=Start=
缘由:
工作、学习需要。
参考解答:
在进程的创建上Unix采用了一个独特的方法,它将进程创建与加载一个新进程映象分离。这样的好处是有更多的余地对两种操作进行管理。当我们创建了一个进程之后,通常将子进程替换成新的进程映象,这可以用exec系列的函数来进行。当然,exec系列的函数也可以将当前进程替换掉。例如:在shell命令行执行ps命令,实际上是shell进程调用fork复制一个新的子进程,再利用exec系统调用将新产生的子进程完全替换成ps进程。
因为exec系列函数并不创建任何新进程,所以前后的进程ID没有发生任何改变,exec所做的就是替换当前进程的正文段、数据、堆和栈段。 exec系列函数包括:
int execl(const char* pathname, const char* arg0, ...); // end with NULL int execv(const char* pathname, char* const argv[]); // end with NULL int execle(const char* pathname, const char* arg0, ...); // end with NULL and char* const envp[] int execve(const char* pathname, char* const argv[], char* const envp); // exec系列函数中唯一的系统调用(其它的只是库函数,最终都要调用execve) int execlp(const char* filename, const char* arg0, ...); // end with NULL int execvp(const char* filename, char* const argv[]); // end with NULL // 这6个函数的返回值:若出错则返回-1,若成功则不返回值 // l -> list 「l和v互斥」 // v -> vector 「l和v互斥」 // p -> path // e -> env
这6个exec函数的参数很难记忆。函数名中的字符会给我们一些帮助:字母p表示该函数取filename作为参数,并且用PATH环境变量寻找可执行文件;字母l表示该函数取一个参数表,它与字母v互斥;字母v表示该函数取一个argv[]矢量;最后,字母e表示该函数取envp[]数组,而不使用当前环境。上面6个函数中只有execve是内核的系统调用,其它的5个只是库函数,最终都要调用该系统调用,它们之间的关系如下图:
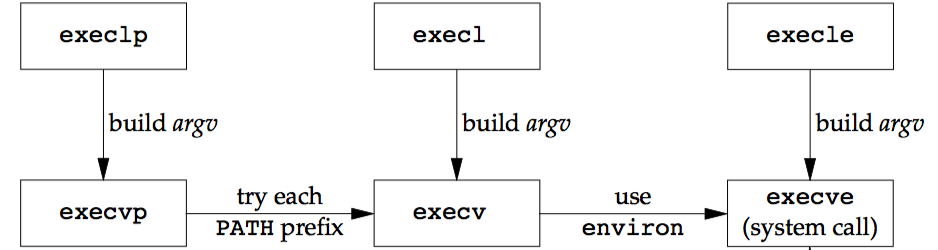
以e结尾的两个函数(execle和execve)可以传递一个指向环境字符串指针数组的指针。其他四个函数则使用调用进程中的environ变量为新程序复制现有的环境。
exec 如果传入的是 filename,那么:
- 如果包含 /,那么认为这是一个路径名 pathname;否则在 PATH 环境变量里查找到第一个可执行文件
- 如果可执行文件不是链接器产生的,那么认为是一个 shell 文件,使用 /bin/sh 执行
执行 exec 函数,下面属性是不发生变化的:
- 进程 ID 和父进程 ID
- 实际用户 ID 和实际组 ID
- 附加组 ID
- 会话 ID
- 控制终端
- 闹钟余留时间
- 当前工作目录
- 根目录
- umask
- 文件锁
- 进程信号屏蔽
- 未处理信号
- 资源限制
- 进程时间
而下面属性是发生变化的:
- 文件描述符如果存在 close-on-exec 标记,那么会关闭
- 可执行程序存在设置用户 ID 和组 ID 位,那么有效用户 ID 和组 ID 会发生变化
参考链接:
- linux系统编程之进程(五):exec系列函数(execl,execlp,execle,execv,execvp)使用
- Linux c进程管理—创建进程 system、execl、execlp、fork
- http://linux.die.net/man/3/execl
- …
- http://linux.die.net/man/3/execve
- http://linux.die.net/man/2/execve
- http://wuleying.github.io/books/apue/s8/8.5.html
- http://dirtysalt.info/apue.html
- 进程控制之exec函数
- 系统调用跟我学(3)
- 《APUE》读书笔记—第八章进程控制
- [单刷APUE系列]第八章——进程控制[2]
- APUE — Process Control
- exec函数族的作用与讲解
=END=
《 “Linux进程控制之exec函数族” 》 有 22 条评论
Hooking Android 系统调用
https://www.vantagepoint.sg/blog/82-hooking-android-system-calls-for-pleasure-and-benefit
linux系统调用和库函数调用的区别
http://www.cnblogs.com/yanlingyin/archive/2012/04/23/2466141.html
Linux系统调用列表
http://www.ibm.com/developerworks/cn/linux/kernel/syscall/part1/appendix.html
Linux系统调用和库函数调用
http://blog.csdn.net/xifeijian/article/details/9081259
系统调用和库函数有什么区别?
https://www.zhihu.com/question/19930018
`
所有的操作系统都提供多种服务的入口点,程序由此向内核请求服务。各种版本的UNIX实现都提供定义明确、数量有限、可直接进入内核的入口点,这些入口点被称为「系统调用」。
####
系统调用通常用于底层文件访问(low-level file access),例如在驱动程序中对设备文件的直接访问。
系统调用是操作系统相关的,因此一般没有跨操作系统的可移植性。
系统调用发生在内核空间,因此如果在用户空间的一般应用程序中使用系统调用来进行文件操作,会有用户空间到内核空间切换的开销。事实上,即使在用户空间使用库函数来对文件进行操作,因为文件总是存在于存储介质上,因此不管是读写操作,都是对硬件(存储器)的操作,都必然会引起系统调用。也就是说,库函数对文件的操作实际上是通过系统调用来实现的。例如C库函数fwrite()就是通过write()系统调用来实现的。
系统调用和普通库函数调用非常相似,只是系统调用由操作系统内核提供,运行于内核态,而普通的库函数调用由函数库或用户自己提供,运行于用户态。
##
库函数调用是系统无关的,因此可移植性好。
##
系统调用和库函数两者的关系——调用库函数是为了使用系统调用。 Linux几乎库函数和系统调用一一对应。Windows则不然。
`
Linux系统调用权威指南
http://www.csyssec.org/20161231/systemcallinternal/
http://blog.packagecloud.io/eng/2016/04/05/the-definitive-guide-to-linux-system-calls/#bit-fast-system-calls
How does kernel get an executable binary file running under linux?(Linux下内核是如何让一个可执行文件运行起来的?)
http://stackoverflow.com/questions/8352535/how-does-kernel-get-an-executable-binary-file-running-under-linux/31394861#31394861
`
execve -> do_execve -> do_execveat_common -> exec_binprm -> search_binary_handler (ELF/a.out/.coff) -> fs/binfmt_elf.c:load_binary -> … -> _start
`
Linux进程管理之进程的创建
http://blog.csdn.net/npy_lp/article/details/7292566
Linux进程管理之进程的终止
http://blog.csdn.net/npy_lp/article/details/7402305
Linux进程管理之执行新的程序
http://blog.csdn.net/npy_lp/article/details/7398572
Linux进程管理之内核线程
http://blog.csdn.net/npy_lp/article/details/7292592
如何查看Linux系统调用的列表?
`
# ausyscall –dump
Using x86_64 syscall table:
0 read
1 write
2 open
3 close
4 stat
…
`
Searchable Linux Syscall Table for x86 and x86_64
https://filippo.io/linux-syscall-table/
https://github.com/gregose/syscall-table
http://syscalls.kernelgrok.com/
http://blog.rchapman.org/posts/Linux_System_Call_Table_for_x86_64/
https://stackoverflow.com/questions/17652555/where-is-the-system-call-table-in-linux-kernel
https://www.digitalocean.com/community/tutorials/how-to-use-the-linux-auditing-system-on-centos-7
https://www.howtoing.com/how-to-use-the-linux-auditing-system-on-centos-7/
Linux系统调用
http://blog.sae.sina.com.cn/archives/2200
http://blog.csdn.net/kanghua/article/details/1836840
`
什么是系统调用
Linux的系统调用
系统调用、用户编程接口(API)、系统命令、和内核函数的关系
系统调用实现
系统调用思考
调用上下文分析
调用性能问题
什么时候添加系统调用
`
Linux 模块编程和syscall hook技术
http://onestraw.github.io/linux/lkm-and-syscall-hook/
https://stackoverflow.com/questions/2103315/linux-kernel-system-call-hooking-example
Rootkit技术(一)从syscall到hook
http://pwn4.fun/2017/01/04/Rootkit%E6%8A%80%E6%9C%AF%EF%BC%88%E4%B8%80%EF%BC%89%E4%BB%8Esyscall%E5%88%B0hook/
如何在Linux下监控命令执行
https://mp.weixin.qq.com/s/Qa3J6_dvdcSwoNF5W0fy1A
`
Linux系统中执行命令主要依靠execve函数族,可以通过hook execve函数的方法监控命令执行,首先编写两个测试程序帮助寻找hook。
确定了Hook点之后,就可以选择Hook方案了,这时有几个选择:
在应用层:
1、在ring3通过/etc/ld.so.preload劫持系统调用
2、二次开发glibc加入监控代码(据说某产品就是这么做监控的)
3、基于调试器思想通过ptrace()主动注入
在应用层做Hook的好处是不受内核版本影响,通用性较好,而且技术难度相对较低,但是缺点更明显,因为ring3层的Hook都是针对glibc库做的监控,只要直接陷入0x80中断,就可以绕过glibc库直接调用系统调用。
内核层的监控手段:
1、API Inline Hook
2、sys_call_table Hook
3、IDT Hook
4、利用LSM(Linux Security Module)
API Inline Hook以及IDT Hook操作难度较大,而且兼容性较差,利用LSM监控API虽然性能最好,但是必须编译进内核才能使用,不可以实时安装卸载,而sys_call_table的Hook相对易于操作,作为防御者也可以直接从” /boot/System.map-`uname -r` ”中直接获取sys_call_table地址,也可以利用LKM(loadable kernel module)技术实现实时安装卸载,所以最后选择在内核层Hook sys_call_table实现监控。
`
「驭龙」Linux执行命令监控驱动实现解析
https://mp.weixin.qq.com/s/ntE5FNM8UaXQFC5l4iKUUw
https://xz.aliyun.com/t/2242
Sudohulk – 替换 sudo,利用 ptrace Hook execve 系统调用实现劫持
https://github.com/hc0d3r/sudohulk
使用 Ptrace 拦截和模拟 Linux 系统调用
http://nullprogram.com/blog/2018/06/23/
https://github.com/skeeto/ptrace-examples
向正在运行的 Linux 进程注入恶意代码的方法
http://0x00sec.org/t/linux-infecting-running-processes/1097
在没有 execve 的情况下如何运行 Linux 可执行文件
https://blog.rapid7.com/2019/01/03/santas-elfs-running-linux-executables-without-execve/
[译] Linux系统调用权威指南
https://arthurchiao.github.io/blog/system-call-definitive-guide-zh/
https://blog.packagecloud.io/eng/2016/04/05/the-definitive-guide-to-linux-system-calls/
`
本文介绍了Linux程序是如何调用内核函数的。
包括:
几种不同的发起系统调用的方式
如何自己写汇编代码发起系统调用(包括示例)
系统调用的内核入口和内核出口
glibc wrappers
系统调用相关的内核bugs
其他更多内容
`
linux环境下无文件执行elf
https://blog.spoock.com/2019/08/27/elf-in-memory-execution/
`
所有的无文件渗透最关键的方法就是memfd_create()这个方法。
1. 说明
2. MEMFD_CREATE
3. ptrace
3.1. lseek
3.2. memfd_create
3.3. execve
4. ELF in-memory execution
4.1. fork
4.2. read
5. fireELF
6. 总结
7. 参考
`
http://man7.org/linux/man-pages/man2/memfd_create.2.html
Linux无文件渗透执行ELF
https://magisterquis.github.io/2018/03/31/in-memory-only-elf-execution.html
https://mp.weixin.qq.com/s/SdR6ce9xjbS5UQbh14kfgg
Linux系统内存执行ELF
https://blog.fbkcs.ru/en/elf-in-memory-execution/
https://www.anquanke.com/post/id/168791
fireELF:无文件Linux恶意代码框架
https://github.com/rek7/fireELF
https://www.freebuf.com/sectool/202312.html
https://github.com/QAX-A-Team/ptrace
反弹shell-逃逸基于execve的命令监控(上)
https://mp.weixin.qq.com/s/fx3ywEZiXEUStbrtzbpwrQ
`
三.已知对抗Shell命令监控方法
以上讲解了现有Shell命令监控方法,下面一一进行击破。对抗命令监控一般是在三个方面动手脚:
1. 绕过Shell命令监控方法,使之收集不到命令执行的日志。
2. 无法绕过命令监控,但是能篡改命令执行的进程和参数,使之收集到假的日志
3. 无法绕过监控,也无法篡改内容, 猜测命令告警的策略并绕过(例如通过混淆绕过命令静态检测)
在上述的三个方法中,第一种和第二种方法算是比较根本的方法,没有真实的数据,策略模型就无法命中目标并告警,第三种方法需要较多的经验,但是通过混淆命令绕过静态检测策略,也是比较常见的。
3.1 无日志-绕过Shell命令监控
1. 绕过glibc/libc exec劫持
2. 绕过Patch Shell解释器
3. 绕过内核态execve syscall
3.2 假日志 – 混淆进程名与进程参数
1.混淆进程名
2.混淆进程参数
`
http://www.polaris-lab.com/index.php/archives/667/
https://segmentfault.com/a/1190000019828080
reporting all execs
https://outflux.net/blog/archives/2010/07/01/reporting-all-execs/
http://bazaar.launchpad.net/~kees/+junk/cn_proc/annotate/head:/cn_proc.c
Process Events Connector
https://lwn.net/Articles/157150/
https://lkml.org/lkml/2005/9/28/347
`
This patch adds a connector that reports fork, exec, id change, and exit events for all processes to userspace. The patch merges the fork and exit connector patches previously in -mm by Guillaume and Badari along with two new significant events — exec and [ug]id changes — into a single connector that reports process events.
Applications that may find these events useful include accounting/auditing (e.g. ELSA), system activity monitoring (e.g. top), security, and resource management (e.g. CKRM).
`
在终端输入命令后系统做了什么
https://zdyxry.github.io/2020/04/25/%E5%9C%A8%E7%BB%88%E7%AB%AF%E8%BE%93%E5%85%A5%E5%91%BD%E4%BB%A4%E5%90%8E%E7%B3%BB%E7%BB%9F%E5%81%9A%E4%BA%86%E4%BB%80%E4%B9%88/
`
1. 背景
2. Shell
2.1. 如何运行程序
3. Golang 简易实现
4. 参考链接
在 shell 中因为需要执行其他的程序,需要用到 execvp ,execvp 会将指定的程序复制到调用它的进程,将指定的字符串组作为参数传递给程序,然后运行程序。这里存在一个问题, execvp 的执行过程是内核将程序加载到当前进程,替换当前进程的代码和数据,然后执行,那么原有进程的状态都被替换掉,在执行完程序就直接退出,不会再回到原程序等待下次输入。
为了保证我们在执行程序后回到 shell 中,需要每次创建新的进程来执行程序,调用 fork 指令,进程调用 fork 后,内核分配新的内存块和内核数据结构,复制原进程到新的进程,向运行进程添加新的进程,将控制返回给两个进程。通过 fork 返回值来判断当前进程是否为父进程或子进程。
shell 作为父进程通过调用 fork 创建子进程后,子进程通过 execvp 加载指定程序执行,父进程需要等待子进程退出,需要用到 wait ,在父进程 fork 出子进程后,父进程执行 wait 等待子进程执行,在调用时会传递一个整型变量地址,子进程执行完成后调用 exit 退出,内核将子进程的退出状态保存在这个变量中,用于父进程感知子进程退出状态。
`
Writing a simple shell in Go
https://sj14.gitlab.io/post/2018/07-01-go-unix-shell/
linux无文件执行— fexecve 揭秘
https://mp.weixin.qq.com/s/Hywbb1ZnRo6n4gFFp5rbcQ
`
linux无文件执行,首先要提到两个函数:memfd_create 和 fexecve。
1. memfd_create:允许我们在内存中创建一个文件,但是它在内存中的存储并不会被映射到文件系统中,至少,如果映射了,我是没找到,因此不能简单的通过ls命令进行查看,现在看来这的确是相当隐蔽的。事实上,如果一个文件存在,那么我们还是可以去发现它的,谁会去调用这个文件呢?使用如下的命令:
lsof | grep memfd
2. 第二个函数,fexecve同样的功能很强大,它能使我们执行一个程序(同execve),但是传递给这个函数的是文件描述符,而不是文件的绝对路径,和memfd_create搭配使用非常完美!
但是这里有一个需要注意的地方就是,因为这两个函数相对比较新,memfd_create 是在kernel 3.17才被引进来,fexecve是glibc的一个函数,是在版本2.3.2之后才有的, 没有fexecve的时候, 可以使用其它方式去取代它,而memfd_create只能用在相对较新的linux内核系统上。
今天不谈memfd_create,这是linux的新特性,没有什么好玩的,本人对fexecve 的实现很有兴趣,因为fexecve是glibc中的函数,而不是linux的系统调用。先看一下fexecve的用法,下面的fexecve_test.c 代码是实现ls -l /dev/shm 功能。
`
无”命令”反弹shell-逃逸基于execve的命令监控(上)
https://mp.weixin.qq.com/s/fx3ywEZiXEUStbrtzbpwrQ
COW奶牛!Copy On Write机制了解一下
https://mp.weixin.qq.com/s?__biz=MzI4Njg5MDA5NA==&mid=2247484364&idx=1&sn=60b00b2188047267e5c46c09ae248ca8
`
在fork之后exec之前两个进程用的是相同的物理空间(内存区),子进程的代码段、数据段、堆栈都是指向父进程的物理空间,也就是说,两者的虚拟空间不同,但其对应的物理空间是同一个。
当父子进程中有更改相应段的行为发生时,再为子进程相应的段分配物理空间。
如果不是因为exec,内核会给子进程的数据段、堆栈段分配相应的物理空间(至此两者有各自的进程空间,互不影响),而代码段继续共享父进程的物理空间(两者的代码完全相同)。
而如果是因为exec,由于两者执行的代码不同,子进程的代码段也会分配单独的物理空间。
# Copy On Write技术实现原理:
fork()之后,kernel把父进程中所有的内存页的权限都设为read-only,然后子进程的地址空间指向父进程。当父子进程都只读内存时,相安无事。当其中某个进程写内存时,CPU硬件检测到内存页是read-only的,于是触发页异常中断(page-fault),陷入kernel的一个中断例程。中断例程中,kernel就会把触发的异常的页复制一份,于是父子进程各自持有独立的一份。
# Copy On Write技术好处是什么?
COW技术可减少分配和复制大量资源时带来的瞬间延时。
COW技术可减少不必要的资源分配。比如fork进程时,并不是所有的页面都需要复制,父进程的代码段和只读数据段都不被允许修改,所以无需复制。
# Copy On Write技术缺点是什么?
如果在fork()之后,父子进程都还需要继续进行写操作,那么会产生大量的分页错误(页异常中断page-fault),这样就得不偿失。
# 几句话总结Linux的Copy On Write技术:
fork出的子进程共享父进程的物理空间,当父子进程有内存写入操作时,read-only内存页发生中断,将触发的异常的内存页复制一份(其余的页还是共享父进程的)。
fork出的子进程功能实现和父进程是一样的。如果有需要,我们会用exec()把当前进程映像替换成新的进程文件,完成自己想要实现的功能。
# 最后我们再来看一下写时复制的思想(摘录自维基百科):
写入时复制(英语:Copy-on-write,简称COW)是一种计算机程序设计领域的优化策略。其核心思想是,如果有多个调用者(callers)同时请求相同资源(如内存或磁盘上的数据存储),他们会共同获取相同的指针指向相同的资源,直到某个调用者试图修改资源的内容时,系统才会真正复制一份专用副本(private copy)给该调用者,而其他调用者所见到的最初的资源仍然保持不变。这过程对其他的调用者都是透明的(transparently)。此作法主要的优点是如果调用者没有修改该资源,就不会有副本(private copy)被建立,因此多个调用者只是读取操作时可以共享同一份资源。
至少从本文我们可以总结出:
* Linux通过Copy On Write技术极大地减少了Fork的开销。
* 文件系统通过Copy On Write技术一定程度上保证数据的完整性。
`