大动力或倾向利用合法权限获利。2015年FortScale调查反馈85%的数据泄露来源于内部威胁。针对数据使用场景,内部防控过严,影响业务实现、数据转移和安全防控的效率;内部防控过松,可能产生很多不可知的安全风险。基础安全防护灵活性有限,难以针对内部合规性问题,提供精细化、弹性化的有效防控。
二、数据驱动的安全防控体系
在技术体系层面,数据驱动的安全防控体系,以数据驱动的方式,针对特定数据对象,提供贯穿数据的产生、传输、存储、使用和销毁等数据生命周期全过程的感知、分析、评估和管控,以指标集、规则集、策略集为支撑,实现数据安全状态可视化、数据安全事件可视化、数据安全管控智能化、数据安全管控智能反馈、数据安全管控智能联动、数据安全态势智能评估。
三、数据驱动防控体系落地
构建数据驱动的安全防控体系,需要在管理层面进行体系建设:
第一,明确数据安全防控主体权责,确定数据安全防控的管理者、责任者、实施者的身份与权责。
第二,建立数据安全防控管理制度,完整覆盖数据安全防控体系,保证数据安全防控体系顺利运行。数据安全防控管理制度需具备可操作性,应定期审查,依据实施反馈与特定需求予以变更,确保其持续的适宜性。
第三,建立数据安全防控标准规范,确保数据安全防控体系在技术和管理层面有统一、科学、规范的依据,保证数据安全防控顺利开展,推动数据安全防控技术进步,提升数据安全防控实践效果。
第四,构建数据安全防控培训机制,定期组织数据安全防控主体参与培训,提升数据安全防控主体参与数据安全防控过程的能力与水平。
第五,设立数据安全防控考评机制,对数据安全防控主体参与数据安全防控过程进行检查和评定,指导、约束和审计数据安全防控主体行为,促进数据安全防控主体间的联动协作。
`
新形势下的数据保护
http://blog.nsfocus.net/data-protection-situation/
`
近年来,我国政府高度重视数据在新常态中推动国家现代化建设的基础性、战略性作用。2015年9月国务院印发的《促进大数据发展行动纲要》指出,“数据已成为国家基础性战略资源,大数据正日益对全球生产、流通、分配、消费活动以及经济运行机制、社会生活方式和国家治理能力产生重要影响。”2016年3月发布的“十三五规划纲要”还专章提出“实施国家大数据战略”,明确我国将“把大数据作为基础性战略资源,全面实施促进大数据发展行动,加快推动数据资源共享开放和开发应用,助力产业转型升级和社会治理创新。”2017年6月1日,正式实施《网络安全法》的网络安全法,对数据安全和个人数据保护也给予了足够的关注。
欧盟GDPR(一般数据保护条例)已于2018年5月25日正式生效,这更是一部专门针对数据保护所制定的条例。根据规定,它的影响将不仅限与整个欧盟(EU)范围内。而是适用于所有处理和持有欧盟居民个人资料的公司,而不论公司地理位置。以上这些国家战略和法律法规无疑对金融行业数据保护提出了新的要求。
一.关注云上数据安全
二.关注大数据存储安全
三.关注数据使用安全
3.1 提高数据使用者安全意识
3.2 关注低敏感数据
3.3 重视数据治理
3.3.1 数据资产挖掘能力
3.3.2 数据跟踪能力
3.3.3 数据价值定义能力
四. 总结
`
大数据安全保护思考
https://www.freebuf.com/articles/database/160564.html
DSMM第四期与我的数据安全观
https://iami.xyz/DSMM-Date-Security/
`
数据安全人员能力
管理能力
战略规划
解决方案
团队构建
协同管理
运营能力
推广落地
利用工具
识别风险
宣传教育
技术能力
国内外前沿
评估和判断
风险排查
合规能力
内部推动落地
外部监管应对
明确以数据为中心、以能力成熟度为抓手、以组织为单位的基本原则
`
企业数据加解密方案
https://www.qiaoyue.net/2019/%E4%BC%81%E4%B8%9A%E6%95%B0%E6%8D%AE%E5%8A%A0%E8%A7%A3%E5%AF%86%E6%96%B9%E6%A1%88/
`
数据保护是近年来关注度极高的议题,一则国家立法,属合规性要求,二则泄漏事件频发,保护核心数据是安全部门最紧迫的里子工程(面子工程要吹得出去,里子工程要落得了地),然而数据保护从数据的生产、分类分级(打标)、传输、存储、使用、分析、外发到销毁,要全流程介入,任一环节出现缺漏都可能会功亏一篑,这就导致数据防护战线拉得过长,这与安全部门最擅长的重点突破,严卡枢纽的作战方式不同,要回到熟悉的战场就需要找到能牵一发而动全身的发力点,让整个数据链条向其收拢,依靠这种强依赖关系,人力紧缺的安全部门在数据保护的项目运作中也可有的放矢,而这个发力点就是——数据加解密平台。
数据保护方案的前置条件是一定要遵从公司的发展愿景,不能因过度保护而阻碍数据赋能,这也是加解密方案实施过程中最大的阻力,大多数时候评估是否会阻碍数据赋能的话语权在业务方,这就需要方案制订者明确安全红线所在,设置合理的数据分类分级标准,且能提供对业务改动最小的整改方案。
站在数据加解密系统的视角,数据可分类为以下两种:
1. 封闭数据。即沉寂数据,在业务流程内流转,数据链路在本业务闭环。例如:常见的用户基本信息字段(身份证、邮箱、银行卡、支付密码等)
2. 赋能数据。即数据有附加价值,需聚合、分析,数据链路的中后段从业务流向数据仓库,基本已经脱离了原有的数据使用逻辑,加之部分大数据组件在设计之初就忽视安全因素,相当于危楼上建高层,这类数据一定要花大量时间摸清数据流向和脉络。例如:订单数据、用户浏览数据等。
外发类数据:
针对该类数据的保护,投入成本巨大,且需要极大的行业影响力才有能力完成闭环,可参考阿里的打法,其借助阿里云及诸多平台提供了较好的范本。
阿里外发数据:
1、所有产品控制在阿里云场景,虽然业务逻辑上属三方系统,但一直没跑出阿里的五指山;
2、三方系统做埋点监控;
3、御城河系统做统一的监控、调度。
`
御城河介绍
https://eco-doc.alibaba.com/doc2/detail.htm?treeId=227&articleId=105400&docType=1
`
御城河基于阿里海量的基础数据和强大的数据分析能力,利用行业领先的风险检测模型,为电商生态中的商家、服务商、物流伙伴提供数据风险的预防和发现服务,实时检测和识别设备、账号、应用、系统中的异常数据访问行为并进行适当处置,实现数据风险的事前防控、事中检测、事后追溯,保障核心数据安全。御城河已经覆盖了93%淘系交易订单,每天帮助服务商分析6.5亿次核心数据访问行为并拦截风险,每天帮助物流商分析3500万次。有超过300万商家的近800万终端在使用受保护的服务商或物流应用。在这套大数据系统的支持下,阿里巴巴已协同各地公安办理24个信息泄露大案,共抓捕犯罪嫌疑人200多人。
# 数据风险预防
针对系统、应用、帐号中的高危数据风险点,提供主机权限管控、安全登录通道、应用保护、帐号风控、身份二次验证、数据加解密等多维度的风险预防服务,实现数据风险的事前防控。
# 数据风险发现
使用标准数据接入方案,可轻松便捷将应用或物流系统的账号登陆、操作行为、系统环境等数据接入御城河风控引擎。整合阿里巴巴海量基础数据及大数据分析能力,并通过数据风险分析模型,助力您分析接入的数据。实时发现账号、人员、系统中数据泄露的相关风险,让您“看见”数据风险。
# 数据风险预警
一旦识别数据风险,预警报告将第一时间多渠道触达安全联系人。
# 数据风险处置
提供了风险详情及反馈渠道,同时提供海量数据的毫秒级审计工具,便于您准确定位问题,将风险扼杀在萌芽状态。
`
干货|从0到1建立企业数据安全评级体系(详细实施步骤)
https://mp.weixin.qq.com/s/3G8v8aBVu_Ie9lHTFFS7cg
`
一、划分数据安全定级的3个维度
首先,根据原力大数据项目经验,我们建议在充分考虑数据安全要求的基础上,按照涉密性、重要性、泄密风险性3个维度划分数据安全等级
第一,数据重要性维度:按照数据资产价值进行分类,根据数据性质、数据价值、使用范围区分数据重要性。
第二,数据涉密维度:根据数据的涉密级别、接触范围区分数据涉密程度,结合数据重要性维度,制定不同涉密级别、不同数据重要性的数据安全等级保护措施。
第三,数据泄密风险维度:根据失密所造成的损失的因素来进行划分,结合数据涉密性更好地确定数据安全人员的保密责任。
二、细化各维度下的评判主题
然后,还需要从这3个重要维度建立多项细化的评判主题,建立起全面的数据安全评级体系
表1 数据安全评级体系
三、制定细分主题的评分标准
接着,可以进一步对各维度下的每个评判主题制定3级评分标准,进一步实现数据安全级别可量化测量
表2 数据涉密性细化主题评判标准
表3 数据重要性细化主题评判标准
表4 数据泄密风险性细化主题评判标准
四、配置维度和主题权重
最后,还应该建立数据安全级别评分权重体系,包括对3个数据安全级别维度的赋权和各个评判主题的二次赋权
表5 数据安全级别评分权重体系
至此,我们已经建立完善的数据安全评级体系,共包括3个主要维度,11个细分评判主题及其3级评分标准。
一般而言,可以以0-5分评定,0分代表数据安全等级最低,不需要特别的安全管理,5分反之。每个主题的得分按权重折算,总分四舍五入得到0-5级的数据安全级别评定。
结语:
原力大数据深耕大数据应用10余年,积累了百余个大数据项目实践案例,为企业完善了数据安全管理体系。
我们曾用上述数据安全评级体系,帮助某运营商进行数据安全评估管理,主要步骤及成果如下:
第1步,将其全量数据按数据形式划分为明细级和统计级数据,避免同一内容但不同形式数据存在安全等级不同的问题。
第2步,按照数据生成对象进行划分,区分不同的数据生成对象、数据产生系统、数据管理责任人以辅助评估数据涉密性。
第3步,按照数据性质细分数据类别,结合数据性质、数据使用范围,辅助评估数据重要性
第4步,对细分的各数据类别按照前文提到的3大维度进行数据安全等级评估
最终原力完成148项细分数据类别的数据安全等级评分,并在此基础上制定了针对不同安全等级的数据访问通用标准,同时分别定义数据在各部门、各角色的权限分配设置,真正实现了企业数据安全等级保护制度,有效防范了数据泄露、数据被盗等数据安全风险。
`
漫谈数据安全
https://mp.weixin.qq.com/s/4QdMloBHhtJXlG5SepOyEA
`
|0x01 一般意义上的数据安全流程
数据安全流程包括以下几个步骤:
数据的产生:通过数据分级体系对敏感字段打标签;
数据的存储:需要通过加密的方式存储相关数据,避免直接存储Text格式的数据;
数据的使用:包括了一个独立的权限控制系统;
数据的传输:相关的申请与查询操作需要通过专门的API接口进行,并且有高安全等级的加密措施;
数据的展示:在申请通过后,根据申请人的安全等级,展示对应等级的数据;
数据的销毁:敏感数据仅在HDFS上做逻辑删除是不够的,需要配合物理删除同步清理敏感数据。
|0x02 数据表分级标准
数据表分级的目标,在于通过设置合理的等级,加强对数据仓库平台下数据表的安全管理,确保敏感数据的增删改查操作都能够经过适合的授权。由于开发人员为使用便捷,数据表的安全等级通常存在安全等级设置偏低的情况,因而需要根据数据表中安全等级最高的字段进行表安全等级的设定。
|0x03 自动标签机制
很多时候,数据表并不只是由数据开发人员创建,产品、数据分析、运营等人员操作数据表,自行建立中间查询过程,也是需要被允许的,因而有必要设定一套自动数据标签的体系,来对初始创建的数据表进行自动的安全等级检定。
但该步骤极度依赖规范化的数据规则,例如同一种统计指标,只对应一种英文涵义。例如在搜索广告中,每次搜索的结果为搜索量,每次搜索中带有的广告展示称之为展现量,在英文名的设定上,show对应搜索量,ad_show对应广告展现量。这种规范化的体系应该贯穿在元数据平台及数据开发平台的建设上,例如在开发平台上使用Select *应该是被禁止的,需要准确写出Select show才可以展示对应数据。
自动标签机制能够根据预设的安全等级规则,例如show对应S2级别,ad_show对应S1级别,既可以准确标注其字段等级。其余字段,只要是常用的业务字段,也应该有明确的英文名称。最典型的是经纬度,字段统一命名为:longitude / latitude,系统可自动设定安全等级为S4。
当自动标签机制设定完成后,整理的授权流程如下所示:
* 使用人员新建任务;
* 系统扫描表字段,基于规则自动建立标签;
* 开发 / 安全人员根据规则升级 / 降级对应表等级;
* 通知相关人员权限变更。
|0x04 权限申请
权限申请类似于财务报销一样,需要经过层级审批才可以使用。通常来说S2及以下字段可以直接由数据安全接口人审批,S1需要数据安全接口人、使用人的直属上级领导两层审批。
数据权限的审批应遵循如下几个原则:
* 权限只根据需求进行授予,不能授予超过需求使用的字段及等级;
* 不允许直接查询底层表,只能查询中间表以上的数据表;
* 不允许查询全量数据,只可以根据字段进行查询,并且必须要有where条件;
* S2及以上数据,不允许直接下载,仅可以在云端查看;
* 只能够以单张表为单位,逐个申请,不允许一次性申请大范围的表权限。
|0xFF 风险管理
由于权限问题设计人员比较广,因此离职员工需要及时收回权限;
权限申请时,应该设定权限申请的时间,例如一天/一周/长期;非开发人员,如果权限申请时间过长,应该及时收回;
如果申请了权限而长期不使用,出于安全性考虑,也应该定期扫描并收回;
申请权限时,如有必要,应填写数据披露申请单,详细说明申请的原因,用于后续问题的排查。
`
腾讯安全首发企业级「数据安全能力图谱」
https://mp.weixin.qq.com/s/bLlkg7YQXM7nVQigIvBSiw
`
在数据安全体系建设时,你可能面临的困惑:
1、当前所管理的数据资产是否与实际资产相符,敏感数据都在哪里有,都在被谁访问;
2、已建设有部分安全产品,并进行了相应的策略配置,不清楚做的够不够;
3、清楚数据的重要性,有意识整体提升数据安全防护能力,但不知道如何开展,如何迭代;
4、数据安全相关制度已具备一些,不知道是否还有遗漏,不知道贯彻执行情况如何,怎么稽核;
5、平台建设方、运维方可能是同一团队,担心未来数据被滥用,如何形成制约;
6、现有的运行状况都存在哪些泄漏点、风险点,影响有多大;
7、知道数据安全投入是持续的,但还是想尽量避免重复投入,通过利旧、精准投入而实现降本增效。
腾讯数据安全能力图谱提出了六大能力,即数据资产管控能力、数据安全运营能力、数据业务安全管控能力、数据支撑环境安全管控能力、数据运维安全管控能力和数据安全感知能力,覆盖了数据全生命周期及重要的数据场景,在开展数据安全体系建设时具有很高的参考价值。
一. 数据资产管理能力
二. 数据安全运营能力
三. 数据业务安全管控能力
四. 数据支撑环境安全管控能力
五. 数据运维安全管控能力
六. 数据安全感知能力
`
数据安全法草案即将亮相:将确立数据分级分类管理、应急处置制度
https://mp.weixin.qq.com/s/bvd9-CNnqIvW1TUkE9-msA
https://m.mp.oeeee.com/a/BAAFRD000020200627338924.html
`
业界呼声颇高的数据安全法草案,即将在本月28日-30日举行的十三届全国人大常委会第二十次会议迎来初次审议。
2020年6月24日,全国人大常委会法工委发言人、研究室主任臧铁伟透露,数据安全法草案的内容主要包括:
确立数据分级分类管理以及风险评估、监测预警和应急处置等数据安全管理各项基本制度;
明确开展数据活动的组织、个人的数据安全保护义务,落实数据安全保护责任;
坚持安全与发展并重,规定支持促进数据安全与发展的措施;
建立保障政务数据安全和推动政务数据开放的制度措施。
在2018年9月被列入十三届全国人大常委会立法规划之前,关于数据安全立法的公开讨论极少。因此,这部“横空出世”的法律引发了不少期待和好奇:
数据安全法将解决哪些问题?
它与网络安全法、个人信息保护法的关系是什么?
1. 全球数据博弈深化加速数据安全法制定
2. 数据安全法是国家安全法的下位法
3. 加快制定数据安全法,明确数据主权
4. 企业最关注数据出境和本地化问题
`
数据安全能力建设思路
https://www.freebuf.com/articles/database/248950.html
https://mp.weixin.qq.com/s/a6TmrCgIkAAGC8DkiwglnA
`
一、前言
二、数据安全能力建设的驱动力
2.1 合规驱动
2.2 业务驱动
2.3 风险驱动
三、数据安全能力建设思路
3.1 数据安全能力建设目标
3.2 数据安全能力建设思路
3.3 数据安全能力建设框架
四、数据安全规划能力建设
4.1 业务场景识别
4.2 数据风险评估
4.3 数据分类分级
五、数据安全管理能力建设
5.1 构建组织机构
5.2 建立人员能力
5.3 制定制度流程
六、数据安全技术能力建设
6.1 数据安全采集
6.2 数据安全加密
6.3 数据访问控制
6.4 数据泄漏防护
6.5 数据安全脱敏
6.6 数据安全审计
6.8 数据安全销毁
七、数据安全运营能力建设
7.1 数据资产管控
7.2 安全策略执行
7.3 持续安全监控
7.4 应急响应恢复
7.5 人员能力培
八、总结
参考文献
`
Data Breach 数据泄露
https://www.cyberark.com/zh-hans/what-is/data-breach/
https://www.cyberark.com/what-is/data-breach/
`
数据泄露指恶意内部人士或外部攻击者未经授权访问机密数据或敏感信息,例如病历、财务信息或个人身份信息(PII)的安全事件。数据泄露是最常见且代价最高的网络安全事件之一。它们影响着各种规模、行业和地域的企业,并以惊人的频率发生。
# Data Breaches Come in a Variety of Flavors
(意外的网络/互联网暴露)Accidental Web/Internet Exposure where sensitive data or application credentials are accidentally placed in a location accessible from the web or on a public repository like GitHub.
(未授权访问)Unauthorized Access where bad actors exploit authentication and authorization control system vulnerabilities to gain access to IT systems and confidential data.
(敏感数据数据明文传输)Data on the Move where perpetrators access sensitive data transmitted in the clear using HTTP or other nonsecure protocols.
(员工错误/疏忽/处置不当/损失)Employee Error/Negligence/Improper Disposal/Loss where bad actors exploit weak or unenforced corporate security systems and practices or gain access to misplaced or improperly decommissioned devices.
(黑客/入侵)Hacking/Intrusion where an external attacker steals confidential data via phishing, malware, ransomware, skimming or some other exploit.
(内部盗窃)Insider Theft where a current or former employee or contractor gains access to confidential data for malicious purposes.
(实体盗窃)Physical Theft where data is extracted from stolen laptops, smartphones or tablets.
# Preventing and Mitigating Data Breaches
(特权访问安全)Privileged access security solutions to monitor and control access to privileged system accounts, which are often targeted by malicious insiders and external attackers.
(多因素验证)Multi-factor authentication solutions to strengthen identity management, prevent impersonation and reduce risks associated with lost or stolen devices or weak passwords.
(端点威胁检测和响应)Endpoint threat detection and response tools to automatically identify and mitigate malware, phishing, ransomware and other malicious activity that can lead to a data breach.
(最小权限管理)Least privilege management practices to tightly align access rights with roles and responsibilities so that no one has more access than they need to do their job. This helps reduce attack surfaces and contain the spread of certain types of malware that rely on elevated privileges.
`
数据安全的第一道坎
https://www.sec-un.org/%E6%95%B0%E6%8D%AE%E5%AE%89%E5%85%A8%E7%9A%84%E7%AC%AC%E4%B8%80%E9%81%93%E5%9D%8E/
`
“自下而上“的”套用“,多是基于现有的产品、解决方案、技术措施、管控流程等,寻找可以”套“进去的理论体系,来证明自己的可行性、先进性,是有理论指导实践的,再对应的做一些差距补齐。
”自上而下“的”沿用“,讲的是一个事情应该怎么想,应该怎么做,哪些可以做,哪些优先做,是一个逐层解构、逐项分工、滚动落地、持续改进的PDCA过程。这个过程中,理论体系的真正作用,更多是一个内部认可的统一方法论,而非一个功能、流程的映射表。
典型的就有:对IPDRR、CARTA、Kill Chain、ATT&CK、SA&O、ZeroTrust、DSMM等模型、框架、方法论的“套用“所引发的填词运动。还有就是各大会议上见到的,与真实情况有较大差距的各种框架图、概念图。
==
从企业架构(EA)来看,数据安全与传统的网络安全最大的不同,一是在于数据安全离业务更近,甚至绝大部分时候是跟业务强耦合的,安全要面对的已不再只是运维,而是开发、业务、法务、人事、行政…甚至是外部的合作伙伴和用户。二是在于数据安全的主体不再是底层的基础设施,而是在基础设施上存储、使用、流转的数据,数据海量、多样、变化、实时等特性让传统安全产品和工具的单点“蹲防“机制很难适应。
这两个因对象不同导致的核心不同点,决定了数据安全要做得好,必然是成体系、强内嵌、多关联、重流程、重协同、重运营的。在我看来,这是一个大前提,也应该是数据安全的整体指导思想。
==
因此,经过内部反复讨论,我们确定了数据安全管控的基本框架主要依托两个权威的通用模型:
一个是被教父(Xundi)戏称为“屌丝美眉“的DSMM(数据安全能力成熟度模型),以支撑我们对数据生命周期的阶段定义,和对应的能力分类。显而易见的,各阶段需要达到不同的能力,也需要不同的管控措施。当然,DSMM标准中也提到,有很多能力实际是需要贯穿数据生命周期始终的,是需要统筹考量、统一实现的通用能力。
另一个是NIST 提出的Cybersecurity Framework框架,即IPDRR(识别-保护-检测-响应-恢复)框架。IPDRR框架最大的优势是通用性和可扩展性。在这个框架基础上,我们根据自身做安全大运营(即统一运营)的需要做了变形,变成了EM-IPDRR(E是评价,M是管理),来支撑我们对在每个环节的实际能力的考察与匹配。
值得注意的是,EM-IPDRR各层之间的能力、数据是有一定的继承和关联关系的。举个例子,当你的某项资产识别并不能做到100%的准确和覆盖的时候,你的防护、检测,乃至响应、恢复,必然也会有错误和遗漏,而且会随着逐层的数据流转和处理造成的误差,逐步放大。到最后,基于IPDRR去做运营的管理和评价,必然会影响到最终的安全度量。
所以,真正的体系设计,需要考虑的是各层能力间的数据、流程的关联和交互该怎么做,哪些措施是继承前一层能力的,哪些措施是用来当作补偿措施用的。而不是画一个看似有道理的图就了事的。
借助DSMM和EM-IPDRR,我们做了一个自己的数据安全管控框架,用来定义整体层面的数据安全生命周期、需要管控的对象、需要考虑的管控手段,并逐步归纳我们自己的一套方法论去指导落地实践。而这两套框架的融合,自然而然地就形成了一个如下图所示的数据安全能力矩阵(我们自己简称为DSM,Data Security Matrix)。
在我们自己内部的讨论中,对识别的定义,以及识别的对象是什么,也是有过争论的。最终我们内部达成的一个初步共识,是把识别定义为需要做识别的数据资产“长什么样、从哪儿来、在哪儿存、到哪儿去、归谁来管”。这五块,我们认为是整个生命周期的数据资产识别的通用逻辑。
知易行难,难在落地
`