=Start=
缘由:
整理一下在学习Hadoop生态系统时遇到的比较好的资料,为后续的大数据安全学习做准备。
正文:
参考解答:
&
&
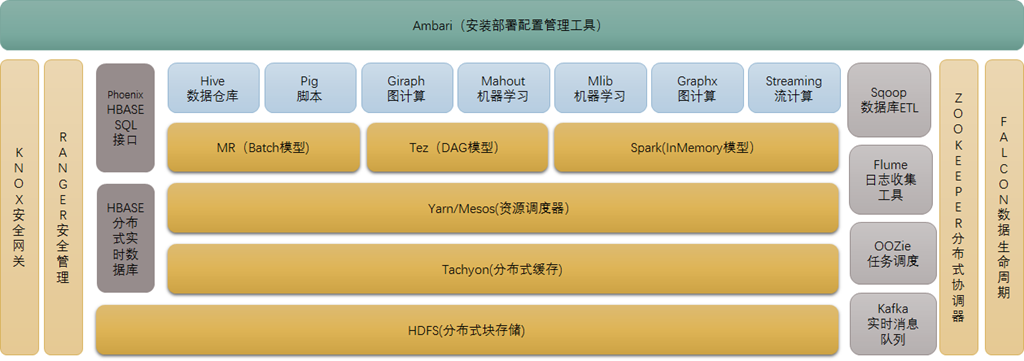
1、Hadoop 生态系统概述
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。
用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。具有可靠、高效、可伸缩的特点。
Hadoop的核心是:HDFS和MapReduce/MapReduce2(YARN),一个是分布式存储框架,一个是分布式计算框架。
2、HDFS(Hadoop分布式文件系统)
源自于Google的GFS论文,发表于2003年10月,HDFS是GFS克隆版。
HDFS是Hadoop体系中数据存储管理的基础。它是一个高度容错的系统,能检测和应对硬件故障,用于在低成本的通用硬件上运行。
HDFS简化了文件的一致性模型,通过流式数据访问,提供高吞吐量应用程序数据访问功能,适合带有大型数据集的应用程序。
它提供了一次写入多次读取的机制,数据以块的形式,同时分布在集群不同物理机器上。
3、Mapreduce(分布式计算框架)
源自于Google的MapReduce论文,发表于2004年12月,Hadoop MapReduce是 Google MapReduce 克隆版。
MapReduce是一种分布式计算模型,用以进行大数据量的计算。它屏蔽了分布式计算框架细节,将计算抽象成map和reduce两部分,
其中Map对数据集上的独立元素进行指定的操作,生成键-值对形式中间结果。Reduce则对中间结果中相同“键”的所有“值”进行规约,以得到最终结果。
MapReduce非常适合在大量计算机组成的分布式并行环境里进行数据处理。
4、HBase(分布式列式kv数据库)
源自Google的Bigtable论文,发表于2006年11月,HBase是 Google Bigtable 克隆版。
HBase是一个建立在HDFS之上,面向列的针对结构化数据的可伸缩、高可靠、高性能、分布式和面向列的动态模式数据库。
HBase采用了BigTable的数据模型:增强的稀疏排序映射表(Key/Value),其中,键由行关键字、列关键字和时间戳构成。
HBase提供了对大规模数据的随机、实时读写访问,同时,HBase中保存的数据可以使用MapReduce来处理,它将数据存储和并行计算完美地结合在一起。
5、Zookeeper(分布式协作服务)
源自Google的Chubby论文,发表于2006年11月,Zookeeper是Chubby克隆版。
解决分布式环境下的数据管理问题:统一命名,状态同步,集群管理,配置同步等。
Hadoop的许多组件依赖于Zookeeper,它运行在计算机集群上面,用于管理Hadoop操作。
6、Hive(数据仓库)
由Facebook开源,最初用于解决海量结构化的日志数据统计问题。
Hive定义了一种类似SQL的查询语言(HQL),将SQL转化为MapReduce任务在Hadoop上执行。通常用于离线分析。
HQL用于运行存储在Hadoop上的查询语句,Hive让不熟悉MapReduce开发人员也能编写数据查询语句,然后这些语句被翻译为Hadoop上面的MapReduce任务。
7、Pig(ad-hoc脚本)
由Yahoo!开源,设计动机是提供一种基于MapReduce的ad-hoc(计算在query时发生)数据分析工具。
Pig定义了一种数据流语言——Pig Latin,它是MapReduce编程的复杂性的抽象,Pig平台包括运行环境和用于分析Hadoop数据集的脚本语言(Pig Latin)。
其编译器将Pig Latin翻译成MapReduce程序序列将脚本转换为MapReduce任务在Hadoop上执行。通常用于进行离线分析。
8、Sqoop(数据ETL/同步工具)
Sqoop是SQL-to-Hadoop的缩写,主要用于传统数据库和Hadoop之前传输数据。数据的导入和导出本质上是Mapreduce程序,充分利用了MR的并行化和容错性。
Sqoop利用数据库技术描述数据架构,用于在关系数据库、数据仓库和Hadoop之间转移数据。
9、Flume(日志收集工具)
Cloudera开源的日志收集系统,具有分布式、高可靠、高容错、易于定制和扩展的特点。
它将数据从产生、传输、处理并最终写入目标的路径的过程抽象为数据流,在具体的数据流中,数据源支持在Flume中定制数据发送方,从而支持收集各种不同协议数据。
同时,Flume数据流提供对日志数据进行简单处理的能力,如过滤、格式转换等。此外,Flume还具有能够将日志写往各种数据目标(可定制)的能力。
总的来说,Flume是一个可扩展、适合复杂环境的海量日志收集系统。当然也可以用于收集其他类型数据
10、Mahout(数据挖掘算法库)
Mahout起源于2008年,最初是Apache Lucent的子项目,它在极短的时间内取得了长足的发展,现在是Apache的顶级项目。
Mahout的主要目标是创建一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序。
Mahout现在已经包含了聚类、分类、推荐引擎(协同过滤)和频繁集挖掘等广泛使用的数据挖掘方法。
除了算法,Mahout还包含数据的输入/输出工具、与其他存储系统(如数据库、MongoDB 或Cassandra)集成等数据挖掘支持架构。
11、Oozie(工作流调度器)
Oozie是一个可扩展的工作体系,集成于Hadoop的堆栈,用于协调多个MapReduce作业的执行。它能够管理一个复杂的系统,基于外部事件来执行,外部事件包括数据的定时和数据的出现。
Oozie工作流是放置在控制依赖DAG(有向无环图 Direct Acyclic Graph)中的一组动作(例如,Hadoop的Map/Reduce作业、Pig作业等),其中指定了动作执行的顺序。
Oozie使用hPDL(一种XML流程定义语言)来描述这个图。
12、Yarn(分布式资源管理器)
YARN是下一代MapReduce,即MRv2,是在第一代MapReduce基础上演变而来的,主要是为了解决原始Hadoop扩展性较差,不支持多计算框架而提出的。
YARN是下一代 Hadoop 计算平台,YARN是一个通用的运行时框架,用户可以编写自己的计算框架,在该运行环境中运行。
用于自己编写的框架作为客户端的一个lib,在运用提交作业时打包即可。该框架为提供了以下几个组件:
– 资源管理:包括应用程序管理和机器资源管理
– 资源双层调度
– 容错性:各个组件均有考虑容错性
– 扩展性:可扩展到上万个节点
13、Mesos(分布式资源管理器)
Mesos诞生于UC Berkeley的一个研究项目,现已成为Apache项目,当前有一些公司使用Mesos管理集群资源,比如Twitter。
与YARN类似,Mesos是一个资源统一管理和调度的平台,同样支持比如MR、Steaming等多种运算框架。
14、Tachyon(分布式内存文件系统)
Tachyon(/’tæki:ˌɒn/ 意为超光速粒子)是以内存为中心的分布式文件系统,拥有高性能和容错能力,
能够为集群框架(如Spark、MapReduce)提供可靠的内存级速度的文件共享服务。
Tachyon诞生于UC Berkeley的AMPLab。
15、Tez(DAG计算模型)
Tez是Apache最新开源的支持DAG作业的计算框架,它直接源于MapReduce框架,核心思想是将Map和Reduce两个操作进一步拆分,即Map被拆分成Input、Processor、Sort、Merge和Output, Reduce被拆分成Input、Shuffle、Sort、Merge、Processor和Output等。
这样,这些分解后的元操作可以任意灵活组合,产生新的操作,这些操作经过一些控制程序组装后,可形成一个大的DAG作业。
目前Hive支持MR、Tez计算模型,Tez能完美二进制MR程序,提升运算性能。
16、Spark(内存DAG计算模型)
Spark是一个Apache项目,它被标榜为“快如闪电的集群计算”。它拥有一个繁荣的开源社区,并且是目前最活跃的Apache项目。
最早Spark是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用的并行计算框架。
Spark提供了一个更快、更通用的数据处理平台。和Hadoop相比,Spark可以让你的程序在内存中运行时速度提升100倍,或者在磁盘上运行时速度提升10倍。
17、Giraph(图计算模型)
Apache Giraph是一个可伸缩的分布式迭代图处理系统, 基于Hadoop平台,灵感来自 BSP (bulk synchronous parallel) 和 Google 的 Pregel。
最早出自雅虎。雅虎在开发Giraph时采用了Google工程师2010年发表的论文《Pregel:大规模图表处理系统》中的原理。后来,雅虎将Giraph捐赠给Apache软件基金会。
目前所有人都可以下载Giraph,它已经成为Apache软件基金会的开源项目,并得到Facebook的支持,获得多方面的改进。
18、GraphX(图计算模型)
Spark GraphX最先是伯克利AMPLAB的一个分布式图计算框架项目,目前整合在spark运行框架中,为其提供BSP大规模并行图计算能力。
19、MLib(机器学习库)
Spark MLlib是一个机器学习库,它提供了各种各样的算法,这些算法用来在集群上针对分类、回归、聚类、协同过滤等。
20、Streaming(流计算模型)
Spark Streaming支持对流数据的实时处理,以微批的方式对实时数据进行计算
21、Kafka(分布式消息队列)
Kafka是Linkedin于2010年12月份开源的消息系统,它主要用于处理活跃的流式数据。
活跃的流式数据在web网站应用中非常常见,这些数据包括网站的pv、用户访问了什么内容,搜索了什么内容等。
这些数据通常以日志的形式记录下来,然后每隔一段时间进行一次统计处理。
22、Phoenix(HBase SQL接口)
Apache Phoenix 是 HBase 的SQL驱动,Phoenix 使得 HBase 支持通过JDBC的方式进行访问,并将你的SQL查询转换成 HBase 的扫描和相应的动作。
23、Ranger(安全管理工具)
Apache Ranger是一个 Hadoop 集群权限框架,提供操作、监控、管理复杂的数据权限,它提供一个集中的管理机制,管理基于 YARN 的 Hadoop 生态圈的所有数据权限。
24、Knox(Hadoop安全网关)
Apache Knox是一个访问 Hadoop 集群的 REST API网关,它为所有REST访问提供了一个简单的访问接口点,能提供3A认证(Authentication,Authorization,Auditing)和SSO(单点登录)等功能。
25、Falcon(数据生命周期管理工具)
Apache Falcon 是一个面向 Hadoop 的、新的数据处理和管理平台,设计用于数据移动、数据管道协调、生命周期管理和数据发现。它使终端用户可以快速地将他们的数据及其相关的处理和管理任务“上载(onboard)”到 Hadoop 集群。
26、Ambari(安装部署配置管理工具)
Apache Ambari 的作用就是创建、管理、监视 Hadoop 的集群,是为了让 Hadoop 以及相关的大数据软件更容易使用的一个Web管理工具。
参考链接:
- 大数据技术Hadoop入门理论系列之一—-hadoop生态圈介绍
- 《网络安全体系设计》第一弹:《安全大数据平台架构设计参考》
- Hadoop Terminology: Pig, Hive, HCatalog, HBase and Sqoop
- 企业安全建设之探索安全数据分析平台
- Hadoop安全指南
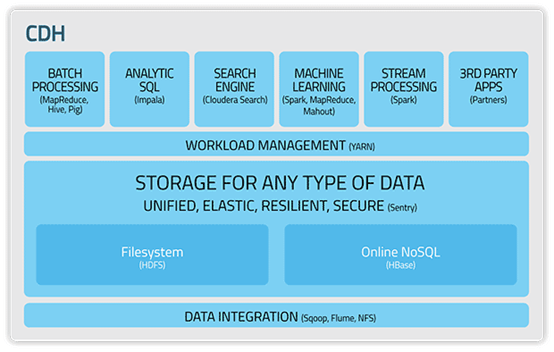
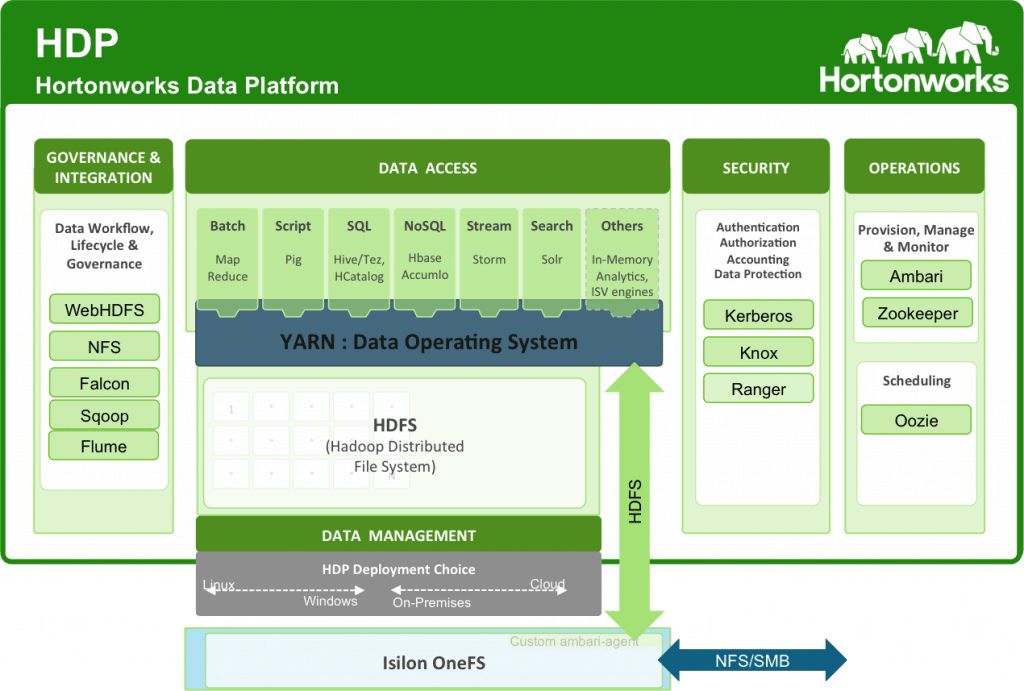
- Hortonworks Data Platform Security #HDP官方文档
- Cloudera Distribution Hadoop #CDH官方文档
=END=
《 “Hadoop生态系统学习整理” 》 有 30 条评论
后Hadoop时代的大数据架构
https://zhuanlan.zhihu.com/p/19962491
如何学习Hadoop,面试Hadoop工程师有哪些问题?
https://www.zhihu.com/question/24965053/answer/29612377
https://www.zhihu.com/topic/19563390/top-answers
`
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。 用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。 Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。 Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。
`
Hadoop生态系统表(The Hadoop Ecosystem Table)
https://hadoopecosystemtable.github.io/
https://github.com/hadoopecosystemtable/hadoopecosystemtable.github.io
Apache Zeppelin简介
https://blog.csdn.net/laozhaokun/article/details/44803061
`
Zeppelin是一个Apache的孵化项目。一个基于Web的笔记本,支持交互式数据分析。你可以用SQL、Scala等做出数据驱动的、交互、协作的文档。(类似于ipython notebook,可以直接在浏览器中写代码、笔记并共享)
Apache Zeppelin提供了Web版的类似ipython的notebook,用于做数据分析和可视化。背后可以接入不同的数据处理引擎,包括spark, hive, tajo等,原生支持scala, java, shell, markdown等。它的整体展现和使用形式和Databricks Cloud是一样的,就是来自于当时的demo。
`
Apache Zeppelin是什么?
http://www.cnblogs.com/zlslch/p/6949890.html
https://zeppelin.apache.org/
几个有关hadoop生态系统的架构图 #nice
https://blog.csdn.net/babyfish13/article/details/52527665
`
1、hadoop1.0时期架构
2、hadoop2.0时期架构
3、hdfs架构
4、MapReduce
5、yarn架构
6、hadoop1.0与hadoop2.0比较图
7、Hive(基于MR的数据仓库)
8、Hbase(分布式实时列式kv数据库)
9、Hadoop 发行版(开源版)
`
一文读懂Hadoop、HBase、Hive、Spark分布式系统架构
https://zhuanlan.zhihu.com/p/30644988
大数据框架学习:从 Hadoop 到 Spark
https://cloud.tencent.com/developer/article/1005706
hadoop 架构
https://www.cnblogs.com/oskyhg/p/7003634.html
一篇文看懂Hadoop #nice
https://www.cnblogs.com/shijiaoyun/p/5778025.html
大数据权限管理利器 – Ranger
https://blog.csdn.net/eyoulc123/article/details/79414301
Apache Ranger:统一授权管理框架
https://ieevee.com/tech/2016/05/12/ranger.html
从分布式管理到多租户实现,企业级大数据系统如何利用开源生态构建?
https://www.sohu.com/a/144966254_470008
安全有效地输出价值:大数据是这个游戏的名字
https://www.infoq.cn/article/safe-and-effective-output-value
GFS架构启示 | Google File System
https://mp.weixin.qq.com/s/eQ6BwLU9Twi_O9_99Ltviw
Google MapReduce到底解决什么问题?
https://mp.weixin.qq.com/s/HqJvoDbNQ9abq4vNqsRgkQ
Google MapReduce有啥巧妙优化?
https://mp.weixin.qq.com/s/O-9msY6FpCseo7PgMPYEqg
什么是Hive on Spark?
https://www.zhihu.com/question/37462583
`
问:
1.在Hive里设置hive.execution.engine=spark,然后在Hive CLI里执行查询Hive中的表。
2.在Spark程序中通过hiveContext.sql()查询Hive中的表。
这两种都是Hive on Spark吗?还是说有什么区别?
答:
所谓Hive on Spark只是Hive项目的一个新特性,和Spark项目的开发没啥关系。针对你列的1和2的区别是:
1. 就是所谓的Hive on Spark,就是把hive执行引擎换成spark。众所周知的是这个engine还可以设置和成mr(MRv1时代)和tez(目前hive13默认用的引擎,性能更佳),所以目前新增的spark选项只是Hive把执行计划放到spark集群上运行而已。
2. 是Spark SQL的一个特性。就是可以把hive作为一个数据源,这样我除了textFile从HDFS直接读文件,还可以直接用HiveQL查询到RDD,这对于要获取保存在Hive表的数据太方便了。这个特性早就支持了,至少我在之前用Spark1.2的时候已经可以从Hive里导入数据啦,最新的1.5新增了更多接口,用起来更方便了。
所以,简单来说区别1是Hive调用Spark任务,2是Spark调用Hive任务。
`
Hive on Spark解析
http://lxw1234.com/archives/2015/05/200.htm
Hive使用Spark on Yarn作为执行引擎
http://lxw1234.com/archives/2016/05/673.htm
6大主流开源SQL引擎总结,遥遥领先的是谁?
https://mp.weixin.qq.com/s/hpWXpiwyrckcPkHyNgHk-w
`
虽然Impala、Spark SQL、Drill、Hawq 和Presto 一直在运行性能、并发量和吞吐量上击败Hive,但是Hive 仍然是最流行的(至少根据DB-Engines 的标准)。原因有3个:
1、Hive 是Hadoop 的默认SQL 选项,每个版本都支持。而其他的要求特定的供应商和合适的用户;
2、Hive 已经在减少和其他引擎的性能差距。大多数Hive 的替代者在2012年推出,分析师等待Hive 查询的完成等到要自杀。然而当Impala、Spark、Drill 等大步发展的时候,Hive只是一直跟着,慢慢改进。现在,虽然Hive 不是最快的选择,但是它比五年前要好得多;
3、虽然前沿的速度很酷,但是大多数机构都知道世界并没有尽头。即使一个年轻的市场经理需要等待10秒钟来查明上周二Duxbury 餐厅的鸡翅膀的销量是否超过了牛肉汉堡。
`
总结:Hive,Hive on Spark和SparkSQL区别
https://blog.csdn.net/MrLevo520/article/details/76696073
Spark SQL和Hive使用场景?
https://www.zhihu.com/question/36053025
`
这个要从两者产生的背景来看。
Hive是什么?一个建立在分布式存储系统(这里指HDFS)上的SQL引擎。
为什么要有Hive呢?因为有了Hadoop后,大家发现存储和计算都有了,但是用起来很困难。去厂商那里一看,清一色Oracle、DB2、TD啥啥的,客户被惯的只会用SQL来处理业务,难一点都交给乙方来做。
转头一想,劳资拿个项目,总不能搭一堆维护人员天天在局点给你们维护你们写的(也有可能是自己写的)超烂的MR代码吧?嗯,在MR上包一层,继续让你们用SQL,就好了嘛
Hive适合的是什么场景呢?数据仓库。基于Hadoop做一些数据清洗啊(ETL)、报表啊、数据分析啊什么的。
传统数据库的SQL03 SQL11标准、自定义函数、权限管理,支持!
JDBC、ODBC、REST接入,支持!
存储过程,支持!
分布式的scale out,支持!
事务处理、一致性、回滚,这个比较难,但是也努力支持!
基本上就是朝着替代传统数据库的方向去的,当然是在大数据背景下的替代。本质上来说,它还是一个面向读的、面向分析的SQL工具。
你问它有什么缺点?天天插入、更新、删除数据,还要求强一致性和毫秒级相应,这个不仅不是Hive的长处,当前的Hadoop框架就不适合这玩意儿。
好,回过头来再说Spark SQL。
SparkSQL是啥呢?这个首先要问Spark是啥。
Spark就是以RDD为核心的计算框架,它产生的背景就是MR难用!慢!
于是Spark搞了一个抽象概念RDD,把map过程都串起来,内存用起来,再做点流水线优化。嗯,快了10到100倍(官方宣称)!
RDD上面抽象一些高级操作,替代MR单纯的map和reduce,简化编程;加上Python、R、Java、Scala等等的接口,谁来用都能无缝切换。嗯,易用性大大增加!
那既然有了RDD这么牛逼的东西,总不能只让用户去写应用处理离线任务吧。流处理,上!机器学习,上!SQL,上!哈哈哈哈哈我一个Spark啥都能搞定,你们就不用费心去用别的东东了!
那SparkSQL对比Hive有啥缺点呢?
由于前者发展时间短,且大数据领域Hive、HBase等等都已经快形成了事实标准,所以SparkSQL一直在吹嘘自己的一栈式数据处理平台,试图从易用性上争取用户。但用户是不是真的需要这些呢?未必。从Spark发展的过程来看,SparkSQL的发展速度远远超过Core、Streaming、MLlib、GraphX等;从语言来看,对Scala的支持也远远超过了Java、R、Python的关注。这说明了一栈式处理虽然看起来很美,但用户未必有这样的场景。
单就SparkSQL来讲呢?由于已经有了Hive(而避免重复造差不多的轮子),所以像Metastore、权限、JDBC这些东东,SparkSQL要么直接复用Hive的,要么干脆不做。
那SparkSQL究竟重点在做什么呢?性能、稳定性、标准兼容性,这是社区2.0版本比较关注的东西,也是Hive从架构上(计算引擎是外部依赖,而不是内部开发)无法赶超的东西。
SparkSQL的应用场景?传统数据仓库我看SparkSQL可能不想大力发展了。Apache Spark是从U.C.Berkeley孵化出来的,和Hadoop、Hive等社区被几大巨头牵制不同,其社区也牢牢被U.C.Berkeley databricks把控。而databricks推出的产品显然是公有(企业)云性质的大数据统一处理平台(Databricks makes Spark easy through a cloud-based integrated workspace.)(不是广告),所以SQL层的很多特性,它们要么不需要(权限管理、多租户),要么不必对客户暴露(JDBC等),所以干脆在社区不care这部分的发展。走上云化的道路,这是时代背景决定的,也是databricks的利益决定的。
选择SparkSQL,要么企业自己定制成性能更好的Hive。要么也将其云化,跟着databricks的脚步走。
`
Apache Hive vs Apache Spark SQL – 13 Amazing Differences
https://www.educba.com/apache-hive-vs-apache-spark-sql/
SparkSQL vs Hive on Spark – Difference and pros and cons?
https://stackoverflow.com/questions/31611744/sparksql-vs-hive-on-spark-difference-and-pros-and-cons
Apache Hive vs Spark SQL: Feature wise comparison
https://data-flair.training/blogs/apache-hive-vs-spark-sql/
快速了解hive
https://mp.weixin.qq.com/s/8A5Saeuhb46i01eiuCJG8g
Hive原理实践
https://mp.weixin.qq.com/s?__biz=MzU5MjgwNzAxNg==&mid=2247483766&idx=1&sn=4b24ac4a4f39bc2670fd1e10d21be1cb
大数据分析工程师入门7–HDFS&YARN基础
https://mp.weixin.qq.com/s/iMDxoS__mJO39TPqK4Yikw
`
HDFS和YARN是大数据生态的基础组件,不过,因为其处于数据分析架构体系的底层,通常我们很少能感受到它们的存在。
但是我们必须要了解它们,因为在某些场景下,我们依然会接触到它们。了解他们并熟悉怎么使用,是大数据分析师必备的技能之一。
首先,还是让我们来回答经典的三个问题:
为什么要讲HDFS和YARN?
鉴于这两大组件如此重要,我们必须要了解其基本原理和概念,一方面可以对工作中排查问题有比较大的帮助,另一方面方便我们与他人沟通交流。
本节课程的目标是什么?
本文主要会从实用的角度出发,结合实际的工作经验,讲解工作中经常提及的HDFS和YARN的核心概念和常用操作。
本文不会去深入剖析讲解其内部的工作原理,更多地是教大家一些工作中实用的技巧。
本文的讲解思路是?
第1部分,HDFS核心概念,讲解必须了解的HDFS各组成部分及作用,方便与他人沟通交流。
第2部分,HDFS常用命令,讲解工作中常用的HDFS命令。
第3部分,HDFS WebUI使用,将教大家怎么使用HDFS的Web页面。
第4部分,YARN核心概念,讲解YARN的基本结构和各组件作用。
第5部分,YARN常用命令,讲解YARN常用操作指令。
第6部分,YARN Web界面使用,讲解如何杀死一个作业、如何查看执行日志等。
`
Hadoop 气数已尽?
https://0x0fff.com/hadoop-the-end-of-an-era
https://mp.weixin.qq.com/s?__biz=MzA5MTc0NTMwNQ==&mid=2650717083&idx=1&sn=4f6b1a94fabd4aea1ec7296a236be774
`
一个时代的结束
所以,我并不是说一些新的突破性技术已经取代了“大数据”,我也不是说 Hadoop 不再是一种可行的技术,不再值得投资。我说的是“大数据”时代即将结束,从炒作的高峰下降到最低点。新的趋势 AI 和 ML,已经取代它们,生命的循环再次开始,新的技术在炒作图上攀升,营销人员推销新软件,以科技巨头的成功为代表,以及传统企业购买这种软件,消灭了下一个科技泡沫。
Hadoop 时代真的结束了吗?
并没有!Hadoop 是一项伟大的技术,但它本质上是一个很好的解决方案,但是只有少数企业真正需要它。作为一项技术,它与提供替代大规模存储解决方案的主要云厂商竞争:AWS 包含 S3,GCP 包含云存储,Microsoft 包含 Azure 存储等。云计算一点一点地吞噬了自建部署市场,云计算提供商及其分布式存储解决方案在我看来是 Hadoop 的主要竞争对手,Hadoop 未来将面临更多的挑战。
`
万亿数据下 Hadoop 的核心竞争力
https://mp.weixin.qq.com/s/6XsPXapbpUFnk26-1S7tjA
`
Hadoop 的组成部分有哪些?能做什么?
截止至本篇文章,Hadoop 社区发布了 Hadoop-3.2.0 版本,其核心组成部分包含:基础公共库 ( Common ) 、分布式文件存储系统 ( HDFS ) 、分布式计算框架 ( MapReduce ) 、分布式资源调度与管理系统 ( YARN ) 、分布式对象存储框架 ( OZone ) 、机器学习引擎 ( Submarine ) 。
Hadoop 的核心竞争力在哪?
5.1 降低大数据成本
5.2 成熟的 Hadoop 生态圈
`
驳「Hadoop 快不行了」
https://mp.weixin.qq.com/s/gMI4VGgX1AxMakTpGK0TzQ
`
我想提醒大家:
不要跟风。我们不求特立独行,但也不要盲目从众。就像学到个网络流行语,就迫不及待乱讲一样,不会让人觉得你多潮多幽默。原创流行语的人才潮,当时的语境下才好笑,而你,只是个复读机(看,不好笑吧?)而已。
不要有思维惰性。我们不求任何事都抱着科学的怀疑态度,但也不要别人说什么都信,哪怕说的人有 100 万粉丝。看到一些观点,尤其是比较有冲击性的观点,先别急着一脸崇拜哇好牛逼啊,或者一脸鄙夷咦什么鬼。结合自己的知识、常识,用数据、逻辑去思考下,花不了多少时间的。
思考事情的本质。我们没有精力对什么事情都刨根问底,但重要的事情需要透过现象思考本质。还是因为思维上的惰性,哪怕确实思考了,也很容易浅尝辄止。这是人性的弱点,很难对抗。但如果这个事情对你特别重要,比如都影响到你后面的职业规划了,那就非常有必要仔细思考了。
其实都是些非常浅显的道理,浅显到我通常都不屑于说。但是大部分人都做不到。但也正因为大部分人都做不到,只要你做到了,就比大部分人都强。并且,做起来真的不难。
`
Spark 编程指南简体中文版
https://doc.yonyoucloud.com/doc/spark-programming-guide-zh-cn/index.html
GraphX编程指南
https://doc.yonyoucloud.com/doc/spark-programming-guide-zh-cn/graphx-programming-guide/index.html
`
GraphX是一个新的(alpha)Spark API,它用于图和并行图(graph-parallel)的计算。GraphX通过引入Resilient Distributed Property Graph:带有 顶点和边属性的有向多重图,来扩展Spark RDD。为了支持图计算,GraphX公开一组基本的功能操作以及Pregel API的一个优化。另外,GraphX包含了一个日益增长的图算法和图builders的 集合,用以简化图分析任务。
从社交网络到语言建模,不断增长的规模和图形数据的重要性已经推动了许多新的graph-parallel系统(如Giraph和GraphLab)的发展。 通过限制可表达的计算类型和引入新的技术来划分和分配图,这些系统可以高效地执行复杂的图形算法,比一般的data-parallel系统快很多。
然而,通过这种限制可以提高性能,但是很难表示典型的图分析途径(构造图、修改它的结构或者表示跨多个图的计算)中很多重要的stages。另外,我们如何看待数据取决于我们的目标,并且同一原始数据可能有许多不同表和图的视图。
结论是,图和表之间经常需要能够相互移动。然而,现有的图分析管道必须组成graph-parallel和data- parallel系统,从而实现大数据的迁移和复制并生成一个复杂的编程模型。
GraphX项目的目的就是将graph-parallel和data-parallel统一到一个系统中,这个系统拥有一个唯一的组合API。GraphX允许用户将数据当做一个图和一个集合(RDD),而不需要 而不需要数据移动或者复杂。通过将最新的进展整合进graph-parallel系统,GraphX能够优化图操作的执行。
`
从0开始学大数据-Hive基础篇
https://mp.weixin.qq.com/s/nmZPCFCul1ERXYM07e1mfQ
从0开始学大数据-Hive性能优化篇
https://mp.weixin.qq.com/s/9OqWPOI8CQ3GDYg4Mx_R_g
从0开始学大数据-数据仓库理论篇
https://mp.weixin.qq.com/s/usOzkPsQOajmlmlN_WlstQ
Hadoop已死?Hadoop万岁!
https://mp.weixin.qq.com/s/7N3m_liLY9-x2LR23vfc3A
https://www.analyticsvidhya.com/blog/2019/09/7-data-science-projects-github-showcase-your-skills/
`
# Hadoop是什么?
首先,从最基本的层面来讲——Hadoop最初是Apache 软件基金会的一个开源项目。后来,Map/Reduce 和 HDFS也分别被纳入这一项目中,很快就形成了一个广泛而丰富的开源生态系统。如今,Cloudera的“Hadoop发行版”(CDH/HDP/CDP)包含30多个开源项目,涵盖存储、计算平台(例如YARN,以及未来的Kubernetes)、批处理/实时计算框架(Spark、Flink等)、编排、SQL、NoSQL、ML、安全/管理等等。
所以,如果把Hadoop仅仅定义为MapReduce,那么,MapReduce的确正在衰落。但这并不妨碍Spark、Flink以及其他技术的兴起——这使客户感到高兴。这就是平台的美妙和强大之处——它可以进化,可以拥抱新的范式。
那么,如果Hadoop不是一个“项目”或“一组项目”,它又是什么呢?
“Hadoop”是一种哲学——是一场运动,是管理和分析数据的现代化体系结构的发展。
从某种层面来说,“Hadoop哲学”对于数据架构来说,就像著名的Unix 哲学对于软件开发一样,Eric Raymond在其著作《Unix编程艺术》中阐述了17条Unix规则,同样适用于该领域:
1. 模块原则:使用简洁的接口拼合简单的部件。
• HDFS, YARN/K8s, Spark, Hive等既可以相互组合,又相互依赖。
3. 组合原则:设计时考虑拼接组合。
• Impala,Hive, Spark等可用于端到端的解决方案。
4. 分离原则:策略同机制分离,接口同引擎分离。
• HDFS既是文件系统接口,也是文件系统实现。这就是Spark通过Hadoop兼容文件系统“API”与S3对话的原因。
6. 吝啬原则:除非确无它法,不要编写庞大的程序。
• 避免出现“大”而“胖”的层,而是使用依赖于其他层的模块化层,例如Phoenix和HBase。
7. 透明性原则:设计要可见,以便审查和调试。
• 开源FTW!
16. 多样原则:决不相信所谓“不二法门”的断言。
• Hadoop生态系统提供了多种工具,因为它们适用于不同的场景,并且具有不同的优势(可以通过Spark或Hive实现ETL,通过Hive/Tez或Impala实现SQL,通过LLAP或SparkSQL实现SQL)。
17. 扩展原则:设计着眼未来,未来总比预想来得快。
• 在2005-2006年时,很难预测到HBase, Hive, Impala, Spark, Flink, Kafka等产品的出现,但在过去13年多的时间里,它们成为了高质产品和堆栈的关键组件,这已经是很好的成果了。
只要有数据,就会有Hadoop。
`
大数据平台架构设计探究
https://mp.weixin.qq.com/s/npRRRDqNUHNjbybliFxOxA
`
近年来,随着IT技术与大数据、机器学习、算法方向的不断发展,越来越多的企业都意识到了数据存在的价值,将数据作为自身宝贵的资产进行管理,利用大数据和机器学习能力去挖掘、识别、利用数据资产。如果缺乏有效的数据整体架构设计或者部分能力缺失,会导致业务层难以直接利用大数据大数据,大数据和业务产生了巨大的鸿沟,这道鸿沟的出现导致企业在使用大数据的过程中出现数据不可知、需求难实现、数据难共享等一系列问题,本文介绍了一些数据平台设计思路来帮助业务减少数据开发中的痛点和难点。
本文主要包括以下几个章节:
1. 本文第一部分介绍一下大数据基础组件和相关知识。
2. 第二部分会介绍lambda架构和kappa架构。
3. 第三部分会介绍lambda和kappa架构模式下的一般大数据架构
4. 第四部分介绍裸露的数据架构体系下数据端到端难点以及痛点。
5. 第五部分介绍优秀的大数据架构整体设计
6. 从第五部分以后都是在介绍通过各种数据平台和组件将这些大数据组件结合起来打造一套高效、易用的数据平台来提高业务系统效能,让业务开发不在畏惧复杂的数据开发组件,无需关注底层实现,只需要会使用SQL就可以完成一站式开发,完成数据回流,让大数据不再是数据工程师才有的技能。
`
快手大数据架构演进实录
https://mp.weixin.qq.com/s/OL4SCe3JdCSLnjWJQ5ZUxg
`
如何看待大数据架构与云架构之间的关系?类似 Hadoop 的大数据技术会在云服务的冲击下逐渐没落吗?
首先再明确下这两个概念:
大数据架构:是为解决大数据业务场景需求的分布式基础服务,其定位可以认为是大数据方向的基础架构。整体上可划分为三个层次:
* 分布式存储层:主要包括各类大数据场景的存储服务,如分布式文件系统(HDFS)、分布式 KV 系统(HBase)以及分布式消息缓存(Kafka)等。主要解决的是海量数据的存储问题(也有相当多的互联网公司利 Kafka 系统进行数据传输接入)
* 分布式调度层:资源调度层目前主要使用的 YARN,提供了一个资源池抽象层,把各类计算引擎作业统一管理与调度。
* 计算引擎层:是面向各类场景的计算引擎,包括解决实时计算场景需求的 Flink 系统,解决离线计算场景的 SQL 类引擎,以及解决交互式分析场景下的 adhoc 以及 olap 引擎。
云架构:是实现云计算能力的底层基础服务与设施,行业内公认的云架构分为三大层次:
* 基础设施层(IaaS,基础设施即服务):将基础设施,例如网络,机器等硬件资源抽象成服务,提供给客户使用,解决了客户在如何采购机器,建设机房,以及构建网络等基础类工作的问题。
* 平台层(PaaS,平台即服务):将平台,例如开发、存储、调度与计算平台等,做整合抽象成服务,为用户提供了开发环境,解决用户快速构建业务服务的能力。
* 软件服务层(SaaS,软件即服务):将软件,例如推送、反作弊等应用,作为服务提供。客户可以根据需求通过互联网向厂商订购,并使用应用软件服务。
从这两个概念上看,大数据架构可以认为是云架构中 PaaS 层的一部分。专注于为客户提供在大数据场景下的业务快速构建能力。大数据架构服务,连同数据生产开发套件一起为面向数据分析的客户提供一体式的 PaaS 层解决方案。从这个方面上看,即使在云架构中,依然会保留大数据架构技术。
从各自发展上来看,创业企业、小型企业以及一部分中型企业,需求相对来说可能会比较简单,出于成本、人力的考虑,会投向云架构提供的服务上,以便快速实现业务逻辑提供产品获取利润。对于大型企业以及一部分中型企业而言,业务体量很大,面临的需求也会变得丰富、个性化且复杂,云架构所提供的服务,不一定能够完全满足具体的场景与需求,此外,如果放到云上,数据本身也存在安全层面的隐患,所以除了成本因素外,还会考虑快速支持、安全等因素,通常会自建大数据架构服务,以便有效支撑企业发展。当然在这些企业中的大数据架构技术并不是简单的拿来应用,与此同时,还会对其进行大量深度定制开发,以便满足企业发展需求。整个大数据架构技术会也会向着服务能力整合统一,以及企业内部云化的方向发展。
所以从上述两个方面看,大数据架构技术并不会没落,且会和云架构一样继续蓬勃发展。
`
大数据:Hive – ORC 文件存储格式
https://www.cnblogs.com/ittangtang/p/7677912.html
Hive生产上,压缩和存储结合使用案例
https://ruozedata.github.io/2018/04/23/Hive%E7%94%9F%E4%BA%A7%E4%B8%8A%EF%BC%8C%E5%8E%8B%E7%BC%A9%E5%92%8C%E5%AD%98%E5%82%A8%E7%BB%93%E5%90%88%E4%BD%BF%E7%94%A8%E6%A1%88%E4%BE%8B/
Hive ORC
https://www.jianshu.com/p/36e4f0137744
如何通俗地理解Hive的工作原理?
https://www.zhihu.com/question/49969423
`
# Hive解决了什么问题
在Hadoop项目中,HDFS解决了文件分布式存储的问题,MapReduce解决了数据处理分布式计算的问题,HBase解决了一种数据的存储和检索。
那么要对存在HDFS上的文件或HBase中的表进行查询时,是要手工写一堆MapReduce类的。
一方面,这真的很麻烦,另一方面,只能由懂MapReduce的程序员来编写。
对于业务人员或数据科学家,非常不方便。这些人已经习惯了通过SQL与RDBMS打交道,因此如果有sql方式查询文件和数据就很有必要,这就是hive要满足的需求。
`
Hive的架构和原理
https://blog.csdn.net/qq_33054265/java/article/details/87970144
`
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL(HQL)查询功能。Hive是将HQL转化为MapReduce程序,Hive处理的数据存储在HDFS上,执行程序运行在Yarn上。由于执行的是MapReduce程序,延迟比较高(还有一个重要的原因是,没有索引而需要扫描整个表),因此Hive常用于离线的数据分析。
`
Hive从概念到原理
https://blog.csdn.net/qq_38048590/java/article/details/82345411
`
Hive是一个数据仓库基础工具,它是建立在Hadoop之上的数据仓库,在某种程度上可以把它看做用户编程接口(API),本身也并不存储和处理数据,依赖于HDFS存储数据,依赖MR处理数据。它提供了一系列对数据进行提取、转换、加载的工具。依赖于HDFS存储数据,依赖MR处理数据。在Hadoop中用来处理结构化数据。Hive查询语言采用Hive为MapReduce处理结构化数据。Hive不是实时查询语言。
`
hive基本概念原理与底层架构
https://blog.csdn.net/u013129109/article/details/81453582
有哪些大数据处理工具?
https://mp.weixin.qq.com/s/bFXjaGCkbvz60f_ry7ozBQ
`
Apache Hadoop
Apache Hadoop HBase & Kudu
Apache Spark
Apache Flink
Apache Impala
Apache Zookeeper
Apache Sqoop
Apache Flume
Apache Kafka
Apache Ranger & Sentry
Apache Atlas
Apache Kylin
Apache Hive & Tez
Apache Presto
Apache Parquet & Orc
Apache Griffin
Apache Zeppelin
Apache Superset
Tableau
TPCx-BB
`
https://mattturck.com/category/big-data/
万字详解整个数据仓库建设体系(好文值得收藏)
https://mp.weixin.qq.com/s/h6HnkROzljralUj2aZyNUQ
`
# 数据仓库概念:
英文名称为Data Warehouse,可简写为DW或DWH。数据仓库的目的是构建面向分析的集成化数据环境,为企业提供决策支持(Decision Support)。它出于分析性报告和决策支持目的而创建。
数据仓库本身并不“生产”任何数据,同时自身也不需要“消费”任何的数据,数据来源于外部,并且开放给外部应用,这也是为什么叫“仓库”,而不叫“工厂”的原因。
# 基本特征:
数据仓库是面向主题的、集成的、非易失的和时变的数据集合,用以支持管理决策。
==
数据库与数据仓库的区别实际讲的是 OLTP 与 OLAP 的区别。
操作型处理,叫联机事务处理 OLTP(On-Line Transaction Processing,),也可以称面向交易的处理系统,它是针对具体业务在数据库联机的日常操作,通常对少数记录进行查询、修改。用户较为关心操作的响应时间、数据的安全性、完整性和并发支持的用户数等问题。传统的数据库系统作为数据管理的主要手段,主要用于操作型处理,像Mysql,Oracle等关系型数据库一般属于OLTP。
分析型处理,叫联机分析处理 OLAP(On-Line Analytical Processing)一般针对某些主题的历史数据进行分析,支持管理决策。
数据库设计是尽量避免冗余,一般针对某一业务应用进行设计,比如一张简单的User表,记录用户名、密码等简单数据即可,符合业务应用,但是不符合分析。数据仓库在设计是有意引入冗余,依照分析需求,分析维度、分析指标进行设计。
`
数仓到底要分多少层? | 彭文华
https://mp.weixin.qq.com/s?__biz=MzIwNjM0MTc0Ng==&mid=2247485946&idx=1&sn=50a8f5f5ae85f28a137b1d6b8b7e2731
Hadoop学习与面试8000字,收藏这一篇就够了
https://mp.weixin.qq.com/s/cXpQmBRtMMxqpWpCG3F6FA
`
1. HDFS读流程和写流程?
2. NameNode和Secondary NameNode工作机制?
3. HA NameNode如何工作?
4. DataNode工作机制?
5. DataNode数据损坏怎么办?
6. 压缩方式怎么选择?
7. MapReduce工作流程?
8. Yarn工作机制(作业提交全过程)是什么?
9. Yarn调度器了解多少?
10. HDFS小文件怎么处理?
11. Shuffle及优化?
12. Hadoop解决数据倾斜方法?
13. Hadoop的参数优化?
14. 异构存储(冷热数据分离)你了解吗?
`
Hadoop生态系统:处理大数据的Hadoop工具
https://www.edureka.co/blog/hadoop-ecosystem
https://www.edureka.co/blog/hadoop-tutorial/
`
以下是Hadoop组件,它们共同构成了Hadoop生态系统,我将在这篇博客中逐一介绍:
* HDFS -> Hadoop分布式文件系统
* YARN ->另一个资源协商器
* MapReduce ->数据处理使用编程
* Spark ->内存数据处理
* PIG, HIVE->使用查询(类sql)的数据处理服务
* HBase -> NoSQL数据库
* Mahout, Spark MLlib ->机器学习
* Apache Drill -> SQL on Hadoop
* Zookeeper ->管理集群
* Oozie -> Job Scheduling
* Flume, Sqoop ->数据摄取服务
* Solr & Lucene ->搜索和索引
* Ambari ->配置、监控和维护集群
`