=Start=
缘由:
整理一些看到的觉得不错的和Flink相关的资料,方便以后要用的时候参考。
正文:
参考解答:
Flink简介
Flink核心是一个流式的数据流执行引擎,其针对数据流的分布式计算提供了数据分布、数据通信以及容错机制等功能。基于流执行引擎,Flink提供了诸多更高抽象层的API以便用户编写分布式任务:
- DataSet API,对静态数据进行批处理操作,将静态数据抽象成分布式的数据集,用户可以方便地使用Flink提供的各种操作符对分布式数据集进行处理,支持Java、Scala和Python。
- DataStream API,对数据流进行流处理操作,将流式的数据抽象成分布式的数据流,用户可以方便地对分布式数据流进行各种操作,支持Java和Scala。
- Table API,对结构化数据进行查询操作,将结构化数据抽象成关系表,并通过类SQL的DSL对关系表进行各种查询操作,支持Java和Scala。
Flink中的一些基本概念
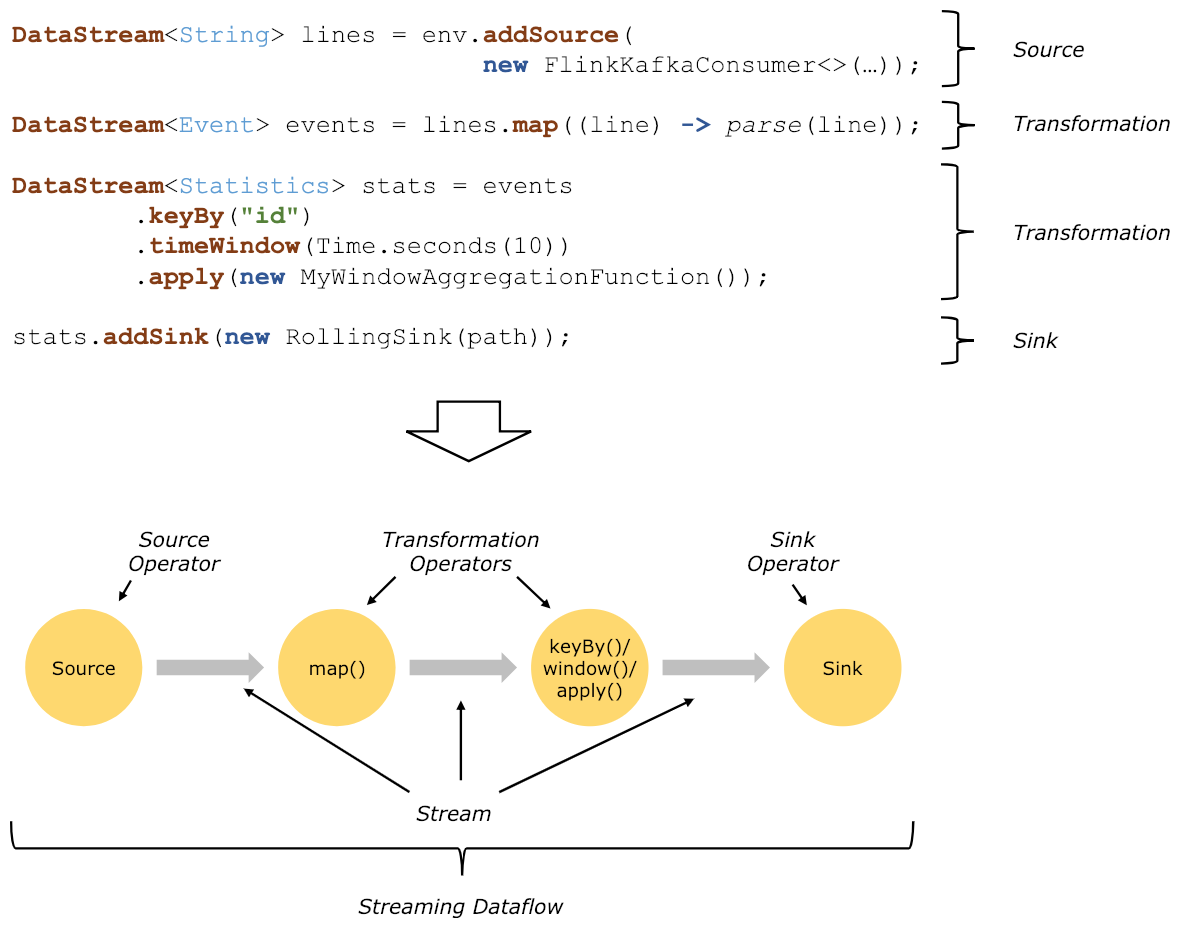
Flink程序的基本构建块是streams和transformations(注意,DataSet在内部也是一个stream)。一个stream可以看成一个中间结果,而一个transformations是以一个或多个stream作为输入的某种operation,该operation利用这些stream进行计算从而产生一个或多个result stream。
在运行时,Flink上运行的程序会被映射成streaming dataflows,它包含了streams和transformations operators。每一个dataflow以一个或多个sources开始以一个或多个sinks结束。dataflow类似于任意的有向无环图(DAG),当然特定形式的环可以通过iteration构建。在大部分情况下,程序中的transformations跟dataflow中的operator是一一对应的关系。但有时候,一个transformation可能对应多个operator。
统一的批处理与流处理系统
在大数据处理领域,批处理任务与流处理任务一般被认为是两种不同的任务,一个大数据项目一般会被设计为只能处理其中一种任务,例如Apache Storm、Apache Smaza只支持流处理任务,而Aapche MapReduce、Apache Tez、Apache Spark只支持批处理任务。Spark Streaming是Apache Spark之上支持流处理任务的子系统,看似一个特例,实则不然——Spark Streaming采用了一种micro-batch的架构,即把输入的数据流切分成细粒度的batch,并为每一个batch数据提交一个批处理的Spark任务,所以Spark Streaming本质上还是基于Spark批处理系统对流式数据进行处理,和Apache Storm、Apache Smaza等完全流式的数据处理方式完全不同。通过其灵活的执行引擎,Flink能够同时支持批处理任务与流处理任务。
在执行引擎这一层,流处理系统与批处理系统最大不同在于节点间的数据传输方式。对于一个流处理系统,其节点间数据传输的标准模型是:当一条数据被处理完成后,序列化到缓存中,然后立刻通过网络传输到下一个节点,由下一个节点继续处理。而对于一个批处理系统,其节点间数据传输的标准模型是:当一条数据被处理完成后,序列化到缓存中,并不会立刻通过网络传输到下一个节点,当缓存写满,就持久化到本地硬盘上,当所有数据都被处理完成后,才开始将处理后的数据通过网络传输到下一个节点。这两种数据传输模式是两个极端,对应的是流处理系统对低延迟的要求和批处理系统对高吞吐量的要求。Flink的执行引擎采用了一种十分灵活的方式,同时支持了这两种数据传输模型。Flink以固定的缓存块为单位进行网络数据传输,用户可以通过缓存块超时值指定缓存块的传输时机。如果缓存块的超时值为0,则Flink的数据传输方式类似上文所提到流处理系统的标准模型,此时系统可以获得最低的处理延迟。如果缓存块的超时值为无限大,则Flink的数据传输方式类似上文所提到批处理系统的标准模型,此时系统可以获得最高的吞吐量。同时缓存块的超时值也可以设置为0到无限大之间的任意值。缓存块的超时阈值越小,则Flink流处理执行引擎的数据处理延迟越低,但吞吐量也会降低,反之亦然。通过调整缓存块的超时阈值,用户可根据需求灵活地权衡系统延迟和吞吐量。
在统一的流式执行引擎基础上,Flink同时支持了流计算和批处理,并对性能(延迟、吞吐量等)有所保障。相对于其他原生的流处理与批处理系统,并没有因为统一执行引擎而受到影响从而大幅度减轻了用户安装、部署、监控、维护等成本。
Flink流处理的时间窗口
对于流处理系统来说,流入的消息不存在上限,所以对于聚合或是连接等操作,流处理系统需要对流入的消息进行分段,然后基于每一段数据进行聚合或是连接。消息的分段即称为窗口,流处理系统支持的窗口有很多类型,最常见的就是时间窗口,基于时间间隔对消息进行分段处理。本节主要介绍Flink流处理系统支持的各种时间窗口。
对于目前大部分流处理系统来说,时间窗口一般是根据Task所在节点的本地时钟进行切分,这种方式实现起来比较容易,不会产生阻塞。但是可能无法满足某些应用需求,比如:
消息本身带有时间戳,用户希望按照消息本身的时间特性进行分段处理。
由于不同节点的时钟可能不同,以及消息在流经各个节点的延迟不同,在某个节点属于同一个时间窗口处理的消息,流到下一个节点时可能被切分到不同的时间窗口中,从而产生不符合预期的结果。
Flink支持3种类型的时间窗口,分别适用于用户对于时间窗口不同类型的要求:
- Operator Time。根据Task所在节点的本地时钟来切分的时间窗口。
- Event Time。消息自带时间戳,根据消息的时间戳进行处理,确保时间戳在同一个时间窗口的所有消息一定会被正确处理。由于消息可能乱序流入Task,所以Task需要缓存当前时间窗口消息处理的状态,直到确认属于该时间窗口的所有消息都被处理,才可以释放,如果乱序的消息延迟很高会影响分布式系统的吞吐量和延迟。
- Ingress Time。有时消息本身并不带有时间戳信息,但用户依然希望按照消息而不是节点时钟划分时间窗口,例如避免上面提到的第二个问题,此时可以在消息源流入Flink流处理系统时自动生成增量的时间戳赋予消息,之后处理的流程与Event Time相同。Ingress Time可以看成是Event Time的一个特例,由于其在消息源处时间戳一定是有序的,所以在流处理系统中,相对于Event Time,其乱序的消息延迟不会很高,因此对Flink分布式系统的吞吐量和延迟的影响也会更小。
参考链接:
- Flink中的一些核心概念
https://ci.apache.org/projects/flink/flink-docs-release-1.0/concepts/concepts.html - 深入理解Apache Flink核心技术
- Flink的一些样例
https://github.com/apache/flink/tree/master/flink-examples/flink-examples-streaming/src/main/java/org/apache/flink/streaming/examples - 求求你大蕉别学了之 Flink No.127
- 自从flink成熟之后,spark是否慢慢成为鸡肋?
=END=
《 “Flink学习资料整理” 》 有 10 条评论
基于Flink的超大规模在线实时反欺诈系统的建设与实践
https://mp.weixin.qq.com/s/5opaOA9Rqk-3Sb-9bBRPJQ
Flink(0)——基于flink的流计算
http://lxwei.github.io/posts/Flink(0)-%E5%9F%BA%E4%BA%8EFlink%E7%9A%84%E6%B5%81%E8%AE%A1%E7%AE%97.html
Flink(1)——基于flink sql的流计算平台设计
http://lxwei.github.io/posts/Flink(1)-%E5%9F%BA%E4%BA%8EFlink-SQL%E7%9A%84%E6%B5%81%E8%AE%A1%E7%AE%97%E5%B9%B3%E5%8F%B0%E8%AE%BE%E8%AE%A1.html
Flink(2)——apache flink 介绍
http://lxwei.github.io/posts/Flink(2)-Apache-Flink-%E4%BB%8B%E7%BB%8D.html
Flink(3)——apache flink event time 与 watermark
http://lxwei.github.io/posts/Flink(3)-Apache-Flink-Event-Time-%E4%B8%8E-Watermark.html
Flink(4)——source 介绍与实践
http://lxwei.github.io/posts/Flink(4)-Source-%E4%BB%8B%E7%BB%8D%E4%B8%8E%E5%AE%9E%E8%B7%B5.html
Flink(5)——sink 介绍与实践
http://lxwei.github.io/posts/Flink(5)-Sink-%E4%BB%8B%E7%BB%8D%E4%B8%8E%E5%AE%9E%E8%B7%B5.html
Flink 全网最全资源
https://paper.tuisec.win/detail/072a257157dd79a
https://toutiao.io/posts/mgn9s3/preview
http://www.54tianzhisheng.cn/2019/12/31/Flink-resources/
https://github.com/zhisheng17/flink-learning
零基础学Flink:UDF
https://mp.weixin.qq.com/s/Z5VbxdEuH151nVh_kQAY4A
零基础学Flink:CEP复杂事件处理
https://mp.weixin.qq.com/s/pJo77xLXafQF1W82Idr6Hw
揭秘|每秒千万级的实时数据处理是怎么实现的?
https://mp.weixin.qq.com/s/Us3Eg-CbAMPHQXxyqh9rVQ
`
1、设计背景
闲鱼目前实际生产部署环境越来越复杂,横向依赖各种服务盘宗错节,纵向依赖的运行环境也越来越复杂。当服务出现问题的时候,能否及时在海量的数据中定位到问题根因,成为考验闲鱼服务能力的一个严峻挑战。
线上出现问题时常常需要十多分钟,甚至更长时间才能找到问题原因,因此一个能够快速进行自动诊断的系统需求就应用而生,而快速诊断的基础是一个高性能的实时数据处理系统。
这个实时数据处理系统需要具备如下的能力:
1、数据实时采集、实时分析、复杂计算、分析结果持久化。
2、可以处理多种多样的数据。包含应用日志、主机性能监控指标、调用链路图。
3、高可靠性。系统不出问题且数据不能丢。
4、高性能,底延时。数据处理的延时不超过3秒,支持每秒千万级的数据处理。
本文不涉及问题自动诊断的具体分析模型,只讨论整体实时数据处理链路的设计。
2、输入输出定义
为了便于理解系统的运转,我们定义该系统整体输入和输出如下:
输入:
服务请求日志(包含traceid、时间戳、客户端ip、服务端ip、耗时、返回码、服务名、方法名)
环境监控数据(指标名称、ip、时间戳、指标值)。比如cpu、 jvm gc次数、jvm gc耗时、数据库指标。
输出:
一段时间内的某个服务出现错误的根因,每个服务的错误分析结果用一张有向无环图表达。(根节点即是被分析的错误节点,叶子节点即是错误根因节点。叶子节点可能是一个外部依赖的服务错误也可能是jvm异常等等)。
3、架构设计
在实际的系统运行过程中,随着时间的推移,日志数据以及监控数据是源源不断的在产生的。每条产生的数据都有一个自己的时间戳。而实时传输这些带有时间戳的数据就像水在不同的管道中流动一样。
如果把源源不断的实时数据比作流水,那数据处理过程和自来水生产的过程也是类似的:
自然地,我们也将实时数据的处理过程分解成采集、传输、预处理、计算、存储几个阶段。
## 预处理
实时数据预处理部分采用blink流计算处理组件(开源版本叫做flink,blink是阿里在flink基础上的内部增强版本)。目前常用的实时流计算开源产品有Jstorm、SparkStream、Flink。Jstorm由于没有中间计算状态的,其计算过程中需要的中间结果必然依赖于外部存储,这样会导致频繁的io影响其性能;SparkStream本质上是用微小的批处理来模拟实时计算,实际上还是有一定延时;Flink由于其出色的状态管理机制保证其计算的性能以及实时性,同时提供了完备SQL表达,使得流计算更容易。
## 计算与持久化
数据经过预处理后最终生成调用链路聚合日志和主机监控数据,其中主机监控数据会独立存储在tsdb时序数据库中,供后续统计分析。tsdb由于其针对时间指标数据的特别存储结构设计,非常适合做时序数据的存储与查询。调用链路日志聚合数据,提供给cep/graph service做诊断模型分析。cep/graph service是闲鱼自研的一个应用,实现模型分析、复杂的数据处理以及外部服务进行交互,同时借助rdb实现图数据的实时聚合。
最后cep/graph service分析的结果作为一个图数据,实时转储在lindorm中提供在线查询。lindorm可以看作是增强版的hbase,在系统中充当持久化存储的角色。
4、设计细节与性能优化
5、收益
系统上线后,整个实时处理数据链路的延迟不超过三秒。闲鱼服务端问题的定位时间从十多分钟甚至更长时间下降到五秒内。大大的提升了问题定位的效率。
6、未来展望
目前的系统可以支持闲鱼每秒千万的数据处理能力。后续自动定位问题的服务可能会推广到阿里内部更多的业务场景,随之而来的是数据量的成倍增加,因此对于效率和成本提出了更好的要求。
未来我们可能做的改进:
1、能够自动的减少或者压缩处理的数据。
2、复杂的模型分析计算也可以在blink中完成,减少io,提升性能。
3、支持多租户的数据隔离。
`
如何基于Flink+TensorFlow打造实时智能异常检测平台?只看这一篇就够了
https://mp.weixin.qq.com/s/q2rgEm-tGxOlUUFfb80pEg
关键字:
flink 实时 平台
腾讯基于Flink的实时流计算平台演进之路
https://mp.weixin.qq.com/s/zIp_14_hgRRa0sKCW4Vejw
https://mp.weixin.qq.com/s/CYLrUxYojxpYFlUXhqEesg
滴滴实时计算发展之路及平台架构实践
https://mp.weixin.qq.com/s/NGeukit_TpwD4_opIZRb-Q
Flink 实战 | 贝壳找房基于Flink的实时平台建设
https://mp.weixin.qq.com/s/E25plFiKZl_zyCMiGv-ZDg
美团点评基于 Flink 的实时数仓建设实践
https://mp.weixin.qq.com/s/PJmdXkdUE5gtzcYAgAM8wQ
OPPO数据中台之基石:基于Flink SQL构建实数据仓库
https://mp.weixin.qq.com/s/JsoMgIW6bKEFDGvq_KI6hg
Flink 在趣头条的应用与实践
https://mp.weixin.qq.com/s/5jbRXxdXtogTJ3zUdm0TNg
海量数据实时分析服务技术架构演进
https://mp.weixin.qq.com/s/D6x30fNH3UVXbPLm7aGO1w
如何基于Flink+TensorFlow打造实时智能异常检测平台?只看这一篇就够了
https://mp.weixin.qq.com/s/q2rgEm-tGxOlUUFfb80pEg
「回顾」基于Flink的严选实时数仓实践
https://mp.weixin.qq.com/s/6UFrWoGf2e6kVC5UAK1JIQ
用Flink取代Spark Streaming!知乎实时数仓架构演进
https://mp.weixin.qq.com/s/e8lsGyl8oVtfg6HhXyIe4A
基于Flink的超大规模在线实时反欺诈系统的建设与实践
https://mp.weixin.qq.com/s/5opaOA9Rqk-3Sb-9bBRPJQ
基于 Flink 构建用户实时基础行为工程
https://mp.weixin.qq.com/s/GuBnloowwMPPBGAD0EWAIw
如何利用Flink实现超大规模用户行为分析
https://mp.weixin.qq.com/s/_Sky98xI9M8AkXf17SHt6g
大数据技术漫谈 ——从Hadoop、Storm、Spark、HBase到Hive、Flink、Lindorm
https://juejin.cn/post/7002789591748968479
`
@2021-09-01
基于以上个人经历,我想简单讲讲最近五年间大数据领域技术栈的演进史,并对其中提到的部分关键技术做展开说明。
本文重点在于总括性的概述,部分论点来源于个人使用经历,并不是行业公认的结论,如有谬误欢迎指正。
一、前言
二、大数据技术划分
三、大数据技术历史演进
3.1 流式计算历史演进 — 目前主流的流式计算框架有Storm/Jstorm、Spark Streaming、Flink/Blink三种。
3.2 离线计算历史演进 — 离线计算领域主要有Hadoop MapReduce、Spark、Hive/ODPS等计算框架。
3.3 列式存储NOSQL数据库历史演进 — NOSQL的概念博大精深,有键值(Key-Value)数据库、面向文档(Document-Oriented)数据库、列存储(Wide Column Store/Column-Family)数据库、图(Graph-Oriented)数据库等,本章节主要讲述列存储数据库中最流行的HBase及其替代品Lindorm。
3.4 大数据开发语言历史演进
3.5 大数据学习建议
四、云原生多模数据库Lindorm介绍
4.1 Lindorm介绍
4.2 Lindorm与MySQL对比
4.3 Lindorm与HBase对比
4.4 Lindorm实战的一些坑
4.4.1 Lindorm 二级索引
4.4.2 Lindorm 超大分页
4.4.3 Lindorm region划分
4.5 Lindorm相关QA
4.6 Lindorm总结
五、流批一体——大数据计算引擎Fink介绍
5.1 Flink介绍
5.2 Blink介绍
5.3 Flink与Blink对比
5.4 Flink使用
5.4.1 创建数据源表
5.4.2 创建数据结果表
5.4.3 编写业务逻辑
5.4.4 性能调优
5.5 Flink优点
六 、大数据在字节跳动
6.1 数据平台
6.2 存储系统
七、结语
参考文献
==
在国外一些社区,有很多人将大数据的计算引擎分成了 4 代。
第一代计算引擎,无疑是Hadoop MapReduce。它将计算分为两个阶段,分别为 Map 和 Reduce。上层应用需要自己手写map任务和reduce任务。
第二代计算引擎,支持 DAG(有向无环图) 的框架: Tez ,主要还是批处理任务
第三代计算引擎,以 Spark 为代表,特点主要是 Job 内部的 DAG 支持(不跨越 Job),以及强调的实时计算。
第四代计算引擎,以Flink、Blink为代表,一统批流,支持DAG运算,并具备进一步的实时性。
自 Google Dataflow 模型被提出以来,流批一体就成为分布式计算引擎最为主流的发展趋势。流批一体意味着计算引擎同时具备流计算的低延迟和批计算的高吞吐高稳定性,提供统一编程接口开发两种场景的应用并保证它们的底层执行逻辑是一致的。对用户来说流批一体很大程度上减少了开发维护的成本,但同时这对计算引擎来说是一个很大的挑战。虽然 Spark 是最早提出流批一体理念的计算引擎之一,但由于其本质还是基于批(mini-batch)来实现流,在流计算语义和延迟上存在硬伤,难以满足复杂、大规模实时计算场景的极致需求。
Flink 遵循 Dataflow 模型的理念: 批处理是流处理的特例。不过出于批处理场景的执行效率、资源需求和复杂度各方面的考虑,在 Flink 设计之初流处理应用和批处理应用尽管底层都是流处理,但在编程 API 上是分开的。这允许 Flink 在执行层面仍沿用批处理的优化技术,并简化掉架构移除掉不需要的 watermark、checkpoint 等特性。
`