1.用Python生成成随机字符串
搜索关键字:
import random, string
''.join(random.choice(string.ascii_uppercase + string.digits) for _ in range(N))
''.join(random.SystemRandom().choice(string.ascii_uppercase + string.digits) for _ in range(N)) # more secure
import string
import random
def id_generator(size=6, chars=string.ascii_uppercase + string.digits):
return ''.join(random.choice(chars) for _ in range(size))
id_generator()
id_generator(3, "6793YUIO")
import uuid; str(uuid.uuid4().get_hex().upper()[0:6])
用的是random.choice()方法
参考链接:
- http://stackoverflow.com/questions/2257441/random-string-generation-with-upper-case-letters-and-digits-in-python
- http://stackoverflow.com/questions/18319101/whats-the-best-way-to-generate-random-strings-of-a-specific-length-in-python
- http://stackoverflow.com/questions/306400/how-do-i-randomly-select-an-item-from-a-list-using-python
- http://stackoverflow.com/questions/41107/how-to-generate-a-random-alpha-numeric-string #Java版
2.如何用Python均分一个列表?
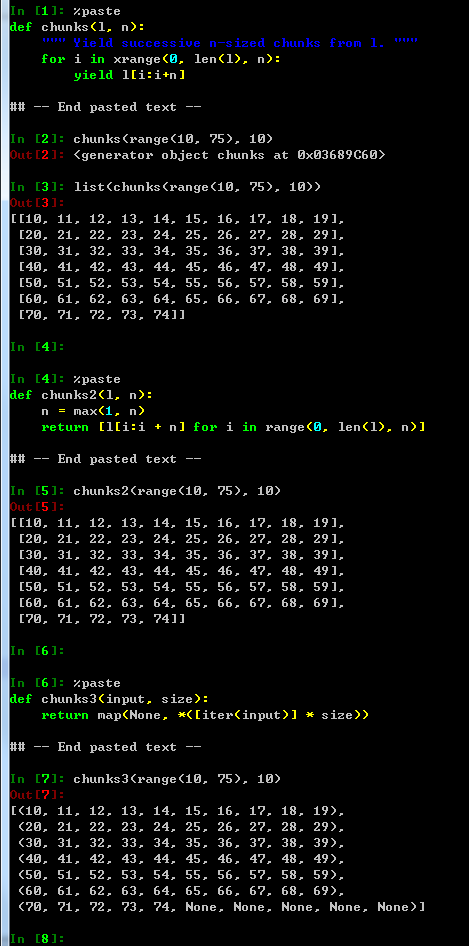
def chunks(l, n):
""" Yield successive n-sized chunks from l. """
for i in xrange(0, len(l), n):
yield l[i:i+n]
import pprint
pprint.pprint(list(chunks(range(10, 75), 10)))
#
def chunks2(l, n):
n = max(1, n)
return [l[i:i + n] for i in range(0, len(l), n)]
chunks2(range(10, 75), 10)
#
def chunks3(input, size):
return map(None, *([iter(input)] * size))
chunks3(range(10, 75), 10)
#
l = range(10, 75)
chunks4 = lambda l, n: [l[x: x+n] for x in xrange(0, len(l), n)]
chunks4(l, 10)
参考链接:
- http://stackoverflow.com/questions/312443/how-do-you-split-a-list-into-evenly-sized-chunks-in-python #Nice
3.如何用Python初始化指定长度的列表?
list_1 = [0] * 10 #[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
list_2 = [{} for _ in range(10)]
参考链接:
4.用Python生成指定范围内固定长度的列表
搜索关键字:
推荐方法:
random.sample
不推荐使用random.randint
import random
random.sample(range(30), 4)
import random
[random.randrange(1, 10) for _ in range(0, 4)]
import timeit
import numpy.random as nprnd
t1 = timeit.Timer('[random.randint(0,1000) for r in xrange(10000)]','import random') # v1
t2 = timeit.Timer('random.sample(range(10000), 10000)','import random') # v2(change v2 so that it picks numbers in (0,10000) and thus runs...)
t3 = timeit.Timer('nprnd.randint(1000, size=10000)','import numpy.random as nprnd') # v3
print t1.timeit(1000)/1000
print t2.timeit(1000)/1000
print t3.timeit(1000)/1000
参考链接:
- http://stackoverflow.com/questions/4172131/create-random-list-of-integers-in-python
- http://stackoverflow.com/questions/3559337/how-in-python-to-generate-a-random-list-of-fixed-length-of-values-from-given-ran
5.Python中的字符串查找效率和正则查找的对比
搜索关键字:
参考结论:
使用in关键字是最快的;正则查找是最慢的。
from timeit import timeit
import re
def find(string, text):
if string.find(text) > -1:
pass
def re_find(string, text):
if re.match(text, string):
pass
def best_find(string, text):
if text in string:
pass
print timeit("find(string, text)", "from __main__ import find; string='lookforme'; text='look'")
print timeit("re_find(string, text)", "from __main__ import re_find; string='lookforme'; text='look'")
print timeit("best_find(string, text)", "from __main__ import best_find; string='lookforme'; text='look'")
参考链接:
- http://stackoverflow.com/questions/4901523/whats-a-faster-operation-re-match-search-or-str-find
- https://docs.python.org/2/howto/regex.html
- https://docs.python.org/2/library/re.html
6.在Python中使用正则是否需要先compile呢?
参考结论:
如果需要进行大量/多次搜索的话,先compile的效率要高得多!
参考链接:
- http://stackoverflow.com/questions/452104/is-it-worth-using-pythons-re-compile #Nice
- http://stackoverflow.com/questions/14756790/why-are-uncompiled-repeatedly-used-regexes-so-much-slower-in-python-3 #Good
- http://stackoverflow.com/questions/9684899/doing-multiple-successive-regex-replacements-in-python-inefficient
7.Python中search和match的区别
参考结论:
Python offers two different primitive operations based on regular expressions: match checks for a match only at the beginning of the string, while search checks for a match anywhere in the string (this is what Perl does by default).
Note that match may differ from search even when using a regular expression beginning with ‘^’: ‘^’ matches only at the start of the string, or in MULTILINE mode also immediately following a newline. The “match” operation succeeds only if the pattern matches at the start of the string regardless of mode, or at the starting position given by the optional pos argument regardless of whether a newline precedes it.
- search => find something anywhere in the string and return a match object.
- match => find something at the beginning of the string and return a match object.
《“Python的一些小知识点_9”》 有 1 条评论
Awesome Python – Python 优秀资源收集
https://awesome-python.com/