=Start=
缘由:
虽然之前因为大量日志安全分析、处理的原因,已经实际用过Hadoop MapReduce、Storm、Hive、Presto等大数据工具,但毕竟不是专门做大数据相关工作的,而且现在大数据的发展速度也快,所以也经常对一些名词是云里雾里的——不甚明白,因此一直想找机会大致系统的了解一下,也不希望多么精深,只希望不落后于这个时代就行。
正文:
参考解答:
理论基础:
- 《Google File System》:论述了怎样借助普通机器有效的存储海量的大数据;(HDFS是对应的开源实现)
- 《Google MapReduce》:论述了怎样快速计算海量的数据;(Hadoop MapReduce是其对应的开源实现)
- 《Google BigTable》:论述了怎样实现海量数据的快速查询;(HBase是其对应的开源实现)
要解决的核心问题:
- 存储,海量的数据怎样有效的存储?主要包括HDFS;
- 计算,海量的数据怎样快速计算?主要包括MapReduce、Storm、Spark、Flink等;
- 查询,海量数据怎样快速查询?主要为NoSQL和OLAP,NoSQL主要包括HBase、 Cassandra等,其中OLAP包括Kylin、Impla等,其中NoSQL主要解决随机查询,OLAP技术主要解决关联查询;
- 挖掘,海量数据怎样挖掘出隐藏的知识?也就是当前火热的机器学习和深度学习等技术,包括TensorFlow、Caffe、Mahout等;
一图流:
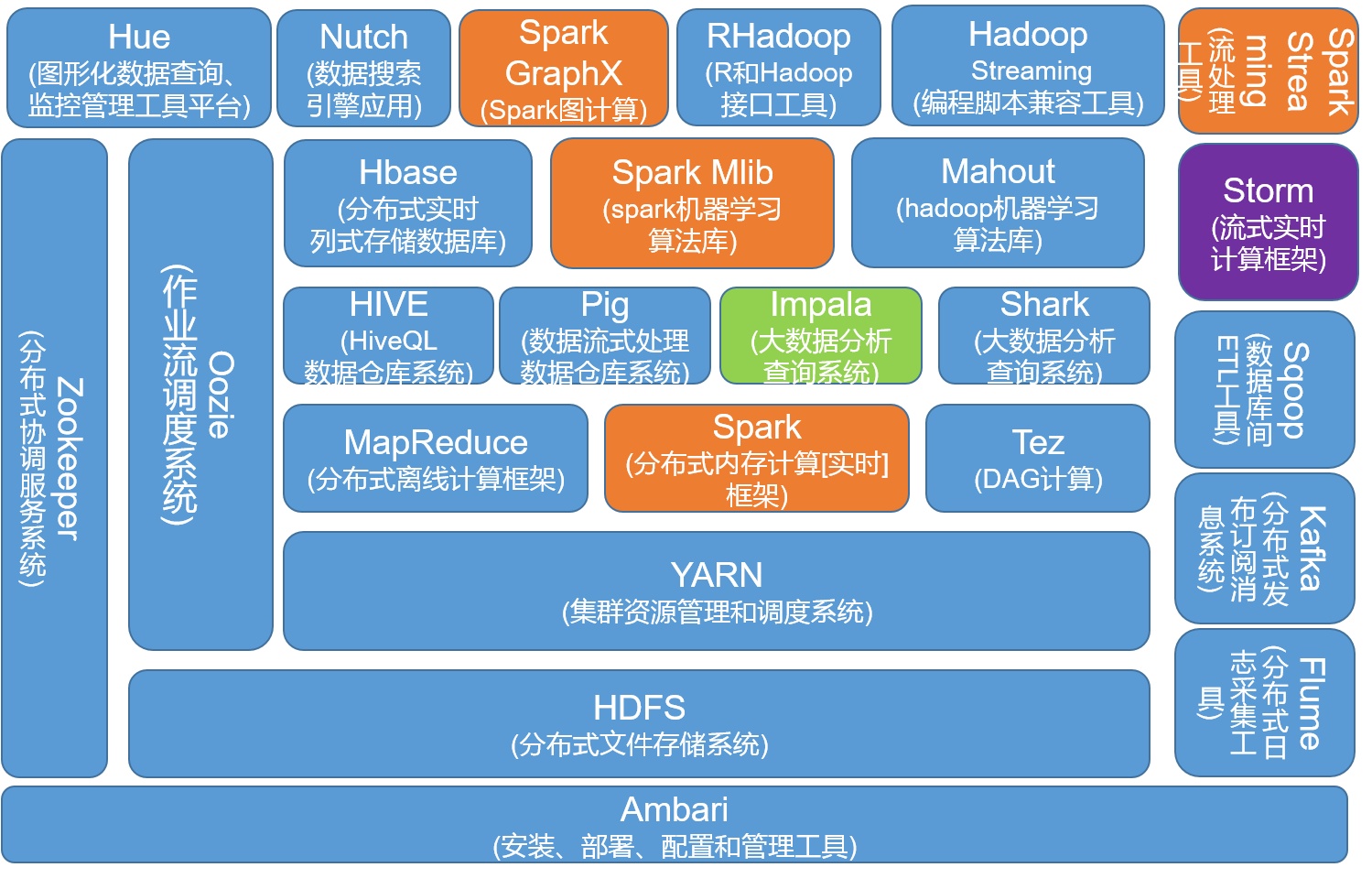
数据存储、资源管理调度、离线批处理、数据仓库、实时流处理、键值查询、数据挖掘、一些功能组件(ZooKeeper、Kafka、……)
参考链接:
- 如何用形象的比喻描述大数据的技术生态?Hadoop、Hive、Spark 之间是什么关系?
https://www.zhihu.com/question/27974418 - 与 Hadoop 对比,如何看待 Spark 技术?
https://www.zhihu.com/question/26568496 - The Big Data Landscape
http://www.bigdatalandscape.com/ - 大数据技术生态
https://www.jianshu.com/p/fe97a452801a - 七张图全面了解大数据生态圈
http://blog.csdn.net/swingwang/article/details/53105844
=END=
《 “大数据生态” 》 有 42 条评论
关于 大数据 的相关会议
https://www.huodongjia.com/tag/969/
http://blog.csdn.net/huodongjia2016/article/details/54427853
大数据资源整理
https://zhuanlan.zhihu.com/p/24231891
大数据学习路线
http://blog.csdn.net/an342647823/article/details/40185181
史上最全的“大数据”学习资源(上)
https://github.com/onurakpolat/awesome-bigdata
https://yq.aliyun.com/articles/37308
一共81个,开源大数据处理工具汇总(上)
http://www.36dsj.com/archives/24852
Hive和HBase区别
https://www.cnblogs.com/justinzhang/p/4273470.html
https://www.xplenty.com/blog/hive-vs-hbase/
Hive,Hbase,HDFS等之间的关系 #nice
http://blog.csdn.net/ooc_zc/article/details/50444222
Hadoop十年解读与发展预测
http://www.infoq.com/cn/articles/hadoop-ten-years-interpretation-and-development-forecast
宏观了解之hadoop生态圈
https://www.jianshu.com/p/d3d35c28f2c3
大数据(big data):基础概念
https://zhuanlan.zhihu.com/p/33619503
4. “大数据(big data)“的定义——6个”V”
`
我们通过6个维度来定义什么是”大数据”,这个维度的英文单词都是由字母”V”开头,所以也可以简记为6个“V”。分别是:Volume(规模)、Velocity(速度)、Variety(多样)、Veracity(质量)、Valence(连接)、Value(价值)
Volume(规模):指的是每天产生的海量数据
Velocity(速度):指的是数据产生的速度越来越快
Variety(多样):指的是数据格式的多样性,例如文本、语音、图片等
Veracity(质量):指的是数据的质量差别可以非常大
Valence(连接):指的是大数据之间如何产生联系
Value(价值):数据处理可以带来不同寻常的洞见进而产生价值
`
挖掘分布式系统——Hadoop的漏洞
https://zhuanlan.zhihu.com/p/28901633
https://www.zhihu.com/topic/19563390/hot
高手指路:Linux运维工程师的大数据安全修炼手册
https://mp.weixin.qq.com/s/VGe5VY46CfdO0Mc02NZN9Q
动手学深度学习
http://zh.gluon.ai/
http://gluon.mxnet.io/ #英文版本
谷歌上线自带中文的机器学习免费课程,我们带你做了个测评
https://mp.weixin.qq.com/s/U2XBScWThbIEB4EdV4q63A
Google出品的机器学习速成课程(使用 TensorFlow API)
https://developers.google.cn/machine-learning/crash-course/ml-intro
浅谈大数据平台基建的逻辑
http://gigix.thoughtworkers.org/2018/3/16/infrastructure-of-big-data/
`
接入层(Landing):以和源系统相同的结构暂存原始数据。有时被称为“贴源层”或ODS。
整合层(Integration):持久存储整合后的企业数据,针对企业信息实体和业务事件建模,代表组织的“唯一真相来源”。有时被称为“数据仓库”。
表现层(Presentation):为满足最终用户的需求提供可消费的数据,针对商业智能和查询性能建模。有时被称为“数据集市”。
语义层(Semantic):提供数据的呈现形式和访问控制。例如某种报表工具。
终端用户应用(End-user applications):使用语义层的工具,将表现层数据最终呈现给用户,包括仪表板、报表、图表等多种形式。
元数据(Metadata):记录各层数据项的定义(Definitions)、血缘(Genealogy)、处理过程(Processing)。
`
技术资源推荐(数据仓库篇)
http://www.mdjs.info/2018/03/21/data-warehouse/data-warehouse-resources/
`
1. 0x00 前言
2. 0x01 书籍推荐
2.1. 一、数据仓库工具箱(第3版):维度建模权威指南
2.2. 二、数据仓库(原书第4版)
2.3. 三、数据挖掘:概念与技术(原书第3版)
2.4. 四、大数据之路:阿里巴巴大数据实践
2.5. 五、大数据日知录
3. 0xFF 总结
`
【技术分享】谈谈Hadoop安全的那些事儿
https://mp.weixin.qq.com/s/bThdTMGUZDXQzI0ts2IGEw
Hadoop, Hbase, Zookeeper安全实践
http://www.wuzesheng.com/?p=2345
YARN & HDFS2 安装和配置Kerberos
https://blog.csdn.net/lalaguozhe/article/details/11570009
常用的几种大数据架构剖析
https://insights.thoughtworks.cn/common-big-data-infrastructure/
`
总的来说,目前围绕Hadoop体系的大数据架构大概有以下几种:
传统大数据架构
流式架构
Lambda架构(Lambda的数据通道分为两条分支:实时流和离线。)
Kappa架构(将实时和流部分进行了合并,将数据通道以消息队列进行替代。)
Unifield架构(将机器学习和数据处理揉为一体,从核心上来说,Unifield依旧以Lambda为主,不过对其进行了改造,在流处理层新增了机器学习层。)
`
模式识别、机器学习傻傻分不清?给我三分钟!
https://mp.weixin.qq.com/s/rzhrjG0B40-Ml9vkuiTpMw
`
AI元老——模式识别
那什么是模式识别?它指的是,对表征事物或现象的各种形式的信息进行处理和分析,从而达到对事物或现象进行描述、辨认、分类和解释的目的。
AI大众情人——机器学习
不同于模式识别中人类主动去描述某些特征给机器,机器学习可以这样理解:机器从已知的经验数据(样本)中,通过某种特定的方法(算法),自己去寻找提炼(训练/学习)出一些规律(模型);提炼出的规律就可以用来判断一些未知的事情(预测)。
`
https://www.zhihu.com/question/38106452/answer/211218782
http://blog.csdn.net/feichizhongwu888/article/details/52727958
https://www.cnblogs.com/muchen/p/5434359.html#_label0
终于有人把云计算、大数据和人工智能讲明白了!
https://mp.weixin.qq.com/s/RYT-WyQ-ZNH6ugJ142BwwQ
https://www.cnblogs.com/popsuper1982/p/8505203.html
Druid Storage 原理
https://blog.bcmeng.com/post/druid-storage.html
`
What is Druid
Why Druid
Druid 架构
Column
Segment
Segment的存储格式
指标列的存储格式
String 维度的存储格式
Segment生成过程
Segment load过程
Segment Query过程
Druid的编码和压缩
总结
参考资料
`
[Spark SQL]、[Spark Streaming]、[Spark MLlib]、[Spark GraphX]
==========================================
[Apache Spark]
快速安装高可用 Hadoop & Spark 集群,设置基本配置,让大家迅速上手
https://github.com/marc-chen/hadoop-spark-installer
与 Hadoop 对比,如何看待 Spark 技术?
https://www.zhihu.com/question/26568496
https://www.zhihu.com/topic/19942170/top-answers
https://www.zhihu.com/topic/19563390/top-answers
Hadoop、spark、SaaS、PaaS、IaaS、云计算概念区分?
https://www.zhihu.com/question/32326748
想从事大数据、海量数据处理相关的工作,如何自学打基础?
https://www.zhihu.com/question/20176089
理解索引:HBase介绍和架构
https://mp.weixin.qq.com/s/WNmbHOW9t6rEEMKQ2Jx3hQ
自底向上——知识图谱构建技术初探
https://www.anquanke.com/post/id/149122
`
“The world is not made of strings , but is made of things.” ——辛格博士,from Google.
知识图谱,是结构化的语义知识库,用于迅速描述物理世界中的概念及其相互关系,通过将数据粒度从document级别降到data级别,聚合大量知识,从而实现知识的快速响应和推理。
1-定义
2-数据类型和存储方式
3-知识图谱的架构
3.1-逻辑架构
3.2-技术架构
4-构建技术
4.1-信息抽取
4.1.1-实体抽取
4.1.2-关系抽取
4.1.3-属性抽取
4.2-知识融合
4.2.1-实体链接
4.2.2-知识合并
4.3-知识加工
4.3.1-本体构建
4.3.2-知识推理
4.3.3-质量评估
4.4-知识更新
5-知识图谱的应用
智能搜索——也是知识图谱最成熟的一个场景,自动给出搜索结果和相关人物;
不一致性验证(类似交叉验证)——关系推理;
异常分析(运算量大,一般离线);
`
使用 Apache Spark 和 Elasticsearch 构建一个推荐系统
https://github.com/IBM/elasticsearch-spark-recommender/blob/master/README-cn.md
这两年在大数据行业中的工作总结
http://blog.jobbole.com/114185/
https://www.cnblogs.com/ztfjs/p/bigdata.html
HIVE中get_json_object与json_tuple使用
https://blog.csdn.net/sinat_29508201/article/details/50215351
Hive JSON数据处理的一点探索
https://www.cnblogs.com/yurunmiao/p/4728285.html
Hive get_json_object用法
https://sjq597.github.io/2015/11/05/Hive-get-json-object%E7%94%A8%E6%B3%95/
`
# 取内容为json字符串格式的 content 列的 status 字段的值
select get_json_object(content,’$.status’) from test limit 1;
`
Hive 中的复合数据结构简介以及一些函数的用法说明
https://my.oschina.net/leejun2005/blog/120463
从面试官的角度谈谈大数据面试
https://mp.weixin.qq.com/s/xX5lMAiqaA4-g63honeFbA
`
01 技术能力
这个是硬指标,不过关的基本是可以一票否决的,当然技术能力的标准是根据工作年限,面试职位和薪资要求共同来决定的。面试官要根据实际情况有自己的判断。
那技术能力如何考察?我提几个方面
基础能力
java 的 jvm、多线程、类加载等
scala 伴生对象,偏函数,柯里化等
还有shell和python的就不举例了
HBase读写流程
Yarn任务提交流程等等
底层原理
Hbase是如何存数据的,为什么读得快
spark为什么就算不在内存跑也比mr快
zookeeper数据怎么保证一致性
说说选举机制
等等
源码
有没有读过源码?
详细说下你从源码中获取到了什么信息,有什么帮助
架构设计能力
如何技术选型,考虑哪些因素?
设计一个同时满足实时和离线分析需求的平台
为什么这么设计?
另外
以上问题如果回答得不太好,可以再给个机会让他说下自己最熟悉的技术,不限制从哪些方面讲。
02 解决问题能力
如何排查hbase集群cpu过高问题
如何优化spark任务
……
03 方案设计能力
说说数据仓库设计建模过程
说说数据质量监控系统怎么设计
……
04 想法
这是一道开放题
对数据治理有什么想法
对职业生涯的规划
……
05 还可以再问些偏向管理的问题
如何调动组员的技术学习积极性
如何高效地跨部门协作
……
06 唠嗑
上面的问题问完觉得感觉可以的话可以,可以唠唠嗑,问些其他问题。
为何离职?
觉得自己是什么样的性格等等
当然这些都不太重要了主要就是考察下你的语言表达能力和三观是不是正的。
`
大数据技能图谱
https://mp.weixin.qq.com/s?__biz=MzA4Nzc4MjI4MQ==&mid=403428818&idx=1&sn=08a505f0204ea2edfb49925903a04a0a#rd
给SQL用户提供的一份简单但实用的Hive SQL备忘录(Simple Hive ‘Cheat Sheet’ for SQL Users)
https://zh.hortonworks.com/blog/hive-cheat-sheet-for-sql-users/
`
多表联合查询(Selecting from multiple tables)
# MySQL语法
SELECT pet.name, comment FROM pet, event WHERE pet.name = event.name;
# Hive SQL语法
SELECT pet.name, comment FROM pet JOIN event ON (pet.name = event.name);
描述表的格式
# MySQL语法
DESCRIBE table;
# Hive SQL语法
DESCRIBE (FORMATTED|EXTENDED) table;
删除数据库
# MySQL语法
DROP DATABASE db_name;
# Hive SQL语法
DROP DATABASE db_name (CASCADE);
`
系列:教你成为全栈工程师(Full Stack Developer)
http://www.shareditor.com/blogshow?blogId=2
教你成为全栈工程师(Full Stack Developer) 四十五-一文读懂hadoop、hbase、hive、spark分布式系统架构
http://www.shareditor.com/blogshow/?blogId=96
APACHE SENTRY
https://sentry.apache.org/
https://cwiki.apache.org/confluence/display/SENTRY/Sentry+Tutorial
Apache Sentry架构介绍
http://blog.javachen.com/2015/04/29/apache-sentry-architecture.html
安装和配置Sentry
http://blog.javachen.com/2015/04/30/install-and-config-sentry.html
Sentry部署,配置与使用
https://paper.tuisec.win/detail/eac7e109df10bdc
https://leibnizhu.gitlab.io/2018/03/07/Sentry%E9%83%A8%E7%BD%B2-%E9%85%8D%E7%BD%AE%E4%B8%8E%E4%BD%BF%E7%94%A8/
大数据平台CDH集群离线搭建
http://www.open-open.com/lib/view/open1453201603261.html
https://segmentfault.com/a/1190000004331498
`
以Apache Hadoop为主导的大数据技术的出现,使得中小型公司对于大数据的存储与处理也拥有了武器。目前Hadoop有不少发行版:华为发行版 收费、Intel发行版 收费、Cloudera发行版(Cloudera’s Distribution Including Apache Hadoop,简称 CDH)免费、Hortonworks发行版(Hortonworks Data Platform,简称 HDP)免费 等,所有这些发行版均是基于Apache Hadoop社区版衍生出来的。
对于国内而言,绝大多数选择CDH版本,主要理由如下:
(1)CDH对Hadoop版本的划分非常清晰,只有两个系列的版本(现在已经更新到CDH5.20了,基于hadoop2.x),分别是cdh3和cdh4,分别对应第一代Hadoop(Hadoop 1.0)和第二代Hadoop(Hadoop 2.0),相比而言,Apache版本则混乱得多;
(2)CDH文档清晰,很多采用Apache版本的用户都会阅读cdh提供的文档,包括安装文档、升级文档等。
`
Google后Hadoop时代的新“三驾马车”——Caffeine、Pregel、Dremel
https://www.csdn.net/article/2012-08-20/2808870
https://www.wired.com/2012/08/googles-dremel-makes-big-data-look-small/
`
Hadoop的火爆要得益于Google在2003年底和2004年公布的两篇研究论文,其中一份描述了GFS(Google File System),GFS是一个可扩展的大型数据密集型应用的分布式文件系统,该文件系统可在廉价的硬件上运行,并具有可靠的容错能力,该文件系统可为用户提供极高的计算性能,而同时具备最小的硬件投资和运营成本。
另外一篇则描述了MapReduce,MapReduce是一种处理大型及超大型数据集并生成相关执行的编程模型。其主要思想是从函数式编程语言里借来的,同时也包含了从矢量编程语言里借来的特性。基于MapReduce编写的程序是在成千上万的普通PC机上被并行分布式自动执行的。8年后,Hadoop已经被广泛使用在网络上,并涉及数据分析和各类数学运算任务。但Google却提出更好的技术。
在2009年,网络巨头开始使用新的技术取代GFS和MapReduce。Mike Olson表示“这些技术代表未来的趋势。如果你想知道大规模、高性能的数据处理基础设施的未来趋势如何,我建议你看看Google即将推出的研究论文”。
自Hadoop兴起以来,Google已经发布了三篇研究论文,主要阐述了基础设施如何支持庞大网络操作。其中一份详细描述了Caffeine,Caffeine主要为Google网络搜索引擎提供支持。
在本质上Caffeine丢弃MapReduce转而将索引放置在由Google开发的分布式数据库BigTable上。作为Google继GFS和MapReduce两项创新后的又一项创新,其在设计用来针对海量数据处理情形下的管理结构型数据方面具有巨大的优势。这种海量数据可以定义为在云计算平台中数千台普通服务器上PB级的数据。
另一篇介绍了Pregel,Pregel主要绘制大量网上信息之间关系的“图形数据库”。而最吸引人的一篇论文要属被称之为Dremel的工具。
`
知识图谱发展的难点&构建行业知识图谱的重要性
https://paper.tuisec.win/detail/1e9aa1c785fbae7
http://www.woshipm.com/it/1716953.html
`
知识图谱又称为科学知识图谱,在图书情报界称为知识域可视化,或知识领域映射地图,用来显示知识发展进程与结构关系的一系列各种不同的图形,用可视化技术描述知识资源及载体,挖掘、分析、构建、绘制和显示知识及他们互相之间的关系。
一、概述
尽管人工智能依靠机器学习和深度学习取得了快速进展,但这些都是弱人工智能,对于机器的训练,需要人类的监督以及大量的数据来喂养,更有甚者需要人手动对数据进行标记,对于强人工智能而言,这是不可取的。要实现真正的类人智能,机器需要掌握大量的常识性知识,以人的思维模式和知识结构来进行语言理解、视觉场景解析和决策分析。
二、什么是知识图谱
百度百科定义:知识图谱又称为科学知识图谱,在图书情报界称为知识域可视化,或知识领域映射地图,用来显示知识发展进程与结构关系的一系列各种不同的图形,用可视化技术描述知识资源及载体,挖掘、分析、构建、绘制和显示知识及他们互相之间的关系。
三、为什么需要知识图谱
四、知识图谱的诞生
五、知识图谱的原理
六、知识图谱的发展方向
七、行业知识图谱的重要性
`
大数据和分布式经典论文汇总
https://www.iteblog.com/archives/2021.html
`
文章目录
1 分布式理论
2 一致性
3 Google
4 通用计算框架
5 Streaming
6 消息队列
7 KV Database & Database
8 Schedulers
9 Storages
10 协调
11 其他
`
大数据发展史|大数据
https://mp.weixin.qq.com/s/g-1OWKEL0IoqCX1oqCpSXQ
`
一、大数据技术产生史
首先看一下我们要介绍的大数据技术栈包含什么:
Hadoop; MapReduce; NoSQL; Spark; Flink; Hive….
这个都属于大数据的技术栈,初看起来,杂乱无章。对于初学者更甚,无从下手,更不知道哪些是重点,哪些是辅助技术。
所以,我们先把这些技术的产生搞清楚,以及他们能应用什么场景。这样你就做到心里有数,剩下的就是各个击破,自己慢慢学习。
# 起源于Google
大家都知道最早搜索引擎是Google.其功能是提供互联网用户的信息的检索功能。那搜索引擎具体都干了哪些事呢?
其实很简单的两件事:
一是数据采集,也就是网页的爬取;
二是数据搜索,也就是索引的构建;
数据采集离不开存储,索引的构建也需要大量计算,所以存储容器和计算能力贯穿搜索引擎的整个更迭过程。
在2004年前后,Google发表了三篇重要的论文,俗称“三驾马车”:
GFS
MapReduce
BigTable
在互联网早期,互联网产品用户规模都不是很大,很少的人会关注分布式解决方案,都在单体机器上寻找解决方案,也就是在硬件上下功夫;
而Google在当时的互联网界,不管是用户规模还是所产生数据量都是TOP级别的。所以,对分布式和集群等方式,解决存储方式研究较早,同时也采用横向拓展的思路,去研发系统。
# Hadoop的产生
最早关注 Google 大数据论文的是一个程序员,也不陌生,Lucene项目的创始人 Doug Cutting。他看到论文后,颇为激动,程序员,动手能力当然很强,很快就依据论文的原理实现了类似 GFS 和 MapReduce的功能框架。注意是类似哦。
到了2006年,DC 开发的类似MapReduce功能的大数据技术,被独立出来,单独开发运维。这个也就是不就后被命名为 Hadoop 的产品。 该体系里面包含,大家熟知的分布式文件系统 HDFS 以及大数据计算引擎 MapReduce。
# Yahoo 优化改编
当 Hadoop 发布之后,另一个当时的搜素引擎巨头 Yahoo 很快就使用了起来;
到了2007年,国内的百度也开始使用了 Hadoop 进行大数据存储与计算了。
又过了一年,2008年,Hadoop 正式成为 Apache 的顶级项目,自此,Hadoop 彻底火了起来,也被更多的人熟知。
当然任何系统都不可能是完美的,也不可能是通用的,并非适用于每个公司。 Yahho 使用了 MapReduce 进行大数据计算时,觉得开发太繁琐,于是他们自己便开发了一个新的系统–Pig。
Pig是一个基于 Hadoop 类 SQL 语句的脚本语言。经过编译后,直接生成 MapReduce 程序,在 Hadoop系统上运行。所以 Yahho 也是在Hadoop 基础上进行了 编程上的优化使用。
# Facebook 的数据分析 Hive
Yahho 的 Pig 是一种类似于 SQL 语句的脚本语言,相比于直接编写 MapReduce 简单许多。但是使用者还是要学习这种新的脚本语言。
又一家巨头公司出现了 Facebook 为了数据分析也开发一种新的分析工具,叫做 Hive 的东西,hHive 能直接使用SQL语句进行大数据计算,这样,只要是具有数据库关系型语言的开发人员就能直接使用大数据平台。大大的降低了使用的门槛,又将大数据技术推进了一步。
至此,大数据主要的技术栈基本形成。包括 HDFS、MapReduce、Pig、Hive.
# 责任单一 Yarn
此时,MapReduce 一个资源调度框架,又是一个执行引擎。为了责任单一化,将这两种功能进行了分离,Yarn 项目启动了。
2012年, Yarn 成为了独立的项目,开始运营,被各大数据厂商的产品支持,成为了主流的资源管理调度系统。
# 效率还是效率 Spark
同年,UC 伯克利 AMP 实验室的一位博士,在使用 MapReduce 进行大数据实验计算时,发现性能非常差,不能满足其计算需求。
为了改进这种效率低下的工作方式,于是开发出了一个性能优越的替代产品,叫做 Spark 。由于Spark 性能卓著,一经推出,就受到了业界的认可,开始全面替代 MapReduce。
# 批处理计算和流式计算
大数据计算根据分析数据的方式不同,有两个类别。一种叫做批处理计算,比如 MapReduce、Spark 这种,针对的是某个时间段的数据进行计算(比如“天”“小时”的单位)。
这种计算由于数据量大,需要花费几十分钟甚至更长。同时这种计算的数据是非在线实时获取的数据,也就是历史积累的数据,也就是离线数据,这种计算又被称为“离线计算”。
离线计算针对的是历史数据,相对的就有针对的实时数据进行计算,也就是系统接收到数据就进行计算,这种计算叫做“流式计算”。
由于处理的数据是实时在线产生的,又被称为“实时计算”。
# 流式计算技术 Storm、Flink、 Spark Streaming
怎么理解流式计算呢?很简单的,把批处理计算的时间单元缩小到数据产生的间隔就是了。“流式计算”具有代表性的框架,比如:Storm、Flink、 Spark Streaming。
特别说一点,Flink 就牛了一些,既支持流式计算又支持批处理计算。
# 非关系型数据库
在2011年 左右 NoSQL 非常火爆,其中 HBase 是从Hadoop中分拆出去的,也就是底层还是HFDS 技术。所以 NoSQL 系统在大数据环境下,提供海量数据的存储和访问功能,也算是大数据技术栈一员。
# 数据分析,数据挖掘,机器学习
有了大数据这个底层的技术基础,更广的应用也就能实现了。大数据平台,继承了数据分析和数据挖掘技术,以及在大数据基础上,更高级的机器学习技术。
数据分析主要是数据专员的工作,一般不需要开发能力,会使用简单的 SQL 基本上够用了。一些公司的运营人员,也要求具有数据分析的能力。数据分析主要是利用上面提到的 Hive、Spark SQL 等 数据库脚本语言;
有了大数据的存储和计算能力,就能进行数据挖掘和机器学习。当然也有成熟的框架,比如Mahout、Google 的 TersorFlow等框架。
最后,有了基础的存储功能,大数据批处理,流失处理计算能力,之上的大数据分析,以及更高级的挖掘和机器学习。至此一个大数据平台就构成了。
`
院士张钹:AI奇迹短期难再现 深度学习技术潜力已近天花板
https://mp.weixin.qq.com/s/HVA7dvvwVA0f-Krm1Vscjw
http://m.eeo.com.cn/2019/0524/356928.shtml
`
在Alphago与韩国围棋选手李世石对战获胜三年过后,一些迹象逐渐显现,张钹院士认为到了一个合适的时点,并接受了此次的专访。
张钹,计算机科学与技术专家,俄罗斯自然科学院外籍院士、中国科学院院士,清华大学教授、博士生导师,现任清华大学人工智能研究院院长。
深度学习目前人工智能最受关注的领域,但并不是人工智能研究的全部。张钹认为尽管产业层面还有空间,但目前基于深度学习的人工智能在技术上已经触及天花板,此前由这一技术路线带来的“奇迹”在Alphago获胜后未再出现,而且估计未来也很难继续大量出现。技术改良很难彻底解决目前阶段人工智能的根本性缺陷,而这些缺陷决定了其应用的空间被局限在特定的领域——大部分都集中在图像识别、语音识别两方面。
同时,在张钹看来,目前全世界的企业界和部分学界对于深度学习技术的判断过于乐观,人工智能迫切需要推动到新的阶段,而这注定将会是一个漫长的过程,有赖于与数学、脑科学等结合实现底层理论的突破。
作为中国少有的经历了两个人工智能技术阶段的研究者,张钹在过去数年鲜少接受采访,其中一个原因在于他对目前人工智能技术发展现状的估计持有部分不同看法,在时机未到之时,张钹谨慎的认为这些看法并不方便通过大众媒体进行传播,即使传播也很难获得认同。
“现在很多方面大家看的比较清楚,已露出苗头来了,我现在也接触到很多企业,找我谈这个问题,说明企业在第一线已经发现了很多问题,就想找个机会稍微说说。”张钹对经济观察报表示。
一、“奇迹并没有发生,按照我的估计,也不会继续大量发生”
二、“深度学习技术,从应用角度已经接近天花板了”
三、“我们培养不出爱因斯坦、培养不出图灵”
四、“低潮会发生,但不会像过去那样”
`
大数据分析入门课程8–Spark基础
https://mp.weixin.qq.com/s/xbOOGlV6ISqk48-AaSzPAw
`
为什么讲Spark?
随着并行数据分析变得越来越流行,各行各业的使用者们迫切需要更好的数据分析工具,Spark 应运而生。作为MapReduce的继任者,Spark具备以下优势特性。
1.高效性
2.易用性
3.通用性
4.兼容性
本文的主要目标是什么?
学习完本文,你将会对如何使用Spark完成数据分析工作有一个更深入的理解。
本文的讲解思路是什么?
第1部分,主要讲解Spark相比MapReduce的优势。
第2部分,主要跟大家一起来看下Spark生态系统具体包括哪些组成部分。
第3部分,针对Spark的三种主要数据组织类型进行一一介绍、对其三者之间的异同点进行总结以及给出三者之间转化的方式。
第4部分,共享变量,包括广播变量和累加器。
第5部分,主要介绍Spark中使用YARN进行资源管理时,任务的提交流程和方式。
`
大数据平台常见开源工具集锦(强烈推荐收藏)
https://mp.weixin.qq.com/s?__biz=MzA5MTc0NTMwNQ==&mid=2650717098&idx=1&sn=477da3a0c45418d1dab1c1d56c244647
`
本文整理了大数据平台常见的一些开源工具,并且依据其主要功能进行分类,以便大数据学习者及应用者快速查找和参考。
语言工具类
数据采集类工具
ETL工具
数据存储类工具
分析计算类工具
查询应用类工具
数据管理类工具
运维监控类工具
`
一份超详细的 Spark 入门介绍
https://mp.weixin.qq.com/s/Wh6ZpV07P1cGGV-dfsJanQ
`
本文来自近期的一次 Spark 内部分享,内容主要包括 Spark RDD 的重点介绍, 以及 Spark 核心模块 DAGScheduler、TaskScheduler、BlockManager 等讲解,内容充实。如下:
Spark简介及总体流程
Spark核心模块的实现
Spark应用库
Spark与Hadoop的区别与联系
Spark应用
`
一起学习阿里巴巴数据中台实践!首次公开!
https://mp.weixin.qq.com/s/izyOp73o_6RiXzJOjHVjtQ
读透《阿里巴巴数据中台实践》,其到底有什么高明之处?
https://mp.weixin.qq.com/s/zVgXeBsBGDCGSk8_JnCnCg
阿里数据科学家一次讲透数据中台,15页PPT精华,速转走!
https://mp.weixin.qq.com/s/SBfb1LlMR3iDRYl9-IEEQA
有别于BATJ,滴滴的中台数据体系建设怎么另辟蹊径?
https://mp.weixin.qq.com/s/Ounubq5J0U5ijQsFgQZU0A
`
1、滴滴数据中台发展
2、滴滴精益数据管理体系
3、滴滴数据系统组成
4、中台是买不来的
任何一个中台,不管是技术中台、AI中台,本质上为了更好支撑业务,让业务能够更好的去把用户价值做出来。从技术角度来讲创造价值的核心就是两点:
1. 保证稳定且持续的研发生产持续输出既有价值;
2. 在生产过程中去找到可以改进的地方,找到新的创新点,创造更大的新价值。
一、滴滴数据中台发展
1、业务发展驱动数据进化
1)业务信息化
2)信息数据化
3)数据资产化
4)资产变现化
2、中台数据体系建设的核心困难
关键的两个一个是持续改进,我们认为数据平台、数据体系或者数据中台不是一天能够建成的,也不是一个大项目做了数据治理,做了数据资产管理,这事就完事了,很多企业,尤其是传统产业企业领导觉得数据这件事情交给CIO或者数据平台的领导者就好了,把这个数据弄好,后面就好了,其实不是这样子的。数据是跟着业务在发展和生产的,必须得持续改进才能跟上业务的节奏。
数据本质上背后是人,人用数据,人开发的AI用数据,我们必须得尊重人,尊重人是什么样的意思?尊重人的创意,我们应该让每一个人都有机会平等用上数据,所以要把这个门槛降到最低。
第二个数据的链路里面涉及到的方方面面各种各样的人,我们一定要让每一个链路中的人意识到,你做的任何一件事情都有可能会影响到上游或者下游,那核心价值观是不要给别人添麻烦,客户第一。以这个为基础的价值观遇到很多问题的时候,我们就回到这样的初心,再来看怎么做持续改进。
`
i 技术会笔记 | Druid在爱奇艺的实践和技术演进
https://mp.weixin.qq.com/s/nzwRFoFt_rumfgktlMfF6A
`
最近几年大数据技术在各行各业得到广泛应用,为企业的运营决策和各种业务提供支持。随着数据的增长,业务对数据时效性的要求,给企业的大数据分析带来了巨大挑战。针对海量数据的实时分析需求,近年来市场上涌现出众多OLAP分析引擎。这些OLAP引擎有各自的适用场景和优缺点,如何选择一款合适的引擎来更快地分析数据、更高效地挖掘数据的潜在价值?
爱奇艺大数据服务团队评估了市面上主流的OLAP引擎,最终选择Apache Druid时序数据库来满足业务的实时分析需求。本文将介绍Druid在爱奇艺的实践情况、优化经验以及平台化建设的一些思考。
爱奇艺大数据OLAP服务在2015年前主要以离线分析为主,主要基于Hive+MySQL、HBase等。2016年起引入Kylin和Impala分别支持固定报表和Ad-hoc查询。2018年以来引入Kudu和Druid支持实时分析需求。
在引入Druid之前,业务的一些场景无法通过离线分析满足,如广告主想要实时基于投放效果调整投放策略、算法工程师调整模型推到线上A/B要隔天离线报表才能看到效果。这些场景都可以归纳为对海量事件流进行实时分析,经典的解决方案有如下几种:
* 离线分析:
使用Hive、Impala或者Kylin,它们一个共同的缺点是时效性差,即只能分析一天或者一小时前的数据,Kylin还面临维度爆炸的问题
* 实时分析:
用ElasticSearch或OpenTSDB,由于数据结构本质是行存储,聚合分析速度都比较慢;可以通过查询缓存、OpenTSDB预计算进行优化,但不根本解决问题;
用流任务(Spark/Flink)实时地计算最终结果,存储在MySQL提供进一步服务;问题是每当需求调整,如维度变更时,则需要写新的流任务代码;
使用Kudu和Impala结合能够做到实时分析。在实践过程中发现,Kudu受限于内存和单机分区数,支撑海量数据成本很大;
* Lambda架构:
无论选用哪种实时或离线方案的组合,都会采用Lambda架构,用离线数据校准实时数据。这意味着从摄入、处理、查询都需要维护两套架构,新增一个维度,离线和实时均需对应修改,维护困难
以上种种方案的不足,促使我们寻找新的解决方案,最终决定采用Druid。
`
大数据技术漫谈 ——从Hadoop、Storm、Spark、HBase到Hive、Flink、Lindorm
https://juejin.cn/post/7002789591748968479
`
@2021-09-01
基于以上个人经历,我想简单讲讲最近五年间大数据领域技术栈的演进史,并对其中提到的部分关键技术做展开说明。
本文重点在于总括性的概述,部分论点来源于个人使用经历,并不是行业公认的结论,如有谬误欢迎指正。
一、前言
二、大数据技术划分
三、大数据技术历史演进
3.1 流式计算历史演进 — 目前主流的流式计算框架有Storm/Jstorm、Spark Streaming、Flink/Blink三种。
3.2 离线计算历史演进 — 离线计算领域主要有Hadoop MapReduce、Spark、Hive/ODPS等计算框架。
3.3 列式存储NOSQL数据库历史演进 — NOSQL的概念博大精深,有键值(Key-Value)数据库、面向文档(Document-Oriented)数据库、列存储(Wide Column Store/Column-Family)数据库、图(Graph-Oriented)数据库等,本章节主要讲述列存储数据库中最流行的HBase及其替代品Lindorm。
3.4 大数据开发语言历史演进
3.5 大数据学习建议
四、云原生多模数据库Lindorm介绍
4.1 Lindorm介绍
4.2 Lindorm与MySQL对比
4.3 Lindorm与HBase对比
4.4 Lindorm实战的一些坑
4.4.1 Lindorm 二级索引
4.4.2 Lindorm 超大分页
4.4.3 Lindorm region划分
4.5 Lindorm相关QA
4.6 Lindorm总结
五、流批一体——大数据计算引擎Fink介绍
5.1 Flink介绍
5.2 Blink介绍
5.3 Flink与Blink对比
5.4 Flink使用
5.4.1 创建数据源表
5.4.2 创建数据结果表
5.4.3 编写业务逻辑
5.4.4 性能调优
5.5 Flink优点
六 、大数据在字节跳动
6.1 数据平台
6.2 存储系统
七、结语
参考文献
==
在国外一些社区,有很多人将大数据的计算引擎分成了 4 代。
第一代计算引擎,无疑是Hadoop MapReduce。它将计算分为两个阶段,分别为 Map 和 Reduce。上层应用需要自己手写map任务和reduce任务。
第二代计算引擎,支持 DAG(有向无环图) 的框架: Tez ,主要还是批处理任务
第三代计算引擎,以 Spark 为代表,特点主要是 Job 内部的 DAG 支持(不跨越 Job),以及强调的实时计算。
第四代计算引擎,以Flink、Blink为代表,一统批流,支持DAG运算,并具备进一步的实时性。
自 Google Dataflow 模型被提出以来,流批一体就成为分布式计算引擎最为主流的发展趋势。流批一体意味着计算引擎同时具备流计算的低延迟和批计算的高吞吐高稳定性,提供统一编程接口开发两种场景的应用并保证它们的底层执行逻辑是一致的。对用户来说流批一体很大程度上减少了开发维护的成本,但同时这对计算引擎来说是一个很大的挑战。虽然 Spark 是最早提出流批一体理念的计算引擎之一,但由于其本质还是基于批(mini-batch)来实现流,在流计算语义和延迟上存在硬伤,难以满足复杂、大规模实时计算场景的极致需求。
Flink 遵循 Dataflow 模型的理念: 批处理是流处理的特例。不过出于批处理场景的执行效率、资源需求和复杂度各方面的考虑,在 Flink 设计之初流处理应用和批处理应用尽管底层都是流处理,但在编程 API 上是分开的。这允许 Flink 在执行层面仍沿用批处理的优化技术,并简化掉架构移除掉不需要的 watermark、checkpoint 等特性。
`