今天上午11点左右的时候在访问自己的网站时出现了502 Bad Gateway的错误,顿时有点慌(不会被黑了吧?虽然说我知道LNMP一键安装包在配置文件中的设置不是很安全,但也不至于这样吧?起码我装的是最新版的WordPress,而且没有装任何有漏洞的插件;并且在网站目录下面没有放什么敏感信息、备份等存在明显漏洞的文件;最后的最后,我也打算在这个周末抽出时间来设置/修改一下那几个可能存在问题的配置文件的(php.ini/nginx.conf等……),艹,先好好分析下原因吧,也不一定是被黑了,反正就网站无法正常访问这一点已经让我很生气了!)
错误截图:
以“外事绝不问百度,内事不问Google”的原则进行搜索(因为Google已经被墙了有好一段时间了,所以现在一般使用aol.com、yahoo.com和bing.com来替代Google搜索),这种错误其实碰到的人还是比较多的,所以很容易就找到相关网页:
nginx+php-fpm出现502 bad gateway错误解决方法 – 运维与架构 http://www.nginx.cn/102.html
Nginx 502 Bad Gateway错误的解决办法 – 峰雪 – 博客园 http://www.cnblogs.com/mybest/archive/2012/12/27/2836211.html
因为我是用lnmp一键安装包进行的安装,所以根据提示,先到对应的论坛上去找,看看有没有人也碰到过类似的情况,找到一个:
LNMP一键安装包的Nginx 502 Bad Gateway错误可能原因及解决方法 – LNMP一键安装包 http://lnmp.org/faq/lnmp-Nginx-502-Bad-Gateway.html
第一种原因:LNMP没有安装成功,脚本中某些lib包可能没有安装上,造成php没有编译安装成功。可以看一下是否存在/usr/local/php/sbin/php-fpm ,如果没有肯定没安装成功
解决方法:可以尝试根据lnmp一键安装包中的脚本手动安装一下,看看是什么错误导致的,在网上搜索一下,或者把错误信息发上来。如果实在不会提供按http://lnmp.org/install.html这个安装时的日志文件0.9版是在安装脚本所在目录文件名为lnmp.log,1.0是在/root/下名字为lnmp-install.log(可以用winscp登陆下载日志文件,压缩并上传到本论坛),没有错误信息我们没法说什么原因。(首先排除这一点,因为我的安装是成功的,而且blog已经运行好一阵了,所以不会因为这一点而导致502错误。)
第二种原因:
在php.ini里,eaccelerator配置项一定要放在Zend Optimizer配置之前,否则也可能引起502 Bad Gateway(putty连上去之后检查了,不是因为这个问题。)
第三种原因:
在安装好使用过程中出现502问题,一般是因为默认php-cgi进程是5个,可能因为phpcgi进程不够用而造成502,需要修改/usr/local/php/etc/php-fpm.conf 将其中的max_children值适当增加。
也有可能是max_requests值不够用。(先用命令检查php-cgi的连接进程个数,然后检查了文件内容,发现也不是这个原因引起的。)
第四种原因:
php执行超时,修改/usr/local/php/etc/php.ini 将max_execution_time 改为300(虽然里面的timeout设置确实为300,但我想应该不会是因为这点吧?先放放,看看有没有别的什么原因。)
第五种原因:
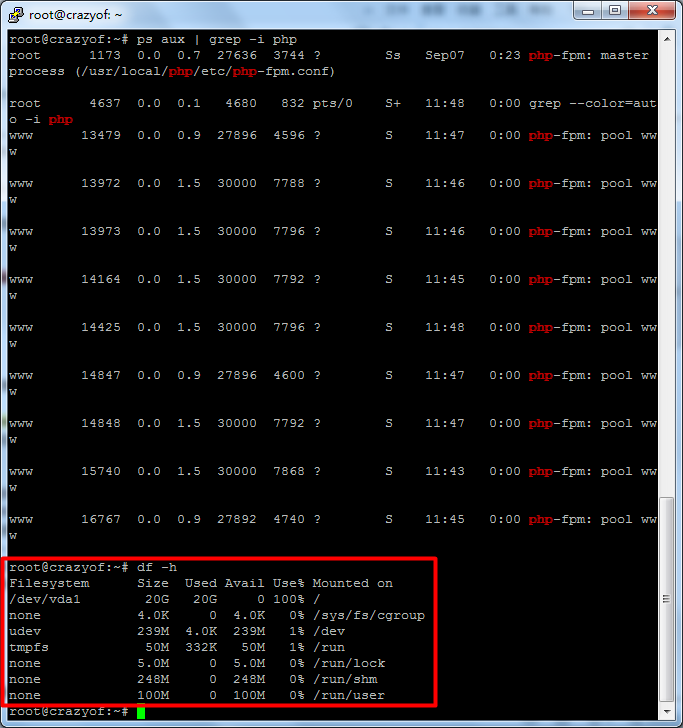
磁盘空间不足,如mysql日志占用大量空间清理一下磁盘上的文件,有部分剩余空间,重启即可恢复。(执行命令df -h一下,发现整个磁盘的空间已经没有了o(╯□╰)o 怎么能这样?还有这种攻击方法么?太高端了。)
附上命令结果&截图:
# df -h Filesystem Size Used Avail Use% Mounted on /dev/vda1 20G 20G 0 100% / none 4.0K 0 4.0K 0% /sys/fs/cgroup udev 239M 4.0K 239M 1% /dev tmpfs 50M 332K 50M 1% /run none 5.0M 0 5.0M 0% /run/lock none 248M 0 248M 0% /run/shm none 100M 0 100M 0% /run/user
第六种原因:
查看php-cgi进程是否在运行(ps aux | grep php-cgi)
第七种原因:
将nginx.conf里的
fastcgi_connect_timeout
fastcgi_send_timeout
fastcgi_read_timeout都调大一点。
第八种可能原因:http://bbs.vpser.net/thread-1654-1-1.html
九、也可以尝试将unix套接字改成tcp/ip的,修改/usr/local/php/etc/php-fpm.cnf 里设置<value name=“listen_address”>/tmp/nginx.socket</value> 改成<value name=“listen_address”>127.0.0.1:9000</value> ,同时/usr/local/nginx/conf/nginx.conf 及其/usr/local/nginx/conf/vhost/ 下面的虚拟主机配置里的fastcgi_pass unix:/tmp/php-cgi.sock; 替换为fastcgi_pass 127.0.0.1:9000; 之后重启试试。
十、如果虚拟主机的日志文件过大也可能会造成502问题。
建议定期清空一下虚拟主机的日志文件。
十一、有些程序或者程序的主题有死循环或其他非常占用资源的代码也可能会引起502,可以尝试暂时注释掉可能的主机的配置文件,重启看看是否还会502。
十二、如果以上方法都试过,但还有时会出现502错,可以尝试添加502自动重启脚本:http://bbs.vpser.net/thread-1913-1-1.html
然后查找Linux系统中的大文件,看看究竟是哪些内容把20G的空间都给我占满了:
方法一:
切换到根目录下(cd /),执行命令du(du -sk * | sort -nr | head -10)查看最占空间的10个目录/文件,然后进一步定位即可。
方法二:
使用find命令(find /search_dir -type f -size +3G)
查找过程如下:
# du -sh * | sort -nr | head -10 552K info_gather 344K bak_script 246M bak_data 118M tmp_bak 14M tools 13G log_backup 8.0K vhost.sh 8.0K sent 6.0M tmp 4.0K scripts_bak.sh # cd log_backup/ # ll total 13G drwxr-xr-x 2 root root 4.0K Sep 12 10:40 ./ drwx------ 14 root root 4.0K Sep 12 11:48 ../ -rw-r--r-- 1 root root 13G Sep 12 12:13 crontab_exec.log -rw-r--r-- 1 root root 57K Sep 2 05:00 crontab_exec.log.old
定位到了crontab_exec.log这个巨大的文件,艹,昨晚我就知道会出个问题,dropbox被封了之后(特别是在我的VPN还没有搭好之前,我也不放心去用shadowsocks或免费代理、改DNS等方法翻墙,然后输入用户名密码,太尼玛危险了,作为一个立志成为黑客大牛的我来说,这是不可容忍的,所以,我就没有进行下一步了,然后错误日志文件竟然会有这么多!!)
空间都被占满了,都无法编辑cron来禁止执行该任务了:
# crontab -e /tmp/crontab.jXyfcw/crontab: No space left on device
删除之:
~/log_backup# rm crontab_exec.log
但是为什么空间大小还是没有变呢?
~/log_backup# df -h Filesystem Size Used Avail Use% Mounted on /dev/vda1 20G 20G 0 100% / none 4.0K 0 4.0K 0% /sys/fs/cgroup udev 239M 4.0K 239M 1% /dev tmpfs 50M 332K 50M 1% /run none 5.0M 0 5.0M 0% /run/lock none 248M 0 248M 0% /run/shm none 100M 0 100M 0% /run/user root@hostName:~/log_backup# crontab -e /tmp/crontab.amBycX/crontab: No space left on device
明明已经删除了啊:
root@hostName:~/log_backup# ll total 2.1M drwxr-xr-x 2 root root 4.0K Sep 12 14:13 ./ drwx------ 14 root root 4.0K Sep 12 11:48 ../ -rw-r--r-- 1 root root 57K Sep 2 05:00 crontab_exec.log.old
继续搜索:
找到了篇说的很清楚的文章:linux删除文件后没有释放空间 – 冰刀(skate) – 博客频道 – CSDN.NET http://blog.csdn.net/wyzxg/article/details/4971843
在Linux系统上删除了文件之后没有释放空间
今天发现一台服务器的空间满了,于是要清空无用的文件,当我删除文件后,发现可用空间没有变化:
root@crazyof:~# df -h Filesystem Size Used Avail Use% Mounted on /dev/vda1 20G 20G 0 100% / none 4.0K 0 4.0K 0% /sys/fs/cgroup udev 239M 4.0K 239M 1% /dev tmpfs 50M 332K 50M 1% /run none 5.0M 0 5.0M 0% /run/lock none 248M 0 248M 0% /run/shm none 100M 0 100M 0% /run/user root@crazyof:~# pwd /root root@crazyof:~# du -sh * | sort -nr | head -10 552K info_gather 344K bak_script 246M bak_data 118M tmp_bak 14M tools 13G log_backup 8.0K vhost.sh 8.0K sent 6.0M tmp 4.0K scripts_bak.sh root@crazyof:~# cd log_backup/ root@crazyof:~/log_backup# ll total 13G drwxr-xr-x 2 root root 4.0K Sep 12 10:40 ./ drwx------ 14 root root 4.0K Sep 12 11:48 ../ -rw-r--r-- 1 root root 13G Sep 12 12:13 crontab_exec.log -rw-r--r-- 1 root root 57K Sep 2 05:00 crontab_exec.log.old root@crazyof:~/log_backup# crontab -e /tmp/crontab.jXyfcw/crontab: No space left on device root@crazyof:~/log_backup# rm crontab_exec.log root@crazyof:~/log_backup# df -h Filesystem Size Used Avail Use% Mounted on /dev/vda1 20G 20G 0 100% / none 4.0K 0 4.0K 0% /sys/fs/cgroup udev 239M 4.0K 239M 1% /dev tmpfs 50M 332K 50M 1% /run none 5.0M 0 5.0M 0% /run/lock none 248M 0 248M 0% /run/shm none 100M 0 100M 0% /run/user
未释放磁盘空间原因:
在Linux或者Unix系统中,通过rm或者文件管理器删除文件将会从文件系统的目录结构上解除链接(unlink)。然而如果文件是被打开的(有一个进程正在使用),那么进程将仍然可以读取该文件,磁盘空间也一直被占用。而我删除的是备份数据库/网站的脚本执行过程中的log文件,在删除的时候文件应该正在被crontab中指定的tee命令占用。
解决方法:
首先获得一个已经被删除但是仍然被应用程序占用的文件列表,如下所示:
# lsof | grep deleted php-fpm 1173 root 4u REG 253,1 0 1179951 /tmp/ZCUDK0heRV (deleted) php-fpm 17823 www 4u REG 253,1 0 1179951 /tmp/ZCUDK0heRV (deleted) php-fpm 17824 www 4u REG 253,1 0 1179951 /tmp/ZCUDK0heRV (deleted) php-fpm 17825 www 4u REG 253,1 0 1179951 /tmp/ZCUDK0heRV (deleted) cron 19896 root 5u REG 253,1 2147483647 1184733 /tmp/tmpfdN5k0J (deleted) sh 19897 root 1u REG 253,1 2147483647 1184733 /tmp/tmpfdN5k0J (deleted) sh 19897 root 2u REG 253,1 2147483647 1184733 /tmp/tmpfdN5k0J (deleted) tee 19899 root 1u REG 253,1 2147483647 1184733 /tmp/tmpfdN5k0J (deleted) tee 19899 root 2u REG 253,1 2147483647 1184733 /tmp/tmpfdN5k0J (deleted) tee 19899 root 3w REG 253,1 13797834752 292713 /root/log_backup/crontab_exec.log (deleted) php-fpm 22330 www 4u REG 253,1 0 1179951 /tmp/ZCUDK0heRV (deleted) php-fpm 26015 www 4u REG 253,1 0 1179951 /tmp/ZCUDK0heRV (deleted) php-fpm 27321 www 4u REG 253,1 0 1179951 /tmp/ZCUDK0heRV (deleted)
从输出结果可以看到该文件还在被tee命令使用,未被释放空间。
如何让进程释放呢?
一种非常直接的方法就是kill掉相应的进程,或者停掉使用这个文件的应用,让os自动回收磁盘空间。
于是:
# kill -9 19899
然后,一切就OK了:
# df -h Filesystem Size Used Avail Use% Mounted on /dev/vda1 20G 6.8G 12G 37% / none 4.0K 0 4.0K 0% /sys/fs/cgroup udev 239M 4.0K 239M 1% /dev tmpfs 50M 332K 50M 1% /run none 5.0M 0 5.0M 0% /run/lock none 248M 0 248M 0% /run/shm none 100M 0 100M 0% /run/user
参考链接:
- Nginx 502 Bad Gateway – 必应
- nginx 502 bad gateway timeout – 运维与架构
- nginx 502 Bad Gateway 错误解决办法
- nginx+php-fpm出现502 bad gateway错误解决方法
- Nginx 502 Bad Gateway错误的解决办法 – 峰雪
- LNMP一键安装包的Nginx 502 Bad Gateway错误可能原因及解决方法 – LNMP一键安装包
- linux删除文件后没有释放空间 – 冰刀(skate)
- linux 磁盘空间查看之大文件查寻 – Linux/Unix
待参考文档:
《 “Nginx 502 Bad Gateway error” 》 有 3 条评论
Nginx一次奇怪的502 报错探究
https://mp.weixin.qq.com/s/_6GWNojX0hAvupX906nhwQ
PHP-FPM 调优:为了高性能使用 pm static
https://www.phpyc.com/php-fpm-tuning-using-pm-static-max-performance/
https://www.sitepoint.com/php-fpm-tuning-using-pm-static-max-performance/
Nginx常见故障502等解决方案汇总
http://www.phpxs.com/post/6267/
`
常见的Nginx 502 Bad Gateway解决办法如下:
Nginx 502错误情况1:
网站的访问量大,而php-cgi的进程数偏少。
针对这种情况的502错误,只需增加php-cgi的进程数。具体就是修改/usr/local/php/etc/php-fpm.conf 文件,将其中的max_children值适当增加。这个数据要依据你的VPS或独立服务器的配置进行设置。一般一个php-cgi进程占20M内存,你可以自己计算下,适量增多。
Nginx 502错误情况2:
CPU占用率、内存占用率非常高,遭到CC攻击。
Nginx 502错误情况3:
CPU占用率不高,内存溢出。
检查一下网站程序有没有问题?一般小偷站点常常会出现内存溢出。
检查一下/var/log/目录下的日志,看看是不是有人爆破SSH和FTP端口?
SSH、FTP遭到穷举也会占用大量内存。是的话改掉SSH端口和FTP端口即可。
将网上找到的一些和502 Bad Gateway错误有关的问题和排查方法列一下,先从FastCGI配置入手:
1.查看FastCGI进程是否已经启动
2.检查系统Fastcgi进程运行情况
3.FastCGI执行时间过长
4.头部太大
5.https转发配置错误
6.max-children和max-requests
7.增加缓冲区容量大小
8.request_terminate_timeout
`