最近重温了awk和sed等编辑命令,也常用Vim进行文本的查看,学到了很多的实用技巧,记录一下:
Vim的一些技巧
浏览代码 :E
注意,是大写。之后,你可以用 j, k 键上下移动,然后回车,进入一个目录,或是找开一个文件。你可以看到上面有一堆命令:
- 【 – 】 到上级目录
- 【D】删除文件(大写)
- 【R】改文件名(大写)
- 【s】对文件排序(小写)
- 【x】执行文件
当然,打开的文件会把现有已打开的文件给冲掉——也就是说你只看到了一个文件。如果你要改变当前浏览的目录,或是查看当前浏览的目录,你可以使用和shell一样的命令:
:cd <dir> – 改变当前目录
:pwd – 查看当前目录
缓冲区 :ls
于是,在你的Vim下,你会看到如下界面:
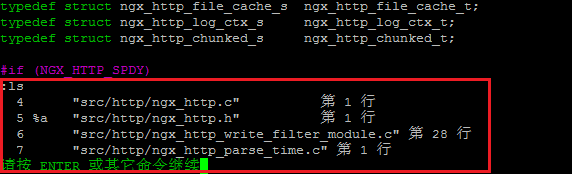
你可以看到Vim打开了四个文件,编号是4,5,6,7,如果你要切换打开的文件,这个时候,你不要按回车(按了也没事,只不过按了就看不到:ls输出的buffer列表了),你可以使用下面的命令切换文件(buffer后面的4表示切到4号文件也就是src/http/ngx_http.c):
:buffer 4
或是:
:buffer src/http/ngx_http.c
注意:
- 你可以像在Shell中输入命令按Tab键补全一样补全Vim的命令。
- 也可以用像gdb一样用最前面的几个字符,只要没有冲突。如:buff
你还可以动用如下命令,快速切换:
:bnext 缩写 :bn
:bprevious 缩写 :bp
:blast 缩写 :bl
:bfirst 缩写 :bf
上图中,我们还可以看到5有一个%a,这表示当前文件,相关的标记如下:
– (非活动的缓冲区)
a (当前被激活缓冲区)
h (隐藏的缓冲区)
% (当前的缓冲区)
# (交换缓冲区)
= (只读缓冲区)
+ (已经更改的缓冲区)
窗口分屏浏览
相信你在《Vim的窗口分屏》一文中,你已经知道了怎么拆分窗口了。其实,我更多的不是用拆分窗口的命令,而是用浏览文件的命令来分隔窗口。如:
把当前窗口上下分屏,并在下面进行目录浏览:
:He 全称为 :Hexplore (在下边分屏浏览目录)
如果你要在上面,你就在 :He后面加个 !,
:He! (在上分屏浏览目录)
如果你要左右分屏的话,你可以这样:
:Ve 全称为 :Vexplore (在左边分屏间浏览目录,要在右边则是 :Ve!)
Tab页浏览
分屏可能会让你不爽,你可能更喜欢像Chrome这样的分页式的浏览,那么你可以用下面的命令:
:Te 全称是 :Texplorer
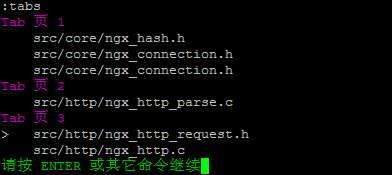
下图中,你可以看到我用Te命令打开了三页,就在顶端我们可以可以看到有三页,其中第一页Tab上的数字3表示那一页有3个文件。
我们要在多个Tabe页中切换,在normal模式下,你可以使用下面三个按键(注意没有冒号):
gt – 到下一个页
gT – 到前一个页
{i} gt – i是数字,到指定页,比如:5 gt 就是到第5页
你可以以使用 【:tabm {n}】来切换Tab页。
gvim应该是:Ctrl+PgDn 和 Ctrl+PgUp 来在各个页中切换。
如果你想看看你现在打开的窗口和Tab的情况,你可以使用下面的命令:
:tabs
于是你可以看到:
其它的一些技巧
字符相关
【guu 】 – 把一行的文字变成全小写。或是【Vu】
【gUU】 – 把一行的文件变成全大写。或是【VU】
按【v】键进入选择模式,然后移动光标选择你要的文本,按【u】转小写,按【U】转大写
【ga】 – 查看光标处字符的ascii码
【g8】 – 查看光标处字符的utf-8编码
【gf】 – 打开光标处所指的文件 (这个命令在打到#include头文件时挺好用的,当然,仅限于有路径的)
【*】或【#】在当前文件中搜索当前光标的单词
缩进相关
【>>】向右缩进当前行 【<<】向左缩进当前行
【=】 – 缩进当前行 (和上面不一样的是,它会对齐缩进)
【=%】 – 把光标位置移到语句块的括号上,然后按=%,缩进整个语句块(%是括号匹配)
【G=gg】 或是 【gg=G】 – 缩进整个文件(G是到文件结尾,gg是到文件开头)
复制粘贴相关
按【v】 键进入选择模式,然后按h,j,k,l移动光标,选择文本,然后按 【y】 进行复制,按 【p】 进行粘贴。
【dd】剪切一行(前面加个数字可以剪切n行),【p】粘贴
【yy】复制一行(前面加个数字可以复制n行),【p】粘贴
光标移动相关
【Ctrl + O】向后回退你的光标移动
【Ctrl + I 】向前追赶你的光标移动
这两个快捷键很有用,可以在Tab页和Windows中向前和向后trace你的光标键,这也方便你跳转光标。
读取Shell命令相关
【:r!date】 插入日期
上面这个命令,:r 是:read的缩写,!是表明要运行一个shell命令,意思是我要把shell命令的输出读到vim里来。
超牛逼/实用的awk技巧
一些注意事项/预备知识:
- 在单引号中的被大括号括着的就是awk的语句,注意,其只能被单引号包含。
- 其中的$1..$n表示第几列。注:$0表示整个行。
在进行一些稍微复杂点的awk使用时,经常会碰到END关键字。END的意思是“处理完所有的行的标识”,即然说到了END就有必要介绍一下BEGIN,这两个关键字意味着执行前和执行后的意思,语法如下:
- BEGIN{ 这里面放的是执行前的语句 }
- END {这里面放的是处理完所有的行后要执行的语句 }
- {这里面放的是处理每一行时要执行的语句}
用awk来过滤记录:
$ awk '$3==0 && $6=="LISTEN" ' netstat.txt
其中的“==”为比较运算符。其他比较运算符:!=, >, <, >=, <=
$ awk ' $3>0 {print $0}' netstat.txt
Proto Recv-Q Send-Q Local-Address Foreign-Address State
tcp 0 4166 coolshell.cn:80 61.148.242.38:30901 ESTABLISHED
tcp 0 1 coolshell.cn:80 124.152.181.209:26825 FIN_WAIT1
tcp 0 1 coolshell.cn:80 208.115.113.92:50601 LAST_ACK
如果我们需要表头的话,我们可以引入内建变量NR:
$ awk '$3==0 && $6=="LISTEN" || NR==1 ' netstat.txt Proto Recv-Q Send-Q Local-Address Foreign-Address State tcp 0 0 0.0.0.0:3306 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN
awk的内建变量:
| $0 | 当前记录(这个变量中存放着整个行的内容) |
| $1~$n | 当前记录的第n个字段,字段间由FS分隔 |
| FS | 输入字段分隔符 默认是空格或Tab |
| NF | 当前记录中的字段个数,就是有多少列 |
| NR | 已经读出的记录数,就是行号,从1开始,如果有多个文件话,这个值也是不断累加中。 |
| FNR | 当前记录数,与NR不同的是,这个值会是各个文件自己的行号 |
| RS | 输入的记录分隔符, 默认为换行符 |
| OFS | 输出字段分隔符, 默认也是空格 |
| ORS | 输出的记录分隔符,默认为换行符 |
| FILENAME | 当前输入文件的名字 |
# awk调用外部变量是需要用“单引号”括起来。或者在前面用 -v 选项添加这个外部变量。
# awk '{if($1>='$n') print $2}' file
折分文件
awk拆分文件很简单,使用重定向就好了。下面这个例子,是按第6例分隔文件,相当的简单(其中的NR!=1表示不处理表头)。
$ awk 'NR!=1{print > $6}' netstat.txt
统计
下面的命令计算所有的C文件,CPP文件和H文件的文件大小总和。
$ ls -l *.cpp *.c *.h | awk '{sum+=$5} END {print sum}'
2511401
#!/bin/sh
for i in {1..100}; do
echo $i
done
#生成复杂密码
openssl rand 20 -base64 uuidgen
#Vim
:w !sudo tee %
#统计某一文件夹(包括子文件夹下)的文件个数
#方法一: ls -lR | grep "^-" | wc -l #方法二: find ./ -type f | wc -l
去掉文件中的utf-8 BOM头
awk '{if(NR==1)sub(/^xefxbbxbf/,"") print}' input.txt > output.txt
比较两个文件,找出在1.txt中不在2.txt中的内容
awk 'NR==FNR{a[$0]++}NR>FNR{if(a[$0]==0) print}' 1.txt 2.txt > diff.txt
《 “Linux技巧学习2” 》 有 6 条评论
#生成复杂密码
`
genpasswd() {
local l=$1
[ “$l” == “” ] && l=20
tr -dc A-Za-z0-9_ < /dev/urandom | head -c ${l} | xargs
}
genpasswd 16
`
Linux下快速生成随机复杂密码(以16位长度为例)
`
# openssl rand 16 -base64 # -base64 参数用于确保生成的密码可以被键盘敲出来
# gpg –gen-random –armor 1 16 # 生成 1 个长度为 16 个字符的高强度密码
# uuidgen | tr ‘-‘ ‘_’ | head -c16
`
模拟百万级TCP并发
http://mp.weixin.qq.com/s?__biz=MzIxMjAzMDA1MQ==&mid=2648945745&idx=1&sn=422c7dd658ba83a42f5753669716378f#rd
10个高效Linux技巧及Vim命令对比
https://vimjc.com/linux-vim-tricks.html
`
(1) :Linux 命令行下执行该命令,将光标移动到行首 (a 是 ahead 的缩写)
(2) :Linux 命令行下执行该命令,将光标移动到行尾 (e 是 end 的缩写)
(3) :Linux 命令行下执行该命令,会进入历史命令查找窗口,输入要查找的命令可快速选择历史命令
(4) :Linux 命令行下执行该命令,会删除当前光标附近的一个词 (以空格隔开的字符串)
(5) :Linux 命令行下执行该命令,会删除命令行上已经敲出来的所有文本 (即删除整行)
(6) :Linux 命令行下执行该命令,将粘贴 、 等命令删除的文本
(7) !xx关键字:Linux 命令行下执行该命令,会执行最近一条包含有 xx关键字 的历史命令
(8) cd -:Linux 命令行下执行该命令,会将当前目录切换到上一次所在目录
(9) :Linux 命令行下执行该命令,可粘贴复制到系统剪切板上的内容
(10) :Linux 命令行下执行该命令,可清空当前屏幕
`
30个Vim常用命令和使用技巧整理 (长期更新)
https://vimjc.com/vim-tips.html
https://unix.stackexchange.com/questions/498001/splitting-file-by-1st-column-too-many-open-files
`
# 用AWK拆分文件的报错 too many open files
# 正解,报错之所以出现,是因为AWK根据输入数据创建的名称,而如果数据数据的行数过多,则会为每一行都创建文件,因此这里需要用数组的方式减少需要创建的文件数量,即可避免报错,同时也要记得及时关闭文件。
awk ‘NR!=1 { if(a[f=$1″.txt”]++) print >> f; else print > f; close(f) }’ input_content.txt
`
https://stackoverflow.com/questions/32878146/too-many-open-files-error-while-running-awk-command
https://askubuntu.com/questions/1086543/awk-cannot-open-filename-for-output-too-many-open-files
https://www.unix.com/shell-programming-and-scripting/276564-awk-too-many-open-files.html