=Start=
缘由:
学习、提高需要
正文:
参考解答:
一、什么是Apache Storm?
Apache Storm是一个分布式实时大数据处理系统。Storm设计用于在容错和水平可扩展方法中处理大量数据。它是一个流数据框架,具有很高的吞吐率。虽然Storm是无状态的,它通过Apache ZooKeeper管理分布式环境和集群状态。它很简单,您可以并行地对实时数据执行各种操作。Apache Storm易于设置和操作,并且它保证每个消息将通过拓扑至少处理一次。
二、Apache Storm vs. Hadoop
Hadoop和Storm框架都用于分析大数据。两者互补,在某些方面有所不同。Apache Storm执行除持久性之外的所有操作,而Hadoop在所有方面都很好,但滞后于实时计算。下表比较了Storm和Hadoop的属性。
| Storm | Hadoop |
|---|---|
| 实时流处理 | 批量处理 |
| 无状态 | 有状态 |
| 主/从架构与基于ZooKeeper的协调。主节点称为nimbus,从属节点是主管。 | 具有/不具有基于ZooKeeper的协调的主 – 从结构。主节点是作业跟踪器,从节点是任务跟踪器。 |
| Storm流过程在集群上每秒可以访问数万条消息。 | Hadoop分布式文件系统(HDFS)使用MapReduce框架来处理大量的数据,需要几分钟或几小时。 |
| Storm拓扑运行直到用户关闭或意外的不可恢复故障。 | MapReduce作业按顺序执行并最终完成。 |
| 两者都是分布式和容错的 | |
| 如果nimbus / supervisor死机,重新启动使它从它停止的地方继续,因此没有什么受到影响。 | 如果JobTracker死机,所有正在运行的作业都会丢失。 |
- Storm: 分布式实时计算,强调实时性,常用于实时性要求较高的地方;
- Hadoop:分布式批处理计算,强调批处理,常用于对已经在的大量数据进行挖掘、分析;
三、Apache Storm的核心概念
下图描述了Apache Storm的核心概念。
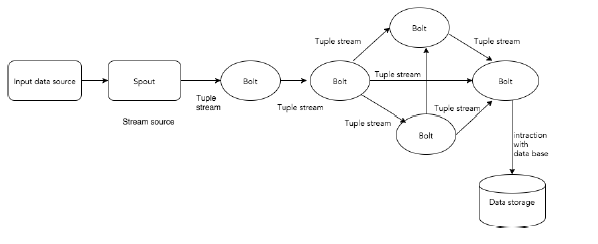
Storm 集群的输入流由一个被称作 spout 的组件管理,spout 把数据传递给 bolt, bolt 要么把数据保存到某种存储器,要么把数据传递给其它的 bolt。你可以想象一下,一个 Storm 集群就是在一连串的 bolt 之间转换 spout 传过来的数据:
data-source -> spout -> bolt[ -> bolt ...] -> data-storage
现在让我们仔细看看Apache Storm的组件:
| 组件 | 描述 |
|---|---|
| Tuple | Tuple是Storm中的主要数据结构。它是有序元素的列表。默认情况下,Tuple支持所有数据类型。通常,它被建模为一组逗号分隔的值,并传递到Storm集群。 |
| Stream | 流是元组的无序序列。 |
| Spouts | 流的源。通常,Storm从原始数据源(如Twitter Streaming API,Apache Kafka队列,Kestrel队列等)接受输入数据。否则,您可以编写spouts以从数据源读取数据。“ISpout”是实现spouts的核心接口,一些特定的接口是IRichSpout,BaseRichSpout,KafkaSpout等。 |
| Bolts | Bolts是逻辑处理单元。Spouts将数据传递到Bolts和Bolts过程,并产生新的输出流。Bolts可以执行过滤,聚合,加入,与数据源和数据库交互的操作。Bolts接收数据并发射到一个或多个Bolts。 “IBolt”是实现Bolts的核心接口。一些常见的接口是IRichBolt,IBasicBolt等。 |
拓扑
Spouts和Bolts连接在一起,形成拓扑结构。实时应用程序逻辑在Storm拓扑中指定。简单地说,拓扑是有向图,其中顶点是计算,边缘是数据流。
简单拓扑从spouts开始。Spouts将数据发射到一个或多个Bolts。Bolt表示拓扑中具有最小处理逻辑的节点,并且Bolts的输出可以发射到另一个Bolts作为输入。
Storm保持拓扑始终运行,直到您终止拓扑。Apache Storm的主要工作是运行拓扑,并在给定时间运行任意数量的拓扑。
任务
现在你有一个关于Spouts和Bolts的基本想法。它们是拓扑的最小逻辑单元,并且使用单个Spout和Bolt阵列构建拓扑。应以特定顺序正确执行它们,以使拓扑成功运行。Storm执行的每个Spout和Bolt称为“任务”。简单来说,任务是Spouts或Bolts的执行。在给定时间,每个Spout和Bolt可以具有在多个单独的螺纹中运行的多个实例。
进程
拓扑在多个工作节点上以分布式方式运行。Storm将所有工作节点上的任务均匀分布。工作节点的角色是监听作业,并在新作业到达时启动或停止进程。
四、Apache Storm的集群架构
Apache Storm的主要亮点是,它是一个容错,快速,没有“单点故障”(SPOF)分布式应用程序。我们可以根据需要在多个系统中安装Apache Storm,以增加应用程序的容量。
让我们看看Apache Storm集群如何设计和其内部架构。下图描述了集群设计:
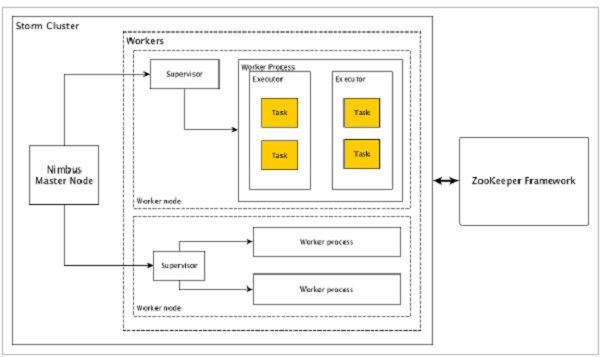
Apache Storm有两种类型的节点,Nimbus(主节点)和Supervisor(工作节点)。Nimbus是Apache Storm的核心组件。Nimbus的主要工作是运行Storm拓扑。Nimbus分析拓扑并收集要执行的任务。然后,它将任务分配给可用的supervisor。
Supervisor将有一个或多个工作进程。Supervisor将任务委派给工作进程。工作进程将根据需要产生尽可能多的执行器并运行任务。Apache Storm使用内部分布式消息传递系统来进行Nimbus和管理程序之间的通信。
| 组件 | 描述 |
|---|---|
| Nimbus(主节点) | Nimbus是Storm集群的主节点。集群中的所有其他节点称为工作节点。主节点负责在所有工作节点之间分发数据,向工作节点分配任务和监视故障。 |
| Supervisor(工作节点) | 遵循指令的节点被称为Supervisors。Supervisor有多个工作进程,它管理工作进程以完成由nimbus分配的任务。 |
| Worker process(工作进程) | 工作进程将执行与特定拓扑相关的任务。工作进程不会自己运行任务,而是创建执行器并要求他们执行特定的任务。工作进程将有多个执行器。 |
| Executor(执行者) | 执行器只是工作进程产生的单个线程。执行器运行一个或多个任务,但仅用于特定的spout或bolt。 |
| Task(任务) | 任务执行实际的数据处理。所以,它是一个spout或bolt。 |
| ZooKeeper framework(ZooKeeper框架) | Apache的ZooKeeper的是使用群集(节点组)自己和维护具有强大的同步技术共享数据之间进行协调的服务。Nimbus是无状态的,所以它依赖于ZooKeeper来监视工作节点的状态。
ZooKeeper的帮助supervisor与nimbus交互。它负责维持nimbus,supervisor的状态。 |
Storm是无状态的。即使无状态性质有它自己的缺点,它实际上帮助Storm以最好的可能和最快的方式处理实时数据。
Storm虽然不是完全无状态的。它将其状态存储在Apache ZooKeeper中。由于状态在Apache ZooKeeper中可用,故障的网络可以重新启动,并从它离开的地方工作。通常,像monit这样的服务监视工具将监视Nimbus,并在出现任何故障时重新启动它。
五、Apache Storm的入门实例
HelloWorldSpout.java
public class HelloWorldSpout extends BaseRichSpout{
private SpoutOutputCollector collector;
private int referenceRandom;
private static final int MAX_RANDOM = 10;
public HelloWorldSpout() {
final Random rand = new Random();
referenceRandom = rand.nextInt(MAX_RANDOM);
}
/*
* declareOutputFields() => you need to tell the Storm cluster which fields this Spout emits within the
* declareOutputFields method.
*/
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("sentence"));
}
/*
* open() => The first method called in any spout is 'open'
* TopologyContext => contains all our topology data
* SpoutOutputCollector => enables us to emit the data that will be processed by the bolts
* conf => created in the topology definition
*/
@Override
public void open(Map conf, TopologyContext topologyContext, SpoutOutputCollector collector) {
this.collector = collector;
}
/*
* nextTuple() => Storm cluster will repeatedly call the nextTuple method which will do all the work of the spout.
* nextTuple() must release the control of the thread when there is no work to do so that the other methods have
* a chance to be called.
*/
@Override
public void nextTuple() {
final Random rand = new Random();
int instanceRandom = rand.nextInt(MAX_RANDOM);
if(instanceRandom == referenceRandom){
collector.emit(new Values("Hello World"));
} else {
collector.emit(new Values("Other Random Word"));
}
}
}
HelloWorldBolt.java
public class HelloWorldBolt extends BaseRichBolt {
private int myCount = 0;
/*
* prepare() => on create
*/
@Override
public void prepare(Map map, TopologyContext topologyContext, OutputCollector outputCollector) {
}
/*
* execute() => most important method in the bolt is execute(Tuple input), which is called once per tuple received
* the bolt may emit several tuples for each tuple received
*/
@Override
public void execute(Tuple tuple) {
String test = tuple.getStringByField("sentence");
if(test == "Hello World"){
myCount++;
System.out.println("Found a Hello World! My Count is now: " + Integer.toString(myCount));
}
}
/*
* declareOutputFields => This bolt emits nothing hence no body for declareOutputFields()
*/
@Override
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
}
}
HelloWorldTopology.java
/**
* Author: ashrith
* Desc: setup the topology and submit it to either a local of remote Storm cluster depending on the arguments
* passed to the main method.
*/
public class HelloWorldTopology {
/*
* main class in which to define the topology and a LocalCluster object (enables you to test and debug the
* topology locally). In conjunction with the Config object, LocalCluster allows you to try out different
* cluster configurations.
*
* Create a topology using 'TopologyBuilder' (which will tell storm how the nodes area arranged and how they
* exchange data)
* The spout and the bolts are connected using 'ShuffleGroupings'
*
* Create a 'Config' object containing the topology configuration, which is merged with the cluster configuration
* at runtime and sent to all nodes with the prepare method
*
* Create and run the topology using 'createTopology' and 'submitTopology'
*/
public static void main(String[] args) throws AlreadyAliveException, InvalidTopologyException {
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("randomHelloWorld", new HelloWorldSpout(), 10);
builder.setBolt("HelloWorldBolt", new HelloWorldBolt(), 1).shuffleGrouping("randomHelloWorld");
Config conf = new Config();
conf.setDebug(true);
if(args!=null && args.length > 0) {
conf.setNumWorkers(3);
StormSubmitter.submitTopology(args[0], conf, builder.createTopology());
} else {
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("test", conf, builder.createTopology());
Utils.sleep(10000);
cluster.killTopology("test");
cluster.shutdown();
}
}
}
参考链接:
- Apache Storm核心概念
https://www.w3cschool.cn/apache_storm/apache_storm_core_concepts.html
Apache Storm集群架构
https://www.w3cschool.cn/apache_storm/apache_storm_cluster_architecture.html
Apache Storm工作实例
https://www.w3cschool.cn/apache_storm/apache_storm_working_example.html - Storm教程
http://www.tianshouzhi.com/api/tutorials/storm - sample hello world topology with pom
https://github.com/ashrithr/storm-helloworld - Storm 入门教程
http://www.dahouduan.com/2015/11/10/storm-tutorial/
=END=
《 “Apache Storm入门学习” 》 有 28 条评论
大数据框架对比:Hadoop、Storm、Samza、Spark和Flink
http://www.infoq.com/cn/articles/hadoop-storm-samza-spark-flink/
What is/are the main difference(s) between Flink and Storm?
https://stackoverflow.com/questions/30699119/what-is-are-the-main-differences-between-flink-and-storm
流式大数据处理的三种框架:Storm,Spark和Samza
http://www.csdn.net/article/2015-03-09/2824135
Spark与Flink:对比与分析
http://www.csdn.net/article/2015-07-16/2825232
流式大数据处理的三种框架:Storm,Spark和Flink
http://blog.csdn.net/cm_chenmin/article/details/53072498
实时流处理Storm、Spark Streaming、Samza、Flink孰优孰劣?
http://www.dataguru.cn/article-9532-1.html
Flink官方文档翻译:安装部署(本地模式)
http://wuchong.me/blog/2016/02/26/flink-docs-setup-local/
Flink官方文档翻译:安装部署(集群模式)
http://wuchong.me/blog/2016/02/26/flink-docs-setup-cluster/
http://wuchong.me/categories/Flink/
HDFS是GFS的一种实现,它的完整名字是分布式文件系统,类似于FAT32、NTFS,是一种文件格式,是底层的。
HBase是Hadoop database,即Hadoop数据库。它是一个适合于非结构化数据存储的数据库,HBase是基于列的而不是基于行的模式。HBase是Google Bigtable的开源实现,类似Google Bigtable利用GFS作为其文件存储系统,HBase利用Hadoop HDFS作为其文件存储系统;Google运行MapReduce来处理Bigtable中的海量数据,HBase同样利用Hadoop MapReduce来处理HBase中的海量数据。
Hive基于数据仓库,提供静态数据的动态查询(不支持更改数据的操作)。它使用类SQL语言,底层经过编译转为MapReduce程序,在Hadoop上运行,数据存储在HDFS上。
Pig和Hive类似,但更侧重于数据的查询和分析,底层都是转化成MapReduce程序运行。区别是Hive是类SQL的查询语言,要求数据存储于表中,而Pig是面向数据流的一个程序语言。
Hadoop HDFS为HBase提供了高可靠性的底层存储支持。Hadoop MapReduce为HBase提供了高性能的计算能力。Zookeeper为HBase提供了稳定服务和failover机制。Pig和Hive还为HBase提供了高层语言支持,使得在HBase上进行数据统计处理变的非常简单。
Hive和Hbase是两种基于Hadoop的不同技术–Hive是一种类SQL的引擎,并且运行MapReduce任务,Hbase是一种在Hadoop之上的NoSQL的Key/vale数据库。
hadoop、storm和spark的区别、比较
https://www.cnblogs.com/snowbook/p/5773562.html
Hadoop,Spark和Storm
http://blog.csdn.net/xiaomin1991222/article/details/50980638
http://www.open-open.com/lib/view/open1416646884102.html
Hadoop、Storm、Spark这三个大数据平台有啥区别,各有啥应用场景?
http://blog.csdn.net/w1014074794/article/details/50687524
量化派基于Hadoop、Spark、Storm的大数据风控架构
https://www.csdn.net/article/2015-10-06/2825849
与 Hadoop 对比,如何看待 Spark 技术?
https://www.zhihu.com/question/26568496
Hadoop,HBase,Storm,Spark到底是什么?
http://blog.csdn.net/yangzhenping/article/details/41826163
主流的三大分布式计算系统:Hadoop,Spark和Storm
https://www.douban.com/note/545951210/
hadoop和大数据的关系?和spark的关系?互补?并行?
https://www.zhihu.com/question/23036370
【专治不明觉厉】之“大数据”
https://www.huxiu.com/article/31457/1.html
`
Hadoop,Spark和Storm是目前最重要的三大分布式计算系统,Hadoop常用于离线的复杂的大数据处理,Spark常用于离线的快速的大数据处理,而Storm常用于在线的实时的大数据处理。
`
https://storm.apache.org/releases/0.9.7/javadocs/backtype/storm/tuple/Tuple.html#getSourceComponent–
https://nathanmarz.github.io/storm/doc/backtype/storm/tuple/Tuple.html#getSourceComponent()
http://www.cnblogs.com/kqdongnanf/p/4778672.html
`
如何在代码中自动获取当前的数据源topic名称,而不是写死在代码里面,请问是否有相关办法?
可以通过原生的 getSourceComponent() 来获取。
`
滑动窗口在storm中的实现
http://blog.sae.sina.com.cn/archives/5109
http://blog.csdn.net/yangbutao/article/details/17851853
Storm的滑动窗口
http://zqhxuyuan.github.io/2015/09/10/2015-09-10-Storm-Window/
Storm 实现滑动窗口计数和TopN排序
http://www.cnblogs.com/swanspouse/p/5130117.html
Storm Windowing storm滑动窗口简介
http://www.cnblogs.com/cutd/p/6188314.html
Storm实时计算:流操作入门编程实践
http://shiyanjun.cn/archives/977.html
`
declareStream
`
用实例理解Storm的Stream概念
http://zqhxuyuan.github.io/2016/06/30/Hello-Storm/
两个例子(来自Storm实战 构建大数据实时计算)
http://blog.csdn.net/wust__wangfan/article/details/50517554
storm中的一些概念
https://www.cnblogs.com/dreamforwang/p/6526421.html
使用Storm实现实时大数据分析
http://qq85609655.iteye.com/blog/2035717
storm中的一些概念
https://www.cnblogs.com/dreamforwang/p/6526421.html
使用Storm实现实时大数据分析
http://qq85609655.iteye.com/blog/2035717
Storm 的可靠性保证测试
https://tech.meituan.com/test-of-storms-reliability.html
流计算框架 Flink 与 Storm 的性能对比
https://tech.meituan.com/Flink_Benchmark.html
史上最详细的Hadoop环境搭建
http://paper.tuisec.win/detail/6e0f5d48fb89396
http://gitbook.cn/books/5954c9600326c7705af8a92a/index.html
【技术分享】谈谈Hadoop安全的那些事儿
https://mp.weixin.qq.com/s/bThdTMGUZDXQzI0ts2IGEw
http://paper.tuisec.win/detail/203cb39c8c775e2
基于Strom的日志实时流量分析主动防御(CCFirewall)系统
https://github.com/gy-games/shield
Hadoop Yarn REST API 未授权漏洞利用挖矿分析
https://paper.seebug.org/611/
storm调优
https://blog.csdn.net/jediael_lu/article/details/76903935
Apache Storm 官方文档 —— FAQ
http://ifeve.com/storm-faq/
http://storm.apache.org/releases/current/FAQ.html
Storm 性能优化 #nice
https://www.jianshu.com/p/f645eb7944b0
【Twitter Storm系列】Storm环境配置及吞吐量测试调优–个人理解
https://blog.csdn.net/weijonathan/article/details/38536671
Storm的概念
http://storm.apache.org/releases/1.2.1/Concepts.html
理解Storm Topology中并发度的概念
http://storm.apache.org/releases/1.2.1/Understanding-the-parallelism-of-a-Storm-topology.html
根据日志内容来决定如何消费
https://stackoverflow.com/questions/31592866/storm-conditionally-consuming-stream-from-kafka-spout
Storm的 emit
https://stackoverflow.com/questions/19807395/how-would-i-split-a-stream-in-apache-storm
`
先在 declareOutputFields 里面声明 stream ,然后在 execute 里面根据实际情况进行 emit 操作。
`
用实例理解Storm的Stream概念
http://zqhxuyuan.github.io/2016/06/30/Hello-Storm/
Storm 的主要概念
http://storm.apachecn.org/releases/cn/1.1.0/Concepts.html
如何利用Flink实现超大规模用户行为分析
http://www.hansight.com/blog-flink-UBA.html
`
导语:主要分为四大部分:
1)网络安全中的用户行为分析(简称 UBA);
2)实时超大规模用户行为分析的技术挑战 ;
3)Drools 规则引擎在 CEP 中的应用 ;
4)Flink 原生 CEP 组件。
`
通俗理解YARN运行原理
https://www.jianshu.com/p/3f406cf438be
《从0到1学习Flink》—— Apache Flink 介绍
http://yoursite.com/2018/10/13/flink-introduction/
《从0到1学习Flink》—— Flink 配置文件详解
http://www.54tianzhisheng.cn/2018/10/27/flink-config/
《从0到1学习Flink》—— Data Source 介绍
http://www.54tianzhisheng.cn/2018/10/28/flink-sources/
《从0到1学习Flink》—— Data Sink 介绍
http://www.54tianzhisheng.cn/2018/10/29/flink-sink/
《从0到1学习Flink》—— 如何自定义 Data Source ?
http://www.54tianzhisheng.cn/2018/10/30/flink-create-source/
《从0到1学习Flink》—— 如何自定义 Data Sink ?
http://www.54tianzhisheng.cn/2018/10/31/flink-create-sink/
理解 Storm 拓扑的并行度
https://mp.weixin.qq.com/s/Y506rIz_XxiwRVXXrbe5nw
Reading and Understanding the Storm UI [Storm UI explained]
http://www.malinga.me/reading-and-understanding-the-storm-ui-storm-ui-explained/
深入理解Flink核心技术
https://mp.weixin.qq.com/s/1ZLIruL4kYxH8rNd002XgQ
深入理解Apache Flink核心技术
https://mp.weixin.qq.com/s/g88kK3fVrOMT3GBbp1uiqg
Flink中的一些核心概念
https://mp.weixin.qq.com/s/AmZJXTDPKgzq4U_QQeXe1Q
求求你大蕉别学了之 Flink No.127
https://mp.weixin.qq.com/s/zkAz8Qc9urjb886ekbdOUQ
美团点评基于 Flink 的实时数仓建设实践
https://mp.weixin.qq.com/s/PJmdXkdUE5gtzcYAgAM8wQ
如何利用Flink实现超大规模用户行为分析
https://mp.weixin.qq.com/s/_Sky98xI9M8AkXf17SHt6g
https://stackoverflow.com/questions/507602/how-can-i-initialise-a-static-map
java 声明静态Map常量的一种简单方式
https://chenxiuheng.iteye.com/blog/996385
[Java]Map的静态赋值
https://blog.csdn.net/wenqisun/article/details/45394051
`
在Bolt的代码中,如果希望用HashMap做去重计数的功能,需要在外层申请一个 static 的HashMap,如果不这样的话,在每一条消息处理execute里面,该map的值总是空的。
`
cluster模式下storm kill topology时做cleanup的解决方法
https://blog.csdn.net/maixiaohai/article/details/51683098
https://blog.csdn.net/u010003835/article/details/52163430
`
在bolt中,需要在topology被关闭前执行某个操作,而根据官方文档,cleanup方法并不可靠,它只在local mode下生效。
# 解决方案
在killing a topology之前,需要先deactivate相应的topology,然后处理未完成的message。可以调用Spout.deactivate()方法,传给bolt一个特殊的tuple,在bolt处检查该特殊tuple,一旦收到执行需要执行的操作。
tuple的特殊性可以通过tuple的stream来区分。
`
https://storm.apache.org/releases/current/Lifecycle-of-a-topology.html
https://storm.apache.org/releases/current/Local-mode.html
Storm简单介绍
https://matt33.com/2015/05/26/the-basis-of-storm/
`
1. 基础
1.1. Storm的Topology模型
1.1.1. tuple
1.1.2. spout
1.1.3. bolt
1.1.4. Streams
1.2. storm并发机制
1.2.1. 默认的并发机制
1.2.2. 给topology增加worker
1.2.3. 配置executor和task
1.3. 数据流分组
1.4. 可靠的消息处理机制
1.4.1. spout的可靠性
1.4.2. bolt的可靠性
1.4.3. acker
2. Storm集群框架
2.1. nimbus守护进程
2.2. supervisor守护进程
2.3. Zookeeper的作用
3. Storm程序框架
3.1. topology提交
3.1.1. 本地模式
3.1.2. 集群模式
3.1.3. 实际的例子
3.2. Spout
3.3. Bolt
`
getting-started-with-storm
https://github.com/xetorthio/getting-started-with-storm/blob/master/ch05Bolts.asc
Stream Grouping类型
https://www.cnblogs.com/CRXY/p/4564070.html
Storm Grouping —— 流分组策略
https://www.cnblogs.com/xymqx/p/4365190.html
`
Shuffle Grouping :随机分组,尽量均匀分布到下游Bolt中
将流分组定义为混排。这种混排分组意味着来自Spout的输入将混排,或随机分发给此Bolt中的任务。shuffle grouping对各个task的tuple分配的比较均匀。
Fields Grouping :按字段分组,按数据中field值进行分组;相同field值的Tuple被发送到相同的Task
这种grouping机制保证相同field值的tuple会去同一个task,这对于WordCount来说非常关键,如果同一个单词不去同一个task,那么统计出来的单词次数就不对了。“if the stream is grouped by the “user-id” field, tuples with the same “user-id” will always go to the same task”.
All grouping :广播
广播发送, 对于每一个tuple将会复制到每一个bolt中处理。
Global grouping :全局分组,Tuple被分配到一个Bolt中的一个Task,实现事务性的Topology。
Stream中的所有的tuple都会发送给同一个bolt任务处理,所有的tuple将会发送给拥有最小task_id的bolt任务处理。
None grouping :不分组
不关注并行处理负载均衡策略时使用该方式,目前等同于shuffle grouping,另外storm将会把bolt任务和他的上游提供数据的任务安排在同一个线程下。
Direct grouping :直接分组 指定分组
由tuple的发射单元直接决定tuple将发射给那个bolt,一般情况下是由接收tuple的bolt决定接收哪个bolt发射的Tuple。这是一种比较特别的分组方法,用这种分组意味着消息的发送者指定由消息接收者的哪个task处理这个消息。 只有被声明为Direct Stream的消息流可以声明这种分组方法。而且这种消息tuple必须使用emitDirect方法来发射。消息处理者可以通过TopologyContext来获取处理它的消息的taskid (OutputCollector.emit方法也会返回taskid)。
`
Storm杂记 — Field Grouping和Shuffle Grouping的区别
https://blog.csdn.net/luonanqin/java/article/details/40436397
关于Storm Stream grouping
https://www.cnblogs.com/kqdongnanf/p/4634607.html
2.5 grouping策略和并发度
http://www.tianshouzhi.com/api/tutorials/storm/15
Storm部分:Storm Grouping — 数据流分组(即数据分发策略)
https://blog.csdn.net/wyqwilliam/java/article/details/82156437
Storm 系列(二)—— Storm 核心概念详解
https://juejin.im/post/5d8593a0518825680725c883#heading-5
`
1.5 Stream groupings(分组策略)
spouts 和 bolts 在集群上执行任务时,是由多个 Task 并行执行 (如上图,每一个圆圈代表一个 Task)。当一个 Tuple 需要从 Bolt A 发送给 Bolt B 执行的时候,程序如何知道应该发送给 Bolt B 的哪一个 Task 执行呢?
这是由 Stream groupings 分组策略来决定的,Storm 中一共有如下 8 个内置的 Stream Grouping。当然你也可以通过实现 CustomStreamGrouping 接口来实现自定义 Stream 分组策略。
# Shuffle grouping
Tuples 随机的分发到每个 Bolt 的每个 Task 上,每个 Bolt 获取到等量的 Tuples。
# Fields grouping
Streams 通过 grouping 指定的字段 (field) 来分组。假设通过 user-id 字段进行分区,那么具有相同 user-id 的 Tuples 就会发送到同一个 Task。
# Partial Key grouping
Streams 通过 grouping 中指定的字段 (field) 来分组,与 Fields Grouping 相似。但是对于两个下游的 Bolt 来说是负载均衡的,可以在输入数据不平均的情况下提供更好的优化。
# All grouping
Streams 会被所有的 Bolt 的 Tasks 进行复制。由于存在数据重复处理,所以需要谨慎使用。
# Global grouping
整个 Streams 会进入 Bolt 的其中一个 Task,通常会进入 id 最小的 Task。
# None grouping
当前 None grouping 和 Shuffle grouping 等价,都是进行随机分发。
# Direct grouping
Direct grouping 只能被用于 direct streams 。使用这种方式需要由 Tuple 的生产者直接指定由哪个 Task 进行处理。
# Local or shuffle grouping
如果目标 Bolt 有 Tasks 和当前 Bolt 的 Tasks 处在同一个 Worker 进程中,那么则优先将 Tuple Shuffled 到处于同一个进程的目标 Bolt 的 Tasks 上,这样可以最大限度地减少网络传输。否则,就和普通的 Shuffle Grouping 行为一致。
`