今天在网上随意搜索正则表达式的相关知识时,看到了余晟大牛的blog中的一篇2010年的文章——正则表达式的与或非,学到了不少知识,在此记录一下(因为内容一次学不完,所以会不定期更新后面学到的知识和感想)。
与
正则表达式表达“与”关系非常简单,直接连续写出相继出现的元素就可以。而且“与”关系也不限于字符之间,任何子表达式都可以用它来连接。
或
“或”是正则表达式灵活性的重要体现,我们可以规定某个位置的文本的“多种可能”,比如要匹配cat或是cut,在正则表达式看来,就是“字符c,然后是a或u,然后是t”。
如果“或”的多种可能都是单个字符,就可以用字符组来表达“或”的关系;
更复杂的情况是“或”的多种可能,并非都是单个字符,有些可能是多个字符,遇到这种情况,就不应使用字符组,而应当使用多选分支『(…|…)』,将各个“可能选项”列在多选分支中。
关于多选分支,还有两点要补充:
- 多选分支也可用于“每个选择都是单个字符”的情况,比如『c[au]t』写成『c(a|u)t』是没错的,但字符组的效率要远高于多选分支,所以,在这种情况下,推荐使用字符组『c[au]t』;
- 默认的多选分支『(…|…)』使用的括号是会捕获文本的,也就是说,括号内的表达式真正匹配成功的文本会记录下来,匹配完成之后可以提取出来。但许多时候,我们需要的只是整个表达式的匹配,而不关心“匹配时到底选择的哪种可能情况”,在这种情况下,我们稍加修改,使用“不捕获文本的括号”,可以提高效率。不捕获文本的写法也很简单,只是在开扩号之后加上字符『?:』,也就是『(?:…|…)』。这样做虽然繁琐点,但效率有保障,阅读起来也不困难,我推荐养成这种习惯,只要用到了括号,就想想是否真的要捕获括号内表达式匹配的文本,如果不需要,就是用不捕获文本的括号。
非
“非”看起来简单,其实是最复杂的,我这里就只分2类了,详细、具体的内容还需要去余晟大牛的blog中看原文:
首先讨论针对字符的“非”:不容许出现某个或某几个字符。这是最简单的情况,直接用排除型字符组就可以对付;
其次是针对字符串/单词的“非”,因为正则表达式并没有提供与多选分支对应的“否定”结构,所以解决的办法是依靠否定顺序环视。
参考链接:
==

&
==
《 “由“正则表达式中的与或非”想到的” 》 有 9 条评论
`
非捕获
(?:pattern)
所在位置右侧不能匹配pattern
(?!pattern)
所在位置左侧不能匹配pattern
(?<!pattern)
不包含字符串
(?:(?!(ixyzero.com|crazyof.com|iixyzero.com)))
(?:(?!(ixyzero.com|crazyof.com|iixyzero.com)).)*
^((?!cat).)*$
^(?:(?!cat).)*$
`
正则表达式中的不匹配
`
/^((?!PART).)*$/ #匹配不包含字符串 PART 的行
/^(?!PART)/ #匹配不以字符串 PART 开头的行
`
http://www.luanxiang.org/blog/archives/1065.html #详细解释
http://stackoverflow.com/questions/6259443/how-to-match-a-line-not-containing-a-word #详细解释
http://stackoverflow.com/questions/1971738/regex-for-all-strings-not-containing-a-string
http://stackoverflow.com/questions/406230/regular-expression-to-match-line-that-doesnt-contain-a-word
http://stackoverflow.com/questions/4660818/antimatch-with-regex
http://stackoverflow.com/questions/2953039/regular-expression-for-a-string-containing-one-word-but-not-another
http://stackoverflow.com/questions/717644/regular-expression-that-doesnt-contain-certain-string
http://www.isnowfy.com/regular-expression-negative/
利用正则表达式排除特定字符串
http://www.cnblogs.com/wangqiguo/archive/2012/05/08/2486548.html
`
查找不以baidu开头的字符串 #正则 ^(?!baidu).+$
查找以com结尾的字符串 #正则 ^.*?(?<=com)$
查找以com结尾的字符串 #正则 ^.*?com$
查找不以com结尾的字符串 #正则 ^.*?(?<!com)$
查找不含有if的行 #正则 ^([^f]|[^i]f)+$
排除不含有某字符串的最终方案 #正则 ^(?!.*helloworld).*$
排除不含有某字符串的最终方案 #正则 ^((?!helloworld).)*$ (但效率没有上面那个高)
`
正则表达式,匹配(去除)相关HTML标签
https://bemzuo.com/program/%E6%AD%A3%E5%88%99%E8%A1%A8%E8%BE%BE%E5%BC%8F%EF%BC%8C%E5%8E%BB%E9%99%A4%E6%89%80%E6%9C%89html%E6%A0%87%E7%AD%BE.html
`
]*> //匹配所有的标签
]?>.? //匹配所有脚本
]*> //匹配所有图片
//匹配去除Br之外的所有的标签。。(可以用在 去除所有标签,只剩br),同理br可换为其他任意标签
]?>.? //匹配table里面的所有内容
//匹配所有标签,只剩img,br,p
`
判断一行中不包含特定关键字的正则表达式(Regular expression to match a line that doesn’t contain a word?)
https://stackoverflow.com/questions/406230/regular-expression-to-match-a-line-that-doesnt-contain-a-word
`
^((?!hede).)*$
`
表示一行中不包含特定字符串的正则表达式(Regex matching line not containing the string)
https://superuser.com/questions/1279062/regex-matching-line-not-containing-the-string
`
^((?!SCREEN).)*$
`
正则表达式里字符串”不包含”匹配技巧
http://www.aqee.net/post/regular-expression-to-match-string-not-containing-a-word.html
`
查找不包含 hede 字符串的行:
^((?!hede).)*$
在上面的例子里,每个空字符都会检查其前面的字符串是否不是’hede’,如果不是,这.(点号)就是匹配捕捉这个字符。表达式(?!hede).只执行一次,所以,我们将这个表达式用括号包裹成组(group),然后用*(星号)修饰——匹配0次或多次:((?!hede).)*。
你可以理解,正则表达式((?!hede).)*匹配字符串”ABhedeCD”的结果false,因为在e3位置,(?!hede)匹配不合格,它之前有”hede”字符串,也就是包含了指定的字符串。
在正则表达式里, ?! 是否定式向前查找,它帮我们解决了字符串“不包含”匹配的问题。
`
https://stackoverflow.com/questions/406230/regular-expression-to-match-a-line-that-doesnt-contain-a-word
正则表达式里”不包含”及一些特殊查找
https://www.jianshu.com/p/9fd05dfdde48
不包含字符串abc的正则表达式
https://blog.csdn.net/xxd851116/article/details/7576624
距离弄懂正则的环视,你只差这一篇文章
https://mp.weixin.qq.com/s/VqiZ6fVL20sJ8NUoQJjm2g
`
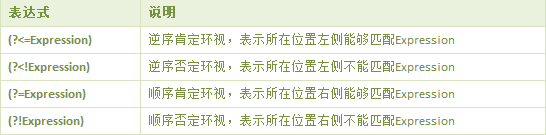
# 正则表达式的环视是什么
环视顾名思义就是「环顾四周,向左看看向看看,找一个合适的位置」。环视「匹配的是一个位置而不是字符,这点尤为重要。」
首先解释一下什么是「顺序环视」,什么是「逆序环视」。因为正则表达式的匹配过程是从左到右的,所以如果我们要「判断一个位置的右边满不满足某个条件,这就叫顺序环视」。如果我们「判断一个位置的左边满不满足某种条件的话,这就叫做逆序环视。」
你可能会觉得上面这个正则表达式有点难记,首先我们需要知道「环视都是以(?作为开头的,然后接下来的一到两个符号表明是那种环视,再然后就是需要满足的条件,最后是一个)表示结束。(?=条件)可以这样理解,?表示疑问,=表示是否满足匹配。也就是当前位置是否满足给出的条件。」
肯定的顺序环视 -> (?=李四)
否定的顺序环视 -> (?!李四)
肯定的逆序环视 -> (? (? (?<=\d)(?=(\d{3})+$)
`
[…] 由“正则表达式中的与或非”想到的https://ixyzero.com/blog/archives/2059.html […]
[…] 由“正则表达式中的与或非”想到的https://ixyzero.com/blog/archives/2059.html […]