=Start=
缘由:
收集整理一些软件编程方面的规范,方便需要的时候快速参考。
正文:
参考解答:
军规一:【避免在程序中使用魔鬼数字,必须用有意义的常量来标识。】
军规二:【明确方法的功能,一个方法仅完成一个功能。】
军规三:【方法参数不能超过5个。】
军规四:【方法调用尽量不要返回null,取而代之以抛出异常,或是返回特例对象(SPECIAL CASE object,SPECIAL CASE PATTERN);对于以集合或数组类型作为返回值的方法,取而代之以空集合或0长度数组。】
军规五:【在进行数据库操作或IO操作时,必须确保资源在使用完毕后得到释放,并且必须确保释放操作在finally中进行。】
军规六:【异常捕获不要直接catch (Exception ex) ,应该把异常细分处理。】
军规七:【对于if „ else if „(后续可能有多个else if …)这种类型的条件判断,最后必须包含一个else分支,避免出现分支遗漏造成错误;每个switch-case语句都必须保证有default,避免出现分支遗漏,造成错误。】
军规八:【覆写对象的equals()方法时必须同时覆写hashCode()方法。】
军规九:【禁止循环中创建新线程,尽量使用线程池。】
军规十:【在进行精确计算时(例如:货币计算)避免使用float和double,浮点数计算都是不精确的,必须使用BigDecimal或将浮点数运算转换为整型运算。】
军规说明
军规一:【避免在程序中使用魔鬼数字,必须用有意义的常量来标识。】
说明:是否是魔鬼数字要基于容易阅读和便于全局替换的原则。0、1作为某种专业领域物理量枚举数值时必须定义常量,严禁出现类似NUMBER_ZERO的“魔鬼常量”。
军规二:【明确方法的功能,一个方法仅完成一个功能。】
说明:方法功能太多,会增加方法的复杂度和依赖关系,不利于程序阅读和将来的持续维护,无论是方法还是类设计都应符合单一职责原则。
军规三:【方法参数不能超过5个】
说明:参数太多影响代码阅读和使用,为减少参数,首先要考虑这些参数的合理性,保持方法功能单一、优化方法设计,如果参数确实无法减少,可以将多个参数封装成一个类(对象),同时考虑在新的类(对象)中增加相应的行为,以期更符合OOP。
军规四:【方法调用尽量不要返回null,取而代之以抛出异常,或是返回特例对象(SPECIAL CASE object,SPECIAL CASE PATTERN);对于以集合或数组类型作为返回值的方法,取而代之以空集合或0长度数组。】
说明:返回null会增加不必要的空指针判断,遗漏判断也会导致严重的NullPointerException错误。
军规五:【在进行数据库操作或IO操作时,必须确保资源在使用完毕后得到释放,并且必须确保释放操作在finally中进行。】
说明:数据库操作、IO操作等需要关闭对象必须在try -catch-finally 的finally中close(),如果有多个IO对象需要关闭,需要分别对每个对象的close()方法进行try-catch,防止一个IO对象关闭失败其他IO对象都未关闭。
军规六:【异常捕获不要直接 catch(Exception ex) ,应该把异常细分处理。】
说明:catch (Exception ex)的结果会把RuntimeException异常捕获,RuntimeException是运行期异常,是程序本身考虑不周而抛出的异常,是程序的BUG,如无效参数、数组越界、被零除等,程序必须确保不能抛出RuntimeException异常,不允许显示捕获RuntimeException异常就是为了方便测试中容易发现程序问题。
军规七:【对于if „ else if „(后续可能有多个elseif …)这种类型的条件判断,最后必须包含一个else分支,避免出现分支遗漏造成错误;每个switch-case语句都必须保证有default,避免出现分支遗漏,造成错误。】
军规八:【覆写对象的equals()方法时必须同时覆写hashCode()方法。】
说明:equals和hashCode方法是对象在hash容器内高效工作的基础,正确的覆写这两个方法才能保证在hash容器内查找对象的正确性,同时一个好的hashCode方法能大幅提升hash容器效率。
军规九:【禁止循环中创建新线程,尽量使用线程池。】
军规十:【在进行精确计算时(例如:货币计算)避免使用float和double,浮点数计算都是不精确的,必须使用BigDecimal或将浮点数运算转换为整型运算。】
说明:浮点运算在一个范围很广的值域上提供了很好的近似,但是它不能产生精确的结果。二进制浮点对于精度计算是非常不适合的,因为它不可能将0.1——或者10的其它任何次负幂精确表示为一个长度有限的二进制小数。
1. 小提交: 把大的任务拆分成多个独立小任务,每完成小任务确保无 Bug 后就可以提交合并到主分支甚至发布;频繁提交有利于自己把控项目进度、降低风险、同其他人协作和代码 Review ; 每天可以提交合并多次。每个小任务是 1-2 个小时可以完成的粒度,最大的一天完成。并行做多个任务的时候,优先做最短时间能够实现的任务。
2. 避免一屏显示不下的超大函数。
3. 添加必要、简洁的注释。
4. 不把自己局限到做某个功能,每个人都是整个项目的 Owner ,尽量交叉 Review ,交叉开发。
5. 遇到问题及时和其他人沟通,避免浪费时间。
6. 从最终产品的目标审视自己细小的设计,熟悉自己负责部分的上下游代码。时刻关注最终产品(Web 界面和日志),发现 Bug 和可以改善的地方。
编码人员的误区
误区一:因为任务紧迫,所以没有时间想
有些人认为只有在领导规定的时间内完成任务才是最重要和最紧急的。至于方向是否正确,功能是否完整则没有时间去考虑。 这些人陷入了多写些代码和程序就会安全了的假象当中。殊不知方向错了,跑得越快,损失越大。
抱有这种想法的根本原因在于他们的不自信,不知道如何分析问题,找出最佳解决途径和细致的评估影响面,因而无法向上级提出一个更加合理的时间。
例如: Bulk Address feature 的设计者也是说时间紧,没时间细想。后来的结果就是这个 feature 的 design 和代码被一次又一次的推翻和重做。而我们的 leader 也因为反复的向 Jerry Lu 解释上次做错了能否接受我们新的 Solution 而招致了 Jerry Lu 的反感。
误区二:在最后一刻告诉 Leader 代码写完就算开发任务完成了
这种人认为只要写完代码告诉 Team Leader ,自己就可以交差了。
如果做错了,大不了重做;
如果漏做了,大不了补做;
如果 bug 很多,大不了 fix bug ;
自己没考虑到,还有 Team Leader
例如:分配给做 Multi Agency admin 端 code owner 的开发时间原本是足够的。但是他写完代码后,只验证了最基本的增、删、改、查功能,主要的业务逻辑和其他的边边角角的功能都没有测试,直到上级规定完成时间的最后一刻他才对 Leader 说任务完成了。
这样做的严重后果有 2 个:
1 由于这个开发人员缺乏责任心,导致我们不得不花了比原计划多出 30% 以上的时间去补做和补测
2 开发人员没有意识到之前他的 Leader 对他的能力不太熟悉,所以给他的时间会比正常情况下多一些。只要发挥出正常能力和应有的责任心就可以提前完成任务。结果他不但没有完成任务,还浪费掉了预留给他的时间。这种情况下他的 Leader 对他能力的评估只会更差,同时也增加了 Leader 对他能力的不信任。
误区三:领导说得都是对的,我没意见
例如:一个 Leader 在给组员讲解需求和设计时,希望大家都能够提出自己问题和想法。有个组员就对这个 Leader 说你的分析设计能力比我强,工作经验比我丰富,你说的都对我能有什么意见。
发生这种现象时,开发人员和 Team leader 都有需要改进的地方。
开发人员这么说,有下列几种可能:
1) 他当时心情不好正在闹情绪,这时开发人员应当注意控制好自己的情绪
2) 他真的是全听懂了,只要回答“我全明白了”就好了
3) 绝大多数内容他没听懂,这时他可以回答“我暂时还不能完全理解你说的所有内容。我下来再仔细看看文档,估计 30 分钟后再来问你好吗?”
Team Leader 对于那些能力比较弱的人可以采取如下措施:
1) 给组员一些准备时间,在讲解前告诉他们着重看那部分内容。
2) 讲解完毕后,可以让组员讲出哪些分析点是他之前没有想到的,怎样分析才能够分析的比较全面。
3) 如果组员的分析能力实在太弱什么也讲不出来,我们还可以鼓励他们说出哪些内容他们没听明白。
这样一来,我们对组要的要求就可以做到因人而异,且比较具体化。同时我们要求的也是组员能够做得到的。 Team Leader 要学会 Case by Case 的教导组员如何逐步提高。
误区四:凡事都有 Team Leader 帮忙检查
例如:有一次 Hikelee 让一个组员给他写一封需要回复给客户的邮件。很快这个组员就告诉 Hikelee 写完了。
Hikelee 就问他说“我是否可以不做任何修改就可以把这份邮件直接发给 Anderson ?”这个组员回答说不能。 Hikelee 就让他拿回去参看以往 Hikelee 发出的类似邮件去改,直到达到这个标准后再发给过来。
过了一会这个组员又说写完了。这次 Hikelee 又问他,是不是 Anderson 也不需要做任何修改就可以把这份邮件直接发给我们的客户?组员回答说不能。 Hikelee 就对他说在去看看 Anderson 以往是怎么回复客户这类问题的,找到差别修改后再发给我。
误区五:只提出问题而不负责解决,解决问题是 leader 或 PM 的事
例如:有些组员会问,我们这个 release 的加班好像是比上个 release 少了一点点,但是说实话还是太多太频繁,我们能不能少加点班?
问话的组员只是提出了问题,却没有思考是不是有些必须要加班才能完成的任务自己也有责任 ? 有的话原因在哪里,你认为怎样做才能够减少或避免类似的加班?
经过我们的分析,导致这类加班我们自身的原因主要有:
1) 用人不当,由能力不足的人作分析设计导致设计失误太多,必须要花更多的时间检查和修补
2) 缺乏有效的分析设计技巧导致和业务领域知识,导致 Effort 估计不足
3) 编码和 UT 素质较差,需要成倍的时间进行修补和返工
4) 工作效率低导致在规定的时间内未能完成任务而加班
5) 工作方法不当,一些无谓的等待导致了加班
根据不同的原因我们可以采取不同的策略来处理。
误区六:整天写代码太单调太没劲
有的开发人员觉得自己整天都在写代码, fix bug 没劲。对上级布置的任务也太当回事,抱着应付差事的心态在做事,你布置一件我应付一件,你说怎么做我就怎么做,反正办好办坏都一样。
实际上我们应该认识到无论是谁,无论能力高低都必须做到让领导对自己所做的每一件工作满意,才有可能接受更高难度和更有挑战的工作,他的职务薪资也会随他所从事的工作难度的提高而逐步提高。
例如:以我为例,在转到 Accela 部门前就已经是 Team Leader 了。但是我还是被安排到从基本的编码开始,独自负责一个 Feature 。我把这种安排当作是一次对我的考验,尽自己最大的努力做好。结果这个 feature 做得很好,并且在做的过程中体现出了优秀的技术能力、学习能力、沟通协调能力和很高责任心和使命感,证明了我做 Team Leader 。因此在这个新的部门做回了 Team Leader 的职务。在做 Team Leader 的过程中,也是因为我所带领的 team 战斗力强,队员素质提高快而被提升为 PM 。
一个开发人员,只有在他的代码写的很好的情况下,才能够获得需求分析和设计工作;只有在需求分析和设计做得都很好的情况下,才能够做 feature owner ;只有在 feature owner 做得很好的情况下,才能够获做 Team Leader 。
误区七:工作既然交给我做就应该信任我
要知道“用人不疑,疑人不用”只是个结果而不是过程。我们每个人都必须经过严谨的考验后,才能够逐步的取得领导的信任。在完成任务的过程中,领导可以观察出我们的能力水平。以后安排那些在我们能力范围内的任务时,他就可以比较放心,投入较少的精力。相反如果他安排了超出我们能力范围外的工作时,他就必须要投入比较多的精力来监管。因此,信任不是绝对的。
如果我们想要取得领导的信任,就必须要尽我们最大的努力来做好领导安排的每一项工作,提高领导对我们能力水平的认识,做到事事让领导放心。
误区八:因为一些在 bug 描述中没有提到过得 issue , QA reopen 我们 bug 是不对的
例如:有这样一个 bug , QA 只描述了在 Create Portlet 里有问题。后来 QA 在验证 bug 时发现开发人员只 fix 掉了 Create Portlet 里的问题, Search Portlet 也有同样的问题但没被 fix 掉,因此 reopen 了该 bug 。
开发人员就说“不对, QA 你没有提到过 Search Portlet 也有问题,这个 bug 不该被 reopen ,你应该提一个新的 Search Portlet bug 。”
这种思想是错误的,原因如下:
1) 不要急着先说人家 Reopen 不对,首先自己要先核实 Search Portlet 里的 bug 和 Create Portlet 的 bug 是否无关。如果确实无关再耐心的和 QA 解释为什么应该提一个新的 bug
2) 但是无论如何出现这种状况,我们的开发人员自身也有问题。他们不了解, fix bug 不是头痛医头,脚痛医脚。我们首先要找到 bug 的成因,然后分析这个 bug 成因的潜在影响面,最后彻底的 fix 掉这个 bug 。另外, bug 有个扎堆的原理,当你发现一个地方有 bug 时,往往周围出现 bug 的几率就会比较高。所以我们一定要在这个 bug 的周围多做一些测试。
3) 不懂的只有高标准严要求,才能激励自己更快更好的发展。
4) 这种工作人员的工作心态也有问题,错了就是错了,不要对自己的错误做过多的辩解。知道自己错误,错在哪里,然后下次能够改进就好了。因此我们需要及时的调整好自己的心态。
误区九:上班时浏览技术网站学习新的技术没有问题
我们不反对组员学习新的知识。但是应当是在自己当天的任务已经完成的前提下。如果研究的内容与我们的工作有关,我们还会鼓励。
例如:为了提高 fix bug 的效率我们要求在 Fix bug 阶段,确认一个不能重现的 bug 最多不能超过 2 个小时。这个规定早上刚刚讲完,我们就发现有个组员确认了 2 个不能重新的 bug 后,就去上网学习新技术去了。
参考链接:
=END=
《 “[collect]一些软件编程相关规范” 》 有 16 条评论
JAVA安全SDK及编码规范
https://github.com/momosecurity/rhizobia_J
PHP安全SDK及编码规范
https://github.com/momosecurity/rhizobia_P
程序员如何减少开发中的 Bug?
http://jartto.wang/2019/08/24/how-to-decrease-bugs/
`
一、概述
爱因斯坦曾经说过:「如果给我一个小时解答一道决定我生死的问题,我会花55分钟来弄清楚这道题到底是在问什么。一旦清楚了它在问什么,剩下的5分钟足够解答这个问题。」
虽然我们软件开发过程不会面临生死的抉择,但是却直接影响着用户的使用感受,决定着产品的走向。所以程序员如何减少开发中的 Bug,既反映了代码质量,也反映了个人综合能力。
那么我们该如何有效的减少开发中的 Bug 呢?
我觉得应该从两方面说起:业务层和代码层。
二、业务层
软件开发前期,我们都会进行「评审,反讲,评估」三个阶段。
1.需求讨论阶段
2.开发完成阶段
3.提测
三、代码层
代码层面,我们需要从以下几方面来说起:
1.Eslint 规避低级语法问题
2.边界处理
3.单元测试
4.积累
5.学习
四、总结
不断总结,不断提高。
`
如何避免新代码变包袱?阿里通用方法来了!
https://mp.weixin.qq.com/s/1nFNAtpDPKzv2TyRd3UOjg
`
导读:什么是设计?什么是架构?从零开始建立一个新的系统,新写的每行代码都可能成为明天的历史包袱?如何能有效的在遗留代码上工作?今天,阿里资深技术专家辉子为我们带来NBF框架下软件工程架构设计通用方法论,值得细细品读。
Note:本文讨论的是基于服务化前提下的通用软件工程架构方法论,并未涉及到微观设计或架构的具体细节。
如何能有效的在遗留代码上工作,业内有本非常不错的书,叫”Working Effectively with Legacy Code”,值得精读:
所以我这里的标题可能不准确,我要讨论的更多是”遗留代码的重构”,什么时候我们开始讨论需要把现有系统重构:
– 代码确实腐化到无法正常维护,或者新加一个需求代价很大;
– 目前代码的技术架构满足不了下一步业务的发展;
– 很多特性已经下线作废,却跟有用的代码藕断丝连;
– 业务逻辑随着发展分散到不同的应用里,界限不清;
– 专家级的未雨绸缪,着眼未来的规划和新技术的应用;
– 换老大了,需要立新的flag。
聚焦与收敛上游调用
解耦下游依赖
以服务为单位切换
老系统下线
几个建议:
1. 先把老实现作为API的默认实现,新的实现作为老的实现的降级实现,并使用策略分流一部分流量(具体比例跟团队信心相关);
2. 对于有业务需求变更的部分应尽快实现在新的实现里,并将新实现作为API的默认实现,老实现作为新实现的降级实现,策略应该是即时降级,也就是新实现出现问题立刻降级到老实现;
3. 运行一段时间没有问题后,讲所有默认实现切换为新实现,并将老实现作为新实现的降级实现;
4. 其实这时就算所有切换完毕:老实现可以永远作为新实现的降级实现,也就是只要我升级一次服务,上一次成功版本就可以作为这次的降级实现,这样,线上问题回滚就是秒级的。
`
这样规范写代码,同事直呼“666”
https://mp.weixin.qq.com/s?__biz=MzA4NjgxMjQ5Mg==&mid=2665762775&idx=1&sn=e3ab22232c7bd99ecbb5ab6e332df25a
`
一、MyBatis 不要为了多个查询条件而写 1 = 1
二、迭代entrySet() 获取Map 的key 和value
三、使用Collection.isEmpty() 检测空
四、初始化集合时尽量指定其大小
五、使用StringBuilder 拼接字符串
六、若需频繁调用Collection.contains 方法则使用Set
七、使用静态代码块实现赋值静态成员变量
八、删除未使用的局部变量、方法参数、私有方法、字段和多余的括号。
九、工具类中屏蔽构造函数
十、删除多余的异常捕获并跑出
十一、字符串转化使用String.valueOf(value) 代替 ” ” + value
十二、避免使用BigDecimal(double)
十三、返回空数组和集合而非 null
十四、优先使用常量或确定值调用equals 方法
十五、枚举的属性字段必须是私有且不可变
十六、string.split(String regex)部分关键字需要转译
`
The Uber Go Style Guide. Uber Go 语言编码规范中文版
https://github.com/xxjwxc/uber_go_guide_cn
https://github.com/uber-go/guide
软件工程六大设计原则总结,案例演示
https://mp.weixin.qq.com/s/P6UAH9Hrbg1Zng2Y26FvHA
`
一、单一职责原则
1、概念描述
对类来说的,即一个类应该只负责一项职责。如果一个类负责两个职责,可能存在职责1变化,引起职责2变化的情况。可以基于抽象逻辑,或者业务逻辑对类进行细化。
二、接口隔离原则
1、概念描述
客户端不应该依赖它不需要的接口,一个类对另一个类的依赖,应该建立在最小的接口上。
三、依赖倒转原则
1、概念描述
高层模块不应该依赖低层模块,两者应依赖其抽象;抽象不应该依赖细节,细节应该依赖抽象;中心思想是面向接口编程。
四、里氏替换原则
1、概念描述
假设如下场景:
存在,一个类型T1,和实例的对象O1
存在,一个类型T2,和实例的对象O2
如果将所有类型为T1的对象O1都替换成类型T2的对象O2,程序的行为不发生改变。那么类型T2是类型T1的子类型。换句话说,所有引用基类的地方必须能透明地使用其子类的对象。
五、开闭原则
1、概念描述
开闭原则是编程中最基础、最重要的设计原则,在代码结构的设计设计时,应该考虑对扩展开放,对修改关闭,抽象思维搭建结构,具体实现扩展细节。
六、迪米特原则
1、概念描述
迪米特原则又叫最少知道原则,即一个类对自己依赖的类知道的越少越好。也就是说,对于被依赖的类不管多么复杂,都尽量将逻辑封装在类的内部。对外除了提供的public方法,不对外开放任何信息。类与类关系越密切,耦合度越大,耦合的方式很多,依赖,关联,组合,聚合等。
直接朋友概念
两个对象之间有耦合关系,就说这两个对象之间是朋友关系。其中出现成员变量,方法参数,方法返回值中的类称为直接朋友,而出现在局部变量中的类不是直接朋友。从原则上说,陌生的类最好不要以局部变量的形式出现在类的内部。
七、设计原则总结
设计模式和设计原则的核心思想都是:判断业务应用中可能会变化模块,并且把这些模块独立出来,基于指定的策略进行封装,不要和那些变化的不大的模块耦合在一起,封装思想上基于接口和抽象类,而不是针对具体的实现编程。核心目的就是降低交互对象之间的松耦合度。设计模式和原则都不是可以生搬硬套的公式,个人理解:只要形似,神韵就自然不差。
`
如何在团队中做好Code Review
https://mp.weixin.qq.com/s/R9e-2MbfBAcc1kCOZNRuYw
`
一、Code Review的好处
1、互相学习,彼此成就
2、知识共享,自动互备
3、统一风格,提升质量
二、推动Code Review落地执行
1、选定工具
2、制定开发规范
没有规则,就没有执行。规则中首当其冲的就是开发规范。规范中建议包含:
* 工程规范(工程结构,分层方式及命名等等)
* 命名规范(接口、类、方法名、变量名等)
* 代码格式(括号、空格、换行、缩进等)
* 注释规范(规定必要的注释)
* 日志规范(合理的记录必要的日志)
* 各种推荐与不推荐的代码示例
3、制定流程规范
4、分享与统计
三、保证Code Review质量的关键
1、工程师对研发规范的认真学习
2、资深工程师的认真对待
`
Java开发手册
https://github.com/alibaba/p3c
基于GitLab的Code Review教程
https://ken.io/note/gitlab-code-review-tutorial
Google代码风格指南
https://zh-google-styleguide.readthedocs.io
Jenkins+Sonar执行代码扫描
https://ken.io/note/jenkins-maven-java-sonar-integration
惊讶!我定的日志规范被CTO在全公司推广了
https://mp.weixin.qq.com/s/UDVr13gBS-_VhsXn6FZQEg
`
1. 日志
1.1 日志是什么?
1.2 日志有什么用?
1.3 什么时候记录日志?
2. 日志打印
2.1 Slf4j & Logback
2.2 日志文件
2.3 日志变量定义
2.4 日志配置
2.5 参数占位格式
2.6 日志的基本格式
2.7 最佳实践
2.7.1 日志格式
* 时间
* pid,pid
* log-level,日志级别
* svc-name,应用名称
* trace-id,调用链标识
* span-id,调用层级标识
* user-id,用户标识
* biz-id,业务标识
* thread-name,线程名称
* package-name.class-name,日志记录器名称
* log message,日志消息体
2.7.2 日志模块扩展
3 日志服务
3.1 SLS 阿里云日志服务
3.2 ELK 通用日志解决方案
`
Java日志记录最佳实践
https://www.jianshu.com/p/546e9aace657
别在 Java 代码里乱打日志了,这才是打印日志的正确姿势!
https://mp.weixin.qq.com/s/hJvkRlt9xQbWhYy1G7ZDsw
阿里云日志服务
https://help.aliyun.com/product/28958.html
Spring Boot Logging
https://docs.spring.io/spring-boot/docs/2.2.1.RELEASE/reference/html/spring-boot-features.html#boot-features-logging
Spring Cloud Sleuth
https://github.com/spring-cloud/spring-cloud-sleuth
Opentracing
https://github.com/opentracing
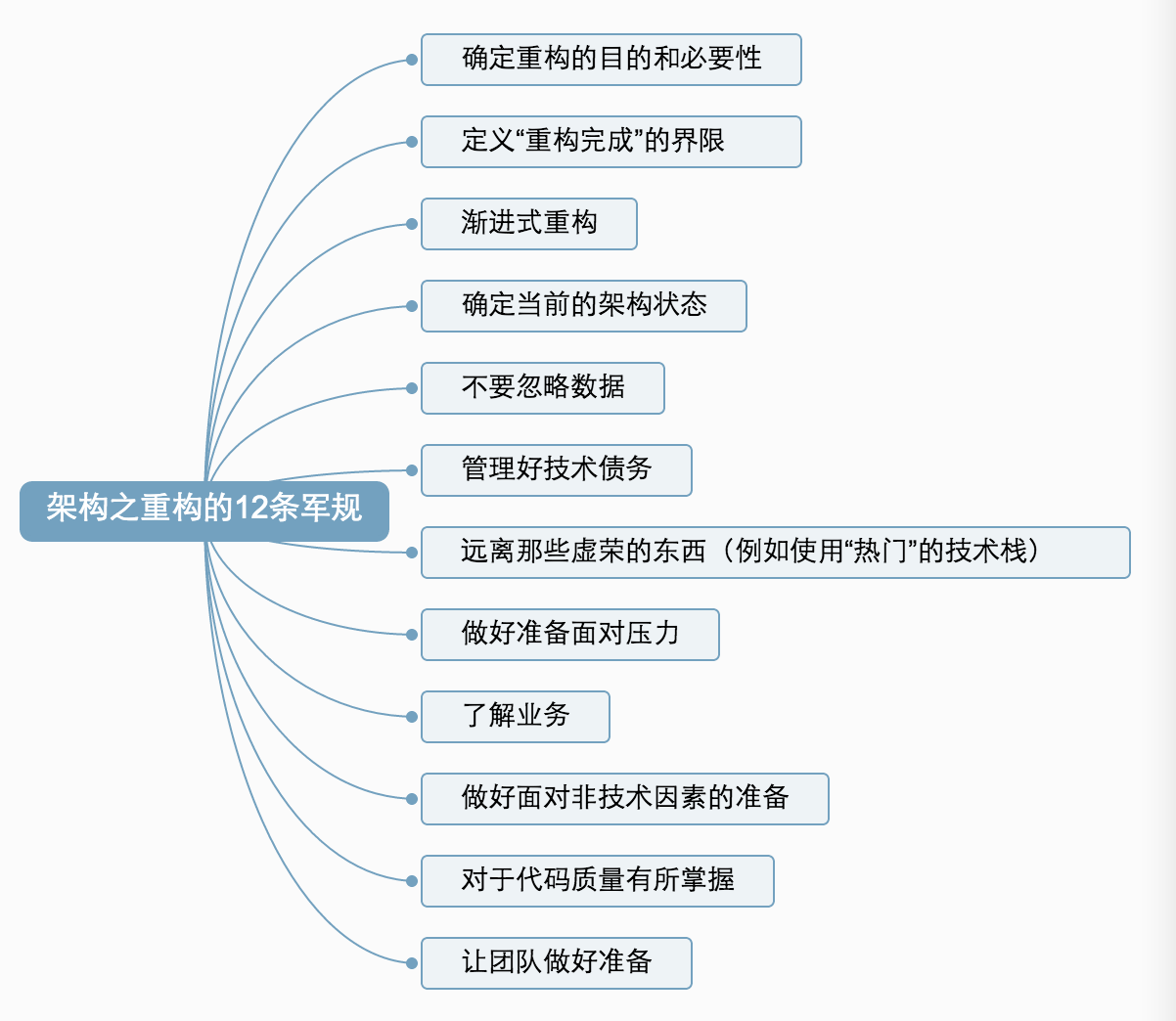
架构之重构的 12 条军规(上)
https://www.infoq.cn/article/architect-12-rules/
架构之重构的 12 条军规
https://www.infoq.cn/article/architect-12-rules-complete/
`
1. 确定重构的目的和必要性
2. 定义“重构完成”的界限
3. 渐进式重构
4. 确定当前的架构状态
5. 不要忽略数据
6. 管理好技术债务
7. 远离那些虚荣的东西(例如使用“热门”的技术栈)
8. 做好准备面对压力
9. 了解业务
10. 做好面对非技术因素的准备
11. 对于代码质量有所掌握
12. 让团队做好准备
`
Raffi Krikorian Provides Guidance for “Re-architecting on the Fly”
https://www.infoq.com/news/2015/04/raffi-krikorian-rearchitecting/
`
1. Hold the line [against the business]
2. Define “done”
3. Incrementalism
4. Find the starting line
5. Don’t ignore the data
6. Manage tech debt better
7. Stay away from vanity stuff [such as ‘hot’ new technical stacks]
8. Prepare for mounting tensions
9. Know the business
10. Get ready for politics
11. Keep an eye on code quality
12. Get the team ready
`
Apache的架构师们遵循的30条设计原则
https://mp.weixin.qq.com/s/DBVlmyJjVHlR5XsBP3xvwQ
`
# 基本原则
原则1:KISS(Keep it simple,sutpid) 和保持每件事情都尽可能的简单。用最简单的解决方案来解决问题。
原则2:YAGNI(You aren’t gonna need it)-不要去搞一些不需要的东西,需要的时候再搞吧。
原则3:爬,走,跑。换句话说就是先保证跑通,然后再优化变得更好,然后继续优化让其变得伟大。迭代着去做事情,敏捷开发的思路。对于每个功能点,创建里程碑(最大两周),然后去迭代。
原则4:创建稳定、高质量的产品的唯一方法就是自动化测试。所有的都可以自动化,当你设计时,不妨想想这一点。
原则5:时刻要想投入产出比(ROI)。就是划得来不。
原则6:了解你的用户,然后基于此来平衡你需要做哪些事情。不要花了几个月时间做了一个devops用户界面,最后你发现那些人只喜欢命令行。此原则是原则5的一个具体表现。
原则7:设计和测试一个功能得尽可能的独立。当你做设计时,应该想想这一条。从长远来看这能给你解决很多问题,否则你的功能只能等待系统其他所有的功能都就绪了才能测试,这显然很不好。有了这个原则, 你的版本将会更加的顺畅。
原则8:不要搞花哨的。我们都喜欢高端炫酷的设计。最后我们搞了很多功能和解决方案到我们的架构中,然后这些东西根本不会被用到。
# 功能选择
原则9:不可能预测到用户将会如何使用我们的产品。所以要拥抱MVP(Minimal Viable Product),最小可运行版本。这个观点主要思想就是你挑几个很少的使用场景,然后把它搞出来,然后发布上线让用户使用,然后基于体验和用户反馈再决定下一步要做什么。
原则10:尽可能的做较少的功能。当有疑问的时候,就不要去做,甚至干掉。很多功能从来不会被使用。最多留个扩展点就够了。
原则11:等到有人提出再说(除非是影响核心流程,否则就等到需要的时候再去做)。
原则12:有时候你要有勇气和客户说不。这时候你需要找到一个更好的解决方案来去解决。记住亨利福特曾经说过的 :”如果我问人们他们需要什么,他们会说我需要一匹速度更快的马”。记住:你是那个专家,你要去引导和领导。要去做正确的事情,而不是流行的事情。最终用户会感谢你为他们提供了汽车。
# 服务端设计和并发
原则13:要知道一个server是如何运行的,从硬件到操作系统,直到编程语言。优化IO调用的数量是你通往最好架构的首选之路。
原则14:要了解Amdhal同步定律。在线程之间共享可变数据会让你的程序变慢。只在必要的时候才去使用并发的数据结构,只在必须使用同步(synchronization)的时候才去使用同步。如果要用锁,也要确保尽可能少的时间去hold住锁。如果要在加锁后做一些事情,要确保自己在锁内会做哪些事情。
原则15:如果你的设计是一个无阻塞且事件驱动的架构,那么千万不要阻塞线程或者在这些线程中做一些IO操作,如果你做了,你的系统会慢的像骡子一样。
# 分布式系统
原则16:无状态的系统的是可扩展的和直接的。任何时候都要考虑这一点,不要搞个不可扩展的,有状态的东东出来,这是起码的。
原则17:保证消息只被传递一次,不管失败,这很难,除非你要在客户端和服务端都做控制。试着让你的系统更轻便(使用原则18)。你要知道大部分的承诺exactly-once-delivery的系统都是做了精简的。
原则18:实现一个操作尽可能的幂等。这样的话就比较好恢复,而且你还处于至少一次传递(at least once delivery)的状态。
原则19:知道CAP理论。可扩展的事务(分布式事务)是很难的。如果可能的的话,尽可能的使用补偿机制。RDBMS事务是无法扩展的。
原则20:分布式一致性无法扩展,也无法进行组通信,也无法进行集群范围内的可靠通信。理想情况下最大的节点限制为8个节点。
原则21:在分布式系统中,你永远无法避免延迟和失败。
# 用户体验
原则22:要了解你的用户和清楚他们的目标。他们是新手、专家还是偶然的用户?他们了解计算机科学的程度。极客喜欢扩展点,开发者喜欢示例和脚本,而普通人则喜欢UI。
原则23:最好的产品是不需要产品手册的。
原则24:当你无法在两个选择中做决定的时候,请不要直接把这个问题通过提供配置选项的方式传递给用户。这样只能让用户更加的发懵。如果连你这个专家都无法选择的情况下,交给一个比你了解的还少的人这样合适吗?最好的做法的是每次都找到一个可行的选项;次好的做法是自动的给出选项,第三好的做法是增加一个配置参数,然后设置一个合理的默认值。
原则25:总是要为配置设置一个合理的默认值。
原则26:设计不良的配置会造成一些困扰。应该总是为配置提供一些示例值。
原则27:配置值必须是用户能够理解和直接填写的。比如:不能让用户填写最大缓存条目的数量,而是应该让用户填写可被用于缓存的最大内存。
原则28:如果输入了未知的配置要抛出错误。永远不要悄悄的忽略。悄悄的忽略配置错误往往是找bug花了数小时的罪魁祸首。
# 艰难的问题
原则29:梦想着新的编程语言就会变得简单和明了,但往往要想真正掌握会很难。不要轻易的去换编程语言。
原则30:复杂的拖拉拽的界面是艰难的,不要去尝试这样的效果,除非你准备好了10人年的团队。
`
SQL代码编码原则和规范
https://help.aliyun.com/document_detail/137491.html
`
# SQL代码的编码原则
* 代码功能完善。
* 代码行清晰、整齐,代码行的整体层次分明、结构化强。
* 代码编写充分考虑执行速度最优的原则。
* 代码中需要添加必要的注释,以增强代码的可读性。
* 规范要求并非强制性约束开发人员的代码编写行为。实际应用中,在不违反常规要求的前提下,允许存在可以理解的偏差。
* SQL代码中应用到的所有SQL关键字、保留字都需使用全大写或小写,例如select/SELECT、from/FROM、where/WHERE、and/AND、or/OR、union/UNION、insert/INSERT、delete/DELETE、group/GROUP、having/HAVING和count/COUNT等。不能使用大小写混合的方式,例如Select或seLECT等方式。
* 4个空格为1个缩进量,所有的缩进均为1个缩进量的整数倍,按照代码层次对齐。
* 禁止使用select *操作,所有操作必须明确指定列名。
* 对应的括号要求在同一列的位置上。
# SQL编码规范
* 代码头部
* 字段排列要求
* INSERT子句排列要求
* SELECT子句排列要求
* 运算符前后间隔要求
* CASE语句的编写
* 查询嵌套编写规范
* 表别名定义约定
* SQL注释
`
数仓开发规范
https://www.studytime.xin/article/datawarehouse-sql-conventions.html
`
一、注释规范
* 注释内容要清晰明了,含义准确,避免歧义
* 字段注释紧跟在字段后面
* 应对不易理解的分支条件表达式加注释
* 对重要的计算应说明其功能
* 过长的函数实现,应将其语句按实现的功能分段加以概括性说明
* 原则上所有表、字段、任务都需要添加注释,任务有特定的注释规范
任务注释说明
…
任务注释注意事项补充
1、提供任务名,方便任务创建时任务的获取以及平台中任务查询
2、提供创建者、创建日期、功能描述等信息,方便后期维护跟踪
2、提供代码变更历史,便于了解代码演进历史及依据
3、提供脚本依赖表清单,方便后续任务依赖配置
4、提供输出表清单,方便确认是否单个目标表
二、存储格式规范
三、建表语句规范
四、数据类型规范
五、SQL编码原则及规范
六、空值处理
对于表中的空值,尽量用如下规则统一,如果有特殊情况请视情况而定。
特殊说明:
一般而言上述情况基本可以满足需求,但是不排除有特殊情况,需求要求不按照上述规范或者上述不足覆盖的场景,视情况而定。除了将空值替换为特定的值之外,业务也有直接过滤掉数据的情况。
规范要求的项,并非强制性约束,在实际应用中在不违反常规要求的前提下允许存在可理解的偏差。同时在研发过程中,如遇到问题以及好的建议,及时沟通补充此规范。也希望规范在对日常的代码开发工作起到指导作用的同时也将得到不断的完善和补充。
`
SQL样式指南 · SQL Style Guide
https://www.sqlstyle.guide/zh/
https://github.com/treffynnon/sqlstyle.guide
`
Overview 综述
你可以直接使用这些指导方针,或者 fork 后创建自己的版本 —— 最重要的是**选择一套方针并严格遵守它**。
General 一般原则
* Do 应该做的事情
* Avoid 应避免的事情
Naming conventions 命名惯例
* General 一般原则
* Tables 表名
* Columns 列名
* Aliasing or correlations 别名与关联名
* Stored procedures 存储过程名
* Uniform suffix 统一的后缀
Query syntax 查询语句
* Reserved words 保留字
* White space 空白字符
* Indentation 缩进
* Preferred formalisms 推荐的形式
Create syntax 创建语句
* Choosing data types 选择数据类型
* Specifying default values 指定默认类型
* Constraints and keys 约束和键
* Design to avoid 应该避免的设计
附录
* 保留字参考
* Column data types 列的数据类型
`