=Start=
缘由:
想整理一下最近看到的或是想到的关于系统可用性衡量的一些指标,一方面是在整理中学习,另一方面是为了方便以后检索和参考。
正文:
参考解答:
1. MTBF——全称是Mean Time Between Failure,即平均无故障工作时间。就是从新的产品在规定的工作环境条件下开始工作到出现第一个故障的时间的平均值。MTBF越长表示可靠性越高、正确工作能力越强 。
2. MTTR——全称是Mean Time To Repair,即平均修复时间。是指可修复产品的平均修复时间,就是从出现故障到修复中间的这段时间。MTTR越短表示易恢复性越好。
3. MTTF——全称是Mean Time To Failure,即平均失效时间。系统平均能够正常运行多长时间,才发生一次故障。系统的可靠性越高,平均无故障时间越长。
MTBF = MTTF + MTTR
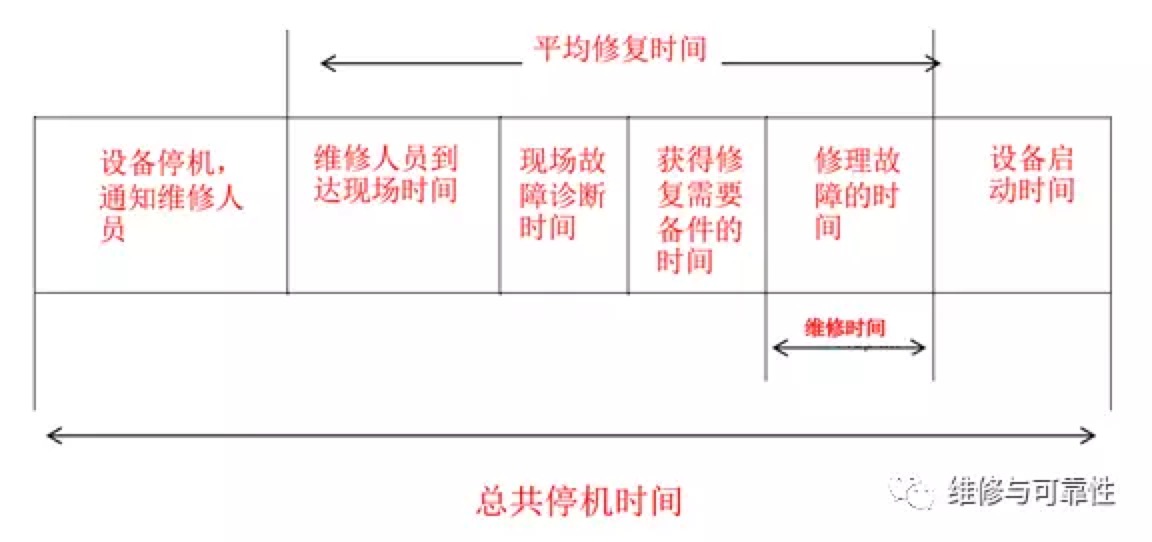
&

- 发现时长/发现方(Meam Time To Detect/Identify)
- 响应时长/事故处理流程(Mean Time To Response)
- 定位时长/定位方(Mean Time To Diagnose)
- 处理时长/处理方(Mean Time To Fix)
- 影响时长/影响方(Mean Time To Resolve)
- 损失/定级
可靠性是最初是确定一个系统在一个特定的运行时间内有效运行的概率的一个标准。可靠性的衡量需要系统在某段时间内保持正常的运行。
目前,使用最为广泛的一个衡量可靠性的参数是,MTTF(mean time to failure,平均失效时间),定义为随机变量、出错时间等的”期望值”。但是,MTTF经常被错误地理解为,”能保证的最短的生命周期”。MTTF的长短,通常与使用周期中的产品有关,其中不包括老化失效。
可用性Availability = MTBF / (MTBF + MTTR),一般我们都是用N个9来表达系统可用性,用宕机时长来说更好理解,如果以全年为周期(24*365=8760个小时),3个9(99.9%)就意味着全年宕机时长是525.6分钟,4个9(99.99%)是52.6分钟,5个9(99.999%)是5分钟。用直观的数据展示如下:
| 可用性 | 宕机时间 |
| 99.9999% (6个9) | 31秒/年 |
| 99.999% (5个9) | 5分钟/年 |
| 99.99% (4个9) | 52分钟/年 |
| 99.9% (3个9) | 8.76小时/年 |
参考链接:
=END=
《 “系统可用性衡量指标学习” 》 有 10 条评论
十条军规 | 亚马逊CTO对过去十年的经验总结
https://mp.weixin.qq.com/s/mV6uK9gmUJWTsHvhVds-MQ
AWS CTO对过去十年的经验总结 – 十条军规
https://aws.amazon.com/cn/blogs/china/10-lessons-from-10-years-of-aws/
AWS CTO:别等待完美了,不断从错误中学习
https://mp.weixin.qq.com/s/TQVR4JW3mYHPQl4gNK1dkg
亚马逊 CTO:云架构师都应该知道的六大定律
https://mp.weixin.qq.com/s?__biz=MjM5MzM3NjM4MA==&mid=216101937&idx=2&sn=6f8b260b942ef76a7db142a65b64a70d&scene=21
`
1.卢卡斯批判(Lucas Critique)
“如果完全依赖历史数据中观察到的关系,就预测变化的影响,这是很幼稚的做法。”
2.盖尔定律(Gall’s Law)
“一个切实可行的复杂系统势必是从一个切实可行的简单系统发展而来的。从头开始设计的复杂系统根本不切实可行,无法修修补补让它切实可行。你必须由一个切实可行的简单系统重新开始。”
3.迪米特法则(Law of Demeter)
“每个软件单位对其他单位应该都只有最少的知识,而且局限于那些与本单位密切相关的单位。每个软件单位应该只与它的朋友说话;不要与陌生人说话。”
4.奥卡姆剃刀定律(Occam’s Razor)
“需要最少假设的那个解释应该被选中。”
5.里德定律(Reed’s Law)
“大型网络、尤其是社交网络的功效会随着网络规模呈指数级增加。”
6.格式塔原理(The Gestalt Principle)
“整体大于部分之和。”
`
大众点评账号业务高可用进阶之路
https://mp.weixin.qq.com/s/Hl05RVxmcea5RRkNjm6upg
`
衡量一个系统的可用性有两个指标:
1. MTBF (Mean Time Between Failure)即平均多长时间不出故障;
2. MTTR (Mean Time To Recovery)即出故障后的平均恢复时间。
通过这两个指标可以计算出可用性,也就是我们大家比较熟悉的“几个9”。
因此提升系统的可用性,就得从这两个指标入手,要么降低故障恢复的时间,要么延长不出故障的时间。
`
系统可用性量表 SUS
https://www.biaodianfu.com/sus-system-usability-scale.html
http://www.usabilitynet.org/trump/documents/Suschapt.doc
http://www.measuringusability.com/sus.php
那些年,云厂商宕机教会我们的事
https://mp.weixin.qq.com/s/qBgcmwk-YODjrOKPV5iK2Q
`
云厂商宕机故障,这些年一直不是什么新闻。
纵观以上云厂商宕机案例,有的是天灾(机房被雷劈了),有的是人祸(误删除操作),但可以肯定的是:宕机这事儿,预计在很长的一段时间里都无法避免。那么对于吃瓜群众们来说,看完热闹了,要看会什么门道呢?
要注意Error Handling
尽可能地把动态内容缓存起来,甚至静态化
云用户应检查核心依赖关系,提升关键性服务的冗余水平
故障演习很重要
处理危机的方式能看出一个公司的高度
`
少年,MTBF 和 MTTR 了解下!
https://mp.weixin.qq.com/s/SHDtek4YVEgjCxOn3y-6Kg
`
先上两个概念,
MTBF :Mean Time Between Fail,粗暴的翻译下,平均出错间隔。拿软件来举例,MTBF 就是出 bug 的平均时间间隔;MTBF 越大,说明你的软件的质量越好,因为很久才出一个 bug。
再来第二个概念,
MTTR:Mean Time To Repair, 平均修复的时间。这个在软件行业最好理解,出了一个 bug 平均的修复时间,这个值越小越好,侧面也体现了软件的质量好。小结下: 一个产品它的 MTBF 越大越好,MTTR 越小越好。
`
线上故障处理手册
https://mp.weixin.qq.com/s/rkmkC3Ef99Ckj78_zs2G7g
`
通常处理线上问题的三板斧是 重启-回滚-扩容,能够快速有效的解决问题,但是根据我多年的线上经验,这三个操作略微有些简单粗暴,解决问题的概率也非常随机,并不总是有效。这边总结下通常我处理应用中遇到的故障的解决方案。
# 处理故障的时候必须遵循的一些原则
提早发现问题,避免故障扩散
迅速广播
快速恢复
持续观察
# 处理手段
处理手段无非是重启、扩容、回滚、限流、降级、hotfix
step1: 是否有变化
step2: 是否单机
step3: 是否集群
step4: 依赖的服务/存储有问题
# 如何预防
* 了解你的服务
* 压测演练
* 定期盘点
* 监控警报
`
如何提升系统可用性?
https://insights.thoughtworks.cn/how-to-improve-system-availability/
`
# 如何提高系统可用性
影响系统可用性的因素很多,以上列举了一些非常典型的场景,这足以让我们对影响可用性的因素有一个非常直观的理解。为了从可实施的角度讨论如何提高系统可用性,这里不考虑基础设施硬件故障等不可控因素。
从上面的因素中我们不难发现,有些问题我们可以通过提高工程化能力和优化工作流程解决,但如何将这些工程化能力和流程落地也是一个非常复杂的问题,因此我下面会通过技术和团队两个视角来看如何才能提高系统的可用性。
## 从技术视角,要不断强化工程能力
根据可用性的定义,要提高系统的可用性,就是要缩短系统不可用的时长,保持系统的健康状态;那么回顾下文章开头的小故事,我们可以从三个阶段来针对性的采取一些措施:
病发前:
* 完善的代码质量管理体系和自动化测试体系,能够保证产品质量,通过代码检查、安全扫描和测试自动化,避免未经测试的代码部署到生产环境
* 完善的权限管理体系,能够保证生产环境权限不滥用,避免过多的人为操作对生产环境产生影响
* 其他自动化的开发、运维工具体系,在提高工作效率的同时,注重安全性,通过自动化的脚本检查、运维流程自动化等方式避免不必要的错误对生产环境造成的危害
病发初期:
* 完善的监控体系,能够尽早识别系统的潜在问题,系统运营人员可以快速甄别即将发生的故障,不要等到用户反馈才知道系统出了问题
* 完善的持续集成/持续部署体系,能够保证尽量快的反馈,尽量短的发布时长,在功能开发和故障修复后快速地部署代码到生产环境
病情严重:
* 完善的发布验证、回滚、限流、熔断、降级策略,能够尽量缩小故障的影响范围,保证即便有部分服务不稳定,也不至于导致整个系统不可用
* 完善的灾备恢复体系和演练,能够保证系统在发生重大紧急事故时可以快速恢复,尽量缩短不可用时长
## 从团队视角,要有一支重视技术的团队
在软件系统的开发运维过程中,我们有很多手段可以发现问题,如线上故障、监控报警、回顾会议等等,但从根本上解决问题往往非常困难,大多数情况下是头痛医头,脚痛医脚,到最后结果就是技术债台高耸,线上故障频发;即便找到了解决问题的办法,在实施的过程中还会遇到很多问题。
探究其原因,可能比较复杂 ,但从团队视角来看,通常存在团队对待技术并没有那么严谨,对待生产环境没有那么敬畏,对待自己的代码没有那么严苛。
要提升系统的可用性,必须要有一支重视技术的团队,这个团队应该具备以下特征:
* 自上而下崇尚技术,尊重技术
* 有专家级成员,有能力实施上面提到的各种工程能力
* 不急功近利,不会为了短期的业务目标而在技术上妥协
* 团队成员遵守团队纪律,不做违反纪律,破坏规则的事情
# 结语
追求系统的高可用就像一个人追求身体健康一样,整个软件开发团队自始至终都要秉持爱护软件系统的心态,在软件开发的全流程中,时刻保持警惕,通过提高团队在三个阶段中的工程化能力来及时发现和解决系统中存在的问题。
这不单纯是个技术问题,善治系统的团队首先要在团队内建立尊重技术、工程的文化氛围,建立团队行为规范,严明纪律,有所为有所不为;在此基础上,不断在团队开发过程中针对问题寻找解决问题的最佳实践,做且做好正确的事,相信高可用是必然的结果。
`
降低APP卸载率,测试人员可以做些什么?
https://mp.weixin.qq.com/s/ogiOlV-eXkDFlGEp-pLgMQ
`
《增长黑客》中提出一个公式:“转化 = 欲望 – 摩擦”,所有让用户感觉不舒服的地方,都会带来一定的“摩擦”,如果摩擦大于用户的使用欲望,用户就会离开。根据各大应用商店的研究表明,安装应用后的30天内,大部分用户会卸载APP,平均只有不到30%的用户留存下来,导致用户离开的top10原因为:
•APP功能对自己没用,不能满足期望
•太多的烦人推送 & 侵入式广告
•经常Crash、卡顿或卡死
•包体积太大
•申请太多的授权
•耗流量、耗电、耗内存
•加载时间太长,对网速过度依赖
•有更好用的竞对APP
•隐私问题
•易上瘾、套路多
以上可归纳出,“隐私安全”、“实用性”、“性能”、“体验”是用户遇到的四个主要摩擦,因此测试团队要做的事情就是:如何从质量的视角来降低这四个方面的摩擦。
# 建立改善模型
要消除摩擦,首先需要建立一个可以指导我们改进的模型,APP在用户手机中能否存活,取决用户主观感受,也就是我们常说的“用户体验”,下图借鉴了马斯洛人类需求层次结构,抽象出来APP的体验层次金字塔模型,从塔底到塔顶,分为五个层次:安全性、功能性、稳定性、易用性、愉悦性,每个层次都在前面的基础之上提出了更高的期待,随着层次的升高,APP的用户粘性逐步增强,就像人类的生存条件一样,APP能否在用户的手机上存活,取决于满足了低层次功能需求之上高层次精神需求。
# 具体改善措施
隐私安全是底座
跳出功能测试“陷阱”
重视全链路性能
引入可用性测试
# 总结与展望
让用户感受到产品的诚意,是质量团队的第一目标,测试作为整个研发环节的最后交棒人,需要在每个细节上下功夫。未来闲鱼测试团队会继续基于APP体验模型,持续投入APP体验方面的测试,同时在智能化适配、精准测试等方面做一些突破,期望为用户留存做更多的贡献。
`
Figure III-1. Service Reliability Hierarchy
https://sre.google/sre-book/part-III-practices/
`
从低到高
1. 监控 – Monitoring 监控是后面的基础,也即没有日志,后面的事件响应、根因分析还有其它方式都是扯淡
2. 事件响应 – Incident Response
3. 事后分析和根本原因分析 – Postmortem and Root-Cause Analysis
4. 测试 – Testing
5. 容量规划 – Capacity Planning
6. 开发 – Development
7. 产品 – Product
`