=Start=
缘由:
最近一段时间才关注的Gartner的技术成熟度曲线(Hype Cycle),之前有看过,但没有详细了解,现在趁着机会好好了解学习一下。
正文:
参考解答:
以Gartner发布的2017年数据安全技术成熟度曲线为例,学习如何阅读和使用技术成熟度曲线。
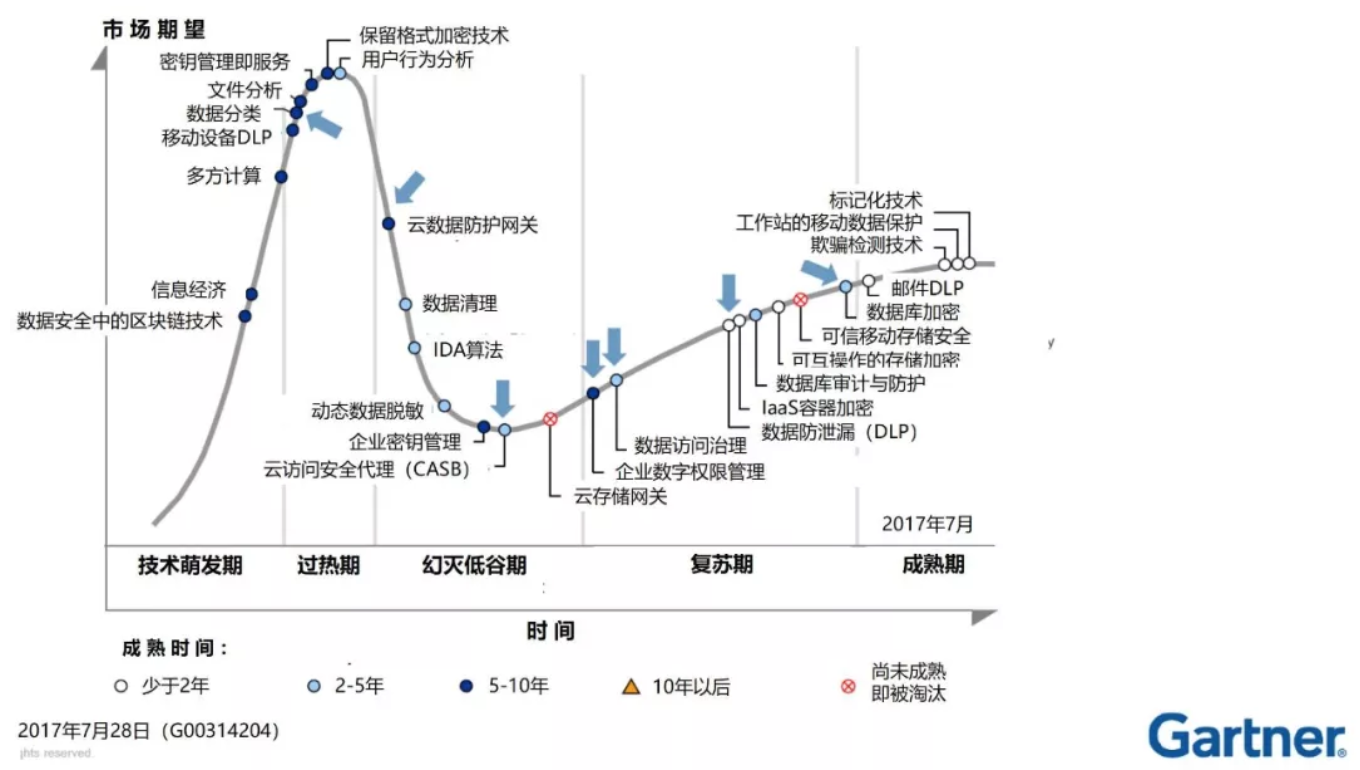
产品推出、著名公司采用、媒体兴趣爆发、新法规新需求等触发事件触发一个新的技术或其它创新点进入商品市场。
(2)过热期(Peak of Inflated Expectations)
所有媒体都在争相报道这种技术和成功案例;销售材料中也频频出现这一技术术语;市场上充满了重复的、竞争的、互补的产品。
对于过热期的数据安全技术方向,不应仅以它的热度就盲目采用,而应结合自身业务,尽早展开全方面评估后再作投资决定。
(3)幻灭低谷期(Trough of Disillusionment)
市场中不断出现失败案例,越来越多企业开始认识到这个新技术的运用并不像最初看起来那么容易;媒体也转而报道这种技术是挑战不是机遇;这项技术由于达不到公众预期,声誉迅速下滑。
正在钻研幻灭低谷期技术的兄弟姐妹们不用灰心。不管你研究CASB、动态数据脱敏,还是企业密钥管理等等,一步一脚印,不久就会苦尽甘来。
(4)复苏期(Slope of Enlightenment)
这个爬坡过程将持续1-3年。相应供应商发布二代或三代产品、媒体开始关注逐渐成熟的功能和主流供应商的市场动态、新的成功案例开始出现……
(5)成熟期(Plateau of Productivity)
该技术的实际收益可预测并已得到普遍认可,甚至还会围绕该创新内容出现相关产品和服务的“生态系统”(生态系统组成部分中可能会出现新的技术成熟度曲线)。
技术成熟度曲线的重要性
参考链接:
=END=
《 “[collect]技术成熟度曲线的使用方法” 》 有 10 条评论
我们是否应当克制对新技术的追求?
https://yuhao.space/blog/2019/02/should-we-restraint-from-seeking-new-tech
`
新技术肯定有新的价值,这一点毫无疑问,我也无意否定开发者求新求变的理想和追求。但在追逐新技术的同时,请不要忘了我们的“老”技术,不管你用或不用,它们就在那里。
最后,我还是想引用 《Docker:一场令人追悔莫及的豪赌》一文对旧技术的评价,因为这段文字深得我心:
无聊的好处(限制水平较高)在于,这些东西的功能相对更容易理解。而更重要的是,我们能够更轻松地了解其故障模式。……但对于闪闪发光的新技术而言,其中的未知因素要多得多,这一点非常重要。
换句话来说,已经存在了十年的软件更易于理解,而且未知因素更少。未知因素越少,运营开销越低,这绝不是坏事。
`
如何正确地引用 Gartner 报告
https://mp.weixin.qq.com/s/8r69pgf2XCNsSiTtRBhjVg
`
近两年越来越多国内厂商出现在 Gartner 报告中,想起之前的一点工作经验,在此跟大家分享,希望能有所帮助。引用的核心是,遵循 Gartner 强调自身中立性和独立性的原则。
我当时任职的公司每年都会购买 Gartner 服务。印象中在首年购买后,负责 AR 的领导就组织大家学习了 Gartner 引用规范,确保在外部营销上的专业性和规范性。2014年,当时我们的产品第一次进入魔力象限 MQ(其实这也是 Gartner 第一次针对该产品发布 MQ 报告)。我当时在为负责国际业务的同事准备用于英文官网的新闻稿(Press Release)、banner 以及 tagline。根据 Gartner 引用规范要求,这些内容需要向对方提交审核。我印象中有3点明确的要求:
1、厂商引用 Gartner 研究内容的外部材料中,都必须包含 Gartner 的免责声明;
2、MQ 的图片(也即各厂商在 MQ 象限中的位置)不能用于新闻稿、广告、白皮书等外部营销材料中;
3、需要购买报告的授权 reprint 后,才能外部分发使用。在此前提下,MQ 图片可以出现在官网的 banner 中,作为推广已购买的 reprint 入口。另外,针对 MQ 图片的应用,也需要包含对应的免责声明。
其实,确保引用正确最简单的做法就是,外部营销材料发布之前,提交原始版本给 Gartner 进行审核,按照对方要求来进行就好了。
`
https://www.gartner.com/en/about/policies/copyright
https://emtemp.gcom.cloud/ngw/globalassets/en/about/documents/MQ_MG_examples_v4.pdf
APT防护十年:终于有人把SOAR这件事讲清楚了
https://mp.weixin.qq.com/s/ltOmc7ANiLqEoKnY2VidRQ
`
Security Orchestration, Automation and Response
安全编排,自动化和响应
`
安全编排、自动化及响应(SOAR)平台的进化
https://mp.weixin.qq.com/s/QQZygeog-mOvE_ZAD4ZWEA
https://www.csoonline.com/article/3270957/security/the-evolution-of-security-operations-automation-and-orchestration.html
Gartner技术成熟度曲线(Gartner Hype Cycle)
https://www.gartner.com/en/research/methodologies/gartner-hype-cycle
安全热点〡Gartner发布2019年漏洞评估市场指南
https://mp.weixin.qq.com/s/ecL5q4-sxixmCP6ZsDHuqQ
`
# 漏洞评估市场定义
漏洞评估市场由提供基于漏洞的识别、分类、优先级排序和协调修复等相关能力的供应商组成。无论是在本地、云端还是在虚拟环境中交付,漏洞评估产品或或服务都具有以下几种能力:
发现识别并报告设备、操作系统和软件中的漏洞;
报告IT资产安全配置;
识别并跟踪系统的状态基线情况;
结合威胁情报、机器学习等分析技术,关联漏洞严重性、资;产重要性、攻击者手段,为风险评估提供支持;
为安全团队提供漏洞修复优先级指导和建议。
漏洞评估市场不仅仅包含产品,也包含相应的服务,这些服务旨在帮助最终用户执行漏洞评估工作。托管安全服务提供商、检测与响应服务提供商可以长期提供“漏洞评估即服务”,以这种方式交付的能力仍然是许多组织的选择。合规仍然是漏洞评估市场的主要驱动力。
漏洞优先级技术(VPT)作为一个新技术点,推动了漏洞评估能力的提升。作为威胁和漏洞管理(TVM)的替代者,漏洞优先级技术(VPT)解决方案结合漏洞评估报告、资产重要性、威胁情报等数据,通过高级分析技术,为安全管理人员提供漏洞修复优先级指导,以在最短的时间内利用有效的资源进行漏洞修复,减少攻击面。漏洞优先级技术(VPT)主要由一些技术型初创企业提供,并且作为功能订阅集成在传统的漏洞扫描产品中。
漏洞评估(VA)
动态应用安全测试(DAST)
动态应用安全测试(DAST)
云安全态势评估
运营技术评估(OT)
漏洞优先级技术(VPT)
突破与攻击模拟测试(BAS)
渗透测试
漏洞悬赏与安全众测
漏洞风险影响分析和修复优先级
`
左耳朵耗子:技术人如何更好地把控发展趋势?
https://mp.weixin.qq.com/s/Cedl9lIk2mAd9b_NUCnj_g
`
从我二十多年的工作经历来看,期间经历了很多技术的更新换代,整个技术模式、业务模式也是一直变来变去,所以本期内容针对这一话题,谈一谈技术人员应该怎样适应这样一种变化?
第一,如果想要把控技术,应对这个世界的一些变化,需要大致知道这个世界的一些规律和发展趋势,另外还得认识自己,自己到底适合做什么?在这个趋势和规律下属于自己的发挥领域到底是什么?这是我们每个人都需要了解的。
第二,打牢基础,以不变应万变,不管世界怎样变化,我都能很快适应它。
第三,提升成长的效率,因为现在社会的节奏实在太快了,比二十年前快得太多,技术层出不穷,所以我们的成长也要更有效率。效率并不单指的快,效率是怎么样更有效,是有用工除以总工,怎么学到更有效的东西,或者怎么更有效学习,是我们需要掌握的另一关键。
1. 学习方法
学习方法要主动学习,主动学习我们称之为深度学习,如果你不能深度学习,即使十年时间花费出去,也没有任何意义。
(1)挑选一手知识和信息源
对于学习方法:第一我们一定要到知识源去挑选知识,知识信息源非常关键,二手信息丢失太大了,谭浩强写的书就丢失太多信息了。
目前计算机一手知识基本都是国外的,所以英文非常重要。我鼓励大家一定读第一手的资料。如果你英语有问题,至少要看翻译过来,最好是原汁原味翻译的,不要我理解了给你讲那种,那种也是被别人嚼一遍再讲给你你没有体会,是别人带着你,别人的体会会影响你,也许你的体会会比他更好,因为是你自己总结出来的东西,所以知识源很重要。
(2)注意原理和基础
第二要注重基础原理。虽然可以忘记这个技术,但是原理记在心里,我可以徒手实现出来,而且通过原理可以更快学习其他类似的技术。所以原理很重要!当你学会C、C++要学Java和GO都很快。
(3)使用知识图谱
一定要学会使用知识图,把知识结构化。大家都说C++最难学,C++三大块,第一是解决C语言的问题,第二面向对象,第三是STL;C语言有指针问题、有宏问题。
对于TCP协议,首先第一个要记住状态图,怎么建立连接,怎么断连接,状态怎么变迁。TCP没有连接,是靠状态维护连接的。
其次,要了解TCP怎么保证可靠性,就是丢包以后怎么重传。
然后,重传会带来拥塞控制,发的速度和收的速度不一定对等,或者网络上的速度不一定对等,涉及到拥塞控制。这就是TCP基本三大块,顺着这个脉络一点点往下想,比如说怎么做拥塞控制,滑动窗口消息技术,怎么测试重传等等类似这样的有很多算法。所以你用知识图关联就可以进行顺藤摸瓜。
不需要记所有知识,那些手册的知识不需要记,你知道在哪里能找到就可以了。你脑子里面要有地图,学一个东西就跟在城市生活一样,闭上眼睛就知道地图,A点到B点怎么去大概方向要知道。我在北京我去广州,广州在南边,我大概坐飞机还是火车要心里有数。虽然不用记住所有的细节,但是大概知道我去找谁,我就可以知道怎么找到那个地方,你不需要记住所有知识,你记住大概地图,要记住基本的方法和原理,知道在哪里可以找到他就可以了。
(4)学会举一反三
举一反三,就是用不同方法学一个东西,比如说学TCP协议,看书是一种方法,编程是另外一种方法,还有用做Debug去看的,用不同方法学一个东西会让你更加熟悉,你学一个知识的同时把周边也学了。比如说学前端能不能把HTCP学一下,比如说长连接、短连接,包括hp1、hp2有一些不一样的东西。
(5)总结和归纳
一定要学会总结和归纳,形成自己的思维框架、自己的套路、自己的方法论,以后学这个东西应该怎么学。就像学一门新的语言,不管GO语言,还是Rust语言,第一件事情就是了解内存是怎么管理的,第二是范性怎么管,并发怎么弄。还有一些抽象怎么弄,比如说怎么解耦,怎么实现多态?
套路这种东西只有学的多了以后才能形成套路,如果你只学会一门语言不会有套路,你要学C、C++,每年学门语言,不用学多精,你思考这个语言有什么不一样,为什么这个这种有玩法,那个有那种玩法,这些东西思考多了套路方法论就出来了。
比如说Windows和Linux有什么不同,Linux和UNIX又有什么不同?只有总结自己的框架、套路和方法,这些才永远不会被淘汰。
(6)实践和坚持
剩下就是多做多练,多坚持,只有实践才会有经验,只有锻炼了才能够把自己的脂肪变没,所以要把知识变成技能必须练,就像小学生学会加减乘除,还是要演练,必须多做题,题目做得多了,自然掌握得好。
要挑选好的知识源,注重原理技术,有一些原理的基础的书太枯燥,但是我告诉你学习基础太值得投入时间,搬砖赚几十元不值得,因为赚的是辛苦钱,老了就赚不了,必须要赚更有能力的钱,这是学习投资。
`
Gartner 2020数据和分析技术十大趋势预测解读
https://www.secrss.com/articles/17729
`
趋势一:增强分析(Augmented Analytics)
趋势二 增强数据管理(Augmented data Management)
趋势三 NLP和会话分析(NLP/Conversational Analytics)
趋势四 图分析(Graph)
趋势五 商业化AI和ML(Commercial AI and ML)
趋势六 数据结构(Data Fabric)
趋势七 可解释的AI(Explainable AI)
趋势八 持续智能(Continuous Intelligence)
趋势九 区块链(Blockchain)
趋势十 持久性内存服务(Persistent Memory Servers)
`
Gartner预测2019年十大「数据和分析技术」趋势:增强型分析成为重要卖点
https://mp.weixin.qq.com/s/HwiChfm9KWqq4aO4EQ-IeQ
`
趋势 1:增强型数据分析(Augmented Analytics)
趋势 2:增强型数据管理(Augmented data Management)
趋势 3:持续型智能(Continuous Intelligence)
趋势 4:可解释的 AI(Explainable AI)
趋势 5:图形分析(Graph)
趋势 6:数据结构(Data Fabric)
趋势 7:NLP /会话分析(NLP/Conversational Analytics)
趋势 8:商用的人工智能和机器学习(Commercial AI and ML)
趋势 9:区块链(Blockchain)
趋势 10:持久性内存服务器(Persistent Memory Servers)
`
https://www.gartner.com/en/newsroom/press-releases/2019-02-18-gartner-identifies-top-10-data-and-analytics-technolo
https://www.information-age.com/gartner-data-and-analytics-technology-trends-123479234/
五道口大模型简史
https://mp.weixin.qq.com/s/fm37ofUwLQyItKkkLMjG5Q
`
「预见未来最好的方式就是亲手创造未来。」
AI 有三大方向:计算机视觉(CV)、自然语言处理(NLP)与机器学习(ML),其中 NLP 的终极目标是让计算机理解人类语言。
`
阐述说明NLP发展历史,以及 NLP与chatgpt的关系
https://mp.weixin.qq.com/s/DROj4HP4KpIZUZ1uymc1DQ
`
自然语言处理(Natural Language Processing,NLP)是人工智能(AI)领域的一个重要分支,关注计算机与人类(自然)语言之间的交互。NLP的目标是使计算机能够理解、生成和解释自然语言,从而实现人机交流、信息提取、自动文摘等功能。NLP的发展历史可以分为几个阶段:
1. 1950-1960年代:早期尝试
在这个阶段,NLP的研究基于规则和模式匹配。其中,最著名的项目是ELIZA(1964-1966),一个基于模式匹配的早期对话系统,可以与用户进行有限的自然语言交流。
2. 1970-1980年代:基于知识的方法
这个时期的NLP研究转向基于知识的方法,包括生成语法、语义网络和基于规则的专家系统。1970年代末,基于框架的语义理论开始兴起,为NLP提供了更为丰富的语义表达能力。
3. 1980-1990年代:统计方法
随着计算机处理能力的提高和大规模语料库的出现,NLP开始引入统计方法。在这个阶段,基于概率模型的方法开始广泛应用于词性标注、句法分析和机器翻译等任务。
4. 2000年代:机器学习
这个时期,NLP研究开始广泛使用机器学习方法,如支持向量机(SVM)、隐马尔可夫模型(HMM)和条件随机场(CRF)等。这些方法在诸如命名实体识别、关系抽取和情感分析等任务上取得了显著的成功。
5. 2010年代至今:深度学习
随着深度学习的兴起,NLP领域开始采用神经网络模型,如循环神经网络(RNN)、长短时记忆网络(LSTM)和Transformer等。这些模型在语言模型、机器翻译和文本分类等任务上取得了突破性进展。特别是最近几年,预训练语言模型(如BERT、GPT)的出现,使NLP任务的性能达到了前所未有的水平。
关于NLP与ChatGPT的关系:
ChatGPT(Chatbot based on Generative Pre-trained Transformer)是基于预训练Transformer模型的一种智能聊天机器人。它是NLP领域最新研究成果的一个应用实例。通过对大量文本数据进行预训练,GPT模型能够捕捉到自然语言的语法、语义和语用信息。在微调阶段,GPT模型可以根据特定任务的要求进一步优化,从而实现与用户的自然语言交流。因此,ChatGPT可以看作是NLP发展历史上深度学习时代的一个重要产物。
`
一文看懂自然语言处理-NLP(4个典型应用+5个难点+6个实现步骤)
https://mp.weixin.qq.com/s/H-v3Bnem64TuA6yoaEkuoA
`
网络上有海量的文本信息,想要处理这些非结构化的数据就需要利用 NLP 技术。
本文将介绍 NLP 的基本概念,2大任务,4个典型应用和6个实践步骤。
“语言理解是人工智能领域皇冠上的明珠” ——比尔·盖茨
# 总结
自然语言处理(NLP)就是在机器语言和人类语言之间沟通的桥梁,以实现人机交流的目的。
NLP的2个核心任务:
1.自然语言理解 – NLU
2.自然语言生成 – NLG
NLP 的5个难点:
1.语言是没有规律的,或者说规律是错综复杂的。
2.语言是可以自由组合的,可以组合复杂的语言表达。
3.语言是一个开放集合,我们可以任意的发明创造一些新的表达方式。
4.语言需要联系到实践知识,有一定的知识依赖。
5.语言的使用要基于环境和上下文。
NLP 的4个典型应用:
1.情感分析
2.聊天机器人
3.语音识别
4.机器翻译
NLP 可以使用传统的机器学习方法来处理,也可以使用深度学习的方法来处理。2 种不同的途径也对应着不同的处理步骤。详情如下:
方式 1:传统机器学习的 NLP 流程
1.语料预处理
2.中文语料预处理 4 个步骤(下文详解)
3.英文语料预处理的 6 个步骤(下文详解)
4.特征工程
5.特征提取
6.特征选择
7.选择分类器
方式 2:深度学习的 NLP 流程
1.语料预处理
2.中文语料预处理 4 个步骤(下文详解)
3.英文语料预处理的 6 个步骤(下文详解)
4.设计模型
5.模型训练
英文NLP语料预处理的6个步骤
1.分词 – Tokenization
2.词干提取 – Stemming
3.词形还原 – Lemmatization
4.词性标注 – Parts of Speech
5.命名实体识别 – NER
6.分块 – Chunking
中文NLP语料预处理的4个步骤
1.中文分词 – Chinese Word Segmentation
2.词性标注 – Parts of Speech
3.命名实体识别 – NER
4.去除停用词
`