=Start=
缘由:
简单整理一下,方便以后参考。
正文:
参考解答:
一般数据处理的流程如下:
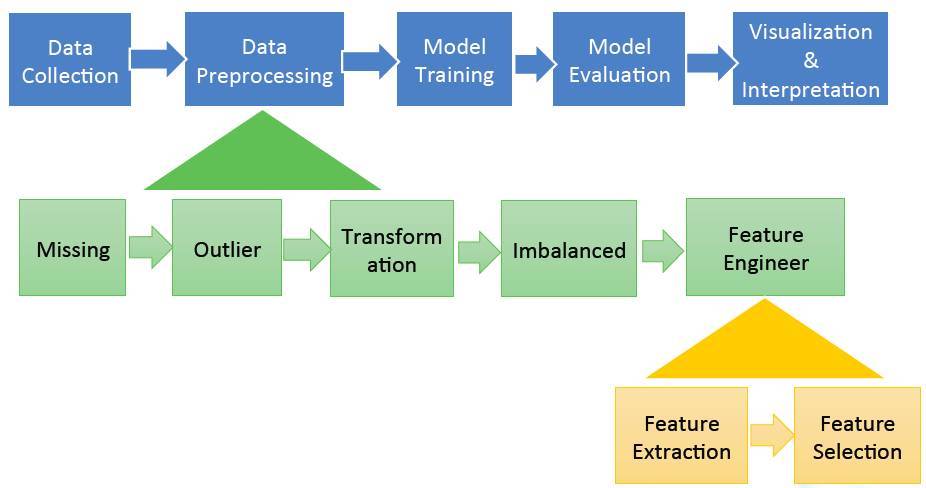
另外就是我自己从其它地方看到的一个大致的路线(不一定正确):
AI人工智能 -> ML机器学习 -> DL深度学习 -> NLP自然语言处理
ML机器学习
有监督学习
分类
- kNN
- 决策树
- 朴素贝叶斯
- SVM
- logistic回归
- AdaBoost
回归
- 线性回归
- 树回归
无监督学习
聚类
- kMeans
- EM
- DBSCAN
- Apriori
- FP-growth
密度估计
常用的降维方法
PCA
LDA
DL深度学习
- CNN-卷积神经网络
- RNN-递归神经网络
- LSTM-长期短期记忆网络
==
kNN算法
核心:将样本分到离它距离最近的样本所属的类。
决策树
核心:一组嵌套的判定规则。
贝叶斯分类器
核心:将样本判定为后验概率最大的类。
SVM-支持向量机
核心:最大化分类间隔的线性分类器(不考虑核函数)。
Logistic回归
核心:直接从样本估计出它属于正负样本的概率。
AdaBoost算法
核心:用多个分类器的线性组合来预测,训练时重点关注错分的样本,准确率高的弱分类器权重大。
人工神经网络
核心:一个多层的复合函数。
CNN卷积神经网络
核心:一个共享权重的多层复合函数。
卷积神经网络在本质上也是一个多层复合函数,但和普通神经网络不同的是它的某些权重参数是共享的,另外一个特点是它使用了池化层。训练时依然采用了反向传播算法,求解的问题不是凸优化问题。和全连接神经网络一样,卷积神经网络是一个判别模型,它既可以用于分类问题,也可以用用于回归问题,并且支持多分类问题。
RNN循环神经网络
核心:综合了复合函数和递推数列的一个函数。和普通神经网络最大的不同在于,循环神经网络是一个递推的数列,因此具有了记忆功能。
kMeans算法
核心:把样本分配到离它最近的类中心所属的类,类中心由属于这个类的所有样本确定。
PCA
核心:向重构误差最小(方差最大)的方向做线性投影。
LDA
核心:向最大化类间差异、最小化类内差异的方向线性投影。
参考链接:
- 一句话总结常用的机器学习算法
https://mp.weixin.qq.com/s/uSYdmntspvnLsckSJ1Hjow - 这是一篇关于如何成为一名AI算法工程师的长文
https://mp.weixin.qq.com/s/kreVG3PA1wO2xXwX5MCF5A - 学习机器学习有哪些好工具推荐?
https://github.com/apachecn/AiLearning - 机器学习该怎么入门?
https://www.zhihu.com/question/20691338/answer/446610161 - 惊为天人,NumPy手写全部主流机器学习模型,代码超3万行
=END=
《 “常用的机器学习算法小结” 》 有 24 条评论
关于学习机器学习算法的一些建议(忠告)
https://zhuanlan.zhihu.com/p/69104881
`
* 不要将大把时间浪费在一次性搞懂理论理解上
* 不要尝试停下来理解所有的知识点
* 不要浪费时间:请学习快速学习知识点,一天学4-5个
* 请跑代码,“真的”去跑代码。不要去深入学习理论。去玩转代码,看看它们“吃进什么吐出什么”
* 选择一个项目,认真做好,做到超棒!
* **如果卡壳了,不要停下来深挖,继续前行!
如果你不确定哪个学习效果更好,每个都试试看。
多数公司浪费大量时间在收集更多数据上。正确做法是,用一小撮数据跑跑看,然后在看问题是否是数据不够。
如果你认为自己“天生不擅长数学”, 请看看Rachel的TED演讲: There’s no such thing as “not a math person” 8. My own input: only 6 minutes, everyone should watch it!
可能最重要的是和小伙伴们一起学,这样效果往往更好。组建一个读书会,学习小组,定期聚会,动手做些项目。不需要是什么特别棒的东西,只要是能让世界更美好一点,甚至是让你的2岁大孩子开心的事情。完成一件事情,然后在进一步完善它。
学习深度学习, 最重要的就是代码,不停写代码,看看你的输入值,输出值,尝试输出一个你的mini-batch。
`
面试官如何判断面试者的机器学习水平?
https://www.zhihu.com/question/62482926
`
自己拿过Hulu,阿里,腾讯,美团的算法工程师offer,也作为面试官面试过100+候选人,简单谈一下机器学习工程师的面试,说白了就一句话,
把你做过的机器学习项目的细节讲清楚,有自己的理解,对经典的以及前沿的机器学习知识有所了解。
机器学习面试要考察三方面的内容,1、理论基础,2、工程能力,3、业务理解。之前有的答主罗列了几乎所有知识点,面试者能够逐一准备当然是好的,但我不相信有任何人能够对所有问题有深入的理解。也正因为这一点,面试官一般不会大面积的深入考察所有知识点,面试时间也不允许,但资深一点的面试官只要从简历出发问你一个项目,这三方面的能力也就都考察到了。毕竟魔鬼躲在细节里嘛。
我记得我的一位面试同学介绍自己实习时候用过XGBoost预测股票涨跌,那面试官会由浅入深依次考察:
* GBDT的原理 (理论基础)
* 决策树节点分裂时如何选择特征,写出Gini index和Information Gain的公式并举例说明(理论基础)
* 分类树和回归树的区别是什么?(理论基础)
* 与Random Forest作比较,并以此介绍什么是模型的Bias和Variance(理论基础)
* XGBoost的参数调优有哪些经验(工程能力)
* XGBoost的正则化是如何实现的(工程能力)
* XGBoost的并行化部分是如何实现的(工程能力)
* 为什么预测股票涨跌一般都会出现严重的过拟合现象(业务理解)
* 如果选用一种其他的模型替代XGBoost,你会选用什么?(业务理解和知识面)
除了上面的问题,我会再检查一下面试者对NN,RNN,个别聚类算法,模型评估等知识的理解程度以及对GAN,LSTM,online learning是否有基本理解,这是考察面试者对经典以及前沿的机器学习知识的了解程度。再稍微检查一下面试者对工具的了解程度,写一段简单的spark或者map reduce的程序,如果无误的话,那么可以说这位面试者的机器学习部分是完全合格的。
当然,如果你介绍的项目是用CNN实现的,这条考察线路当然是不一样的,大概会是
LR推导->梯度消失->激活函数->TensorFlow调参经验这条路,大家体会意思就好。除此之外,还有其他工程方向的面试官会着重考察coding和一些算法题目,那是另外一个话题了。
根据我去年的面试经验,即使清华北大的同学也往往无法回答完整这些提问。一项答不出来的话无伤大雅,但两项答不出来我基本会给fail或maybe。
所以真的希望大家严肃对待写在简历上的东西,面试官会刨根问题的问到骨子里。但就我个人而言我不会深究面试者简历之外的东西,比如故意问一问GAN的细节让你一定要答出来,我认为这样毫无意义,有故意刁难之嫌。
`
这是一篇关于如何成为一名AI算法工程师的长文
https://mp.weixin.qq.com/s/kreVG3PA1wO2xXwX5MCF5A
`
# BAT常见的面试题(不分先后)
自我介绍/项目介绍
类别不均衡如何处理
数据标准化有哪些方法/正则化如何实现/onehot原理
为什么XGB比GBDT好
数据清洗的方法有哪些/数据清洗步骤
缺失值填充方式有哪些
变量筛选有哪些方法
信息增益的计算公式
样本量很少情况下如何建模
交叉检验的实现
决策树如何剪枝
WOE/IV值计算公式
分箱有哪些方法/分箱原理是什么
手推SVM:目标函数,计算逻辑,公式都写出来,平面与非平面
核函数有哪些
XGB原理介绍/参数介绍/决策树原理介绍/决策树的优点
Linux/C/Java熟悉程度
过拟合如何解决
平时通过什么渠道学习机器学习(好问题值得好好准备)
决策树先剪枝还是后剪枝好
损失函数有哪些
偏向做数据挖掘还是算法研究(好问题)
bagging与boosting的区别
模型评估指标有哪些
解释模型复杂度/模型复杂度与什么有关
说出一个聚类算法
ROC计算逻辑
如何判断一个模型中的变量太多
决策树与其他模型的损失函数、复杂度的比较
决策树能否有非数值型变量
决策树与神经网络的区别与优缺点对比
数据结构有哪些
model ensembling的方法有哪些
# 小结
问题是散的,知识是有关联的,学习的时候要从大框架学到小细节。
没事多逛逛招聘网站看看招聘需求,了解市场的需求到底是什么样的。时代变化很快,捕捉信息的能力要锻炼出来。你可以关注的点有:职业名/职业方向/需要会什么编程语言/需要会什么算法/薪资/…
每个面试的结尾,面试官会问你有没有什么想问的,请注意这个问题也很关键。
比如:这个小组目前在做什么项目/实现项目主要用什么语言和算法/…
尽量不要问加不加班,有没有加班费之类的,别问我为什么这么说(摊手)
# 一碗鸡汤
一切才刚刚开始,别着急
找一件可以坚持的事,不要停止去寻找的脚步
`
学机器学习有必要懂数学吗?深入浅出机器学习与数学的关系
https://mp.weixin.qq.com/s/8zPh0tVVvnEbSDzNsxDcTw
`
随着AI资源越来越丰富,网上po出了越来越多的机器学习路线,机器学习攻略,这些路线攻略五花八门,却都有一个共同点,最基础的是数学和编程语言。编程语言作为基础,很好理解,机器学习是靠程序来完成的嘛,当然要学会编程语言啦~但是,为什么要学数学呢?还不是一门数学,最起码的也要包括微积分、线性代数、概率论、统计学,更不用说什么凸优化、数值计算、运筹学等等,在高中时期被数学折磨的阴影还留存着,不禁想要大声问一句:在机器学习中,这些数学都是做什么的啊?为什么一定要学这些数学呢?
首先我们要知道,机器学习理论是一个涵盖统计、概率、计算机科学和算法方面的领域,该理论的初衷是以迭代方式从数据中学习,找到可用于构建智能应用程序的隐藏洞察。尽管机器学习和深度学习有巨大的发展潜力,但要深入掌握算法的内部工作原理并获得良好的结果,就必须透彻地了解许多技术的数学原理。搞清楚这些数学原理,可以帮助我们:选择正确的算法、选择参数设置和验证策略、通过理解偏差-方差权衡,识别欠拟合和过拟合、估算正确的置信区间和不确定性。
线性代数
微积分
概率论
统计学
统计学是核心,微积分告诉我们怎样学习和优化模型,线性代数使得算法能在超大型数据集上运行,概率论帮我们预测某个事件发生的可能性。
`
从机器学习谈起
https://www.cnblogs.com/subconscious/p/4107357.html
神经网络浅讲:从神经元到深度学习
https://www.cnblogs.com/subconscious/p/5058741.html
Neural Networks, Manifolds, and Topology
http://colah.github.io/posts/2014-03-NN-Manifolds-Topology/
如何简单形象又有趣地讲解神经网络是什么?
https://www.zhihu.com/question/22553761
如何简单形象又有趣地讲解神经网络是什么? – YJango的回答 – 知乎
https://www.zhihu.com/question/22553761/answer/126474394
神经网络入门
http://www.ruanyifeng.com/blog/2017/07/neural-network.html
一文了解人工智能——学科介绍、发展史、三大学派
https://mp.weixin.qq.com/s?__biz=MjM5MzA1Mzc3Nw==&mid=2247485106&idx=1&sn=eb2aa7dd252565ee10bd5f254a205146
`
在介绍人工智能之前,我们要先了解智能到底是什么?智能,其实就是智力和能力的总称。世界著名教育心理学家霍华德·加德纳提出了著名的“多元智能理论”,他认为人类个体都独立存在着八种智能,分别如下:
-> 视觉—空间智能,指对线条、形状、结构、色彩和空间关系的敏感以及通过平面图形和立体造型将它们表现出来的能力。
-> 语言—言语智能,指听说读写能力,利用语言描述事件、表达思想并与人交流的能力。
-> 交往—交流智能 ,指与人相处交往的能力,表现为察觉、体验他人情绪、情感和意图并据此作出适宜反应的能力。
-> 自知—自省智能,指认识、洞察和反省自身的能力,表现为正确地意识和评价自身的情绪、动机、欲望、个性、意志,并在正确的自我意识我自我评价的基础上形成自尊、自律和自制的能力。
-> 逻辑—数理智能 ,指运算和推理能力,表现为对事物间各种关系如类比、对比、因果和逻辑等关系的敏感以及通过数理运算和逻辑推理等进行思维的能力。
-> 音乐—节奏智能,指感受、辨别、记忆、改变和表达音乐的能力,表现为个人对音乐包括节奏、音调、音色和旋律的敏感以及通过作曲、演奏和歌唱等表达音乐的能力。
-> 身体—动觉智能,指运用四肢和躯干的能力,表现为能够较好地控制自己的身体、对事件能够做出恰当的身体反应以及善于利用身体语言来表达自己的思想和情感的能力。
-> 自然观察智能,指个体辨别环境的特征并加以分类和利用的能力。
何为智能?
何为人工智能?
弱人工智能?
人工智能发展史
三大学派
-> 符号主义学派
-> 连接主义学派
-> 行为主义学派
这篇文章从整体介绍了什么是人工智能、人工智能的发展以及人工智能的三大学派,从整体上了解了人工智能这门学科的情况,并且知道了目前的人工智能并非是科幻片里面的人工智能,现实与理想之间的差距还是很大的。
`
机器学习一般常用的算法有哪些?哪个平台学习机器算法比较好呢?
https://www.zhihu.com/question/54121522/answer/689000680
`
摘要: 本文为机器学习新手介绍了十种必备算法:线性回归、逻辑回归、线性判别分析、分类和回归树、朴素贝叶斯、K-近邻算法、学习向量量化、支持向量机、Bagging和随机森林、Boosting和AdaBoost。
在机器学习中有一种“无免费午餐(NFL)”的定理。简而言之,它指出没有任何一个算法可以适用于每个问题,尤其是与监督学习相关的。
因此,你应该尝试多种不同的算法来解决问题,同时还要使用“测试集”对不同算法进行评估,并选出最优者。
然而,这些都有一个共同的原则,那就是所有监督机器学习算法都是预测建模的基础。
机器学习算法包括目标函数(f),输入映射变量(X),生成输出变量(y):Y=f(X)。这是一个通用的学习任务,希望在给出新案例的输入变量(X)能预测出(Y)。
最常见的机器学习方式是Y= f(X)的映射来预测新的X,这被称为预测建模或预测分析。
`
机器学习新手必学十大算法指南
https://yq.aliyun.com/articles/406011
https://pan.baidu.com/s/1pNtAbvd
A TOUR OF THE TOP 10 ALGORITHMS FOR MACHINE LEARNING NEWBIES
https://builtin.com/data-science/tour-top-10-algorithms-machine-learning-newbies
`
1 — Linear Regression.
2 — Logistic Regression.
3 — Linear Discriminant Analysis.
4 — Classification and Regression Trees.
5 — Naive Bayes.
6 — K-Nearest Neighbors.
7 — Learning Vector Quantization.
8 — Support Vector Machines.
9 — Bagging AND Random Forest
10 — Boosting AND AdaBoost
`
https://www.datacamp.com/community/news/a-tour-of-the-top-10-algorithms-for-machine-learning-newbies-dbf6geuypk6
自然语言处理能做什么
https://mp.weixin.qq.com/s?__biz=MzU2NDg4ODcwOA==&mid=2247483816&idx=1&sn=20f46760486b1cd75c9e6157d913e865
推荐一个网站:
https://nlpprogress.com/
https://github.com/sebastianruder/NLP-progress
该网站收录了几乎所有的 NLP 研究分支,并且跟踪 NLP 在这些任务上的进展(SOTA,state-of-the-art)。网站更新比较及时,至少,当前我们能在部分榜单上看到 XLNET。(北京时间:20190724)
什么是知识图谱?
https://mp.weixin.qq.com/s?__biz=MzU2NDg4ODcwOA==&mid=2247483790&idx=1&sn=b35493d793c597e83552bceb8b1981d4
知乎文章《为什么需要知识图谱?什么是知识图谱?——KG的前世今生》是一个很好的入门文章,感兴趣可以进一步阅读:
https://zhuanlan.zhihu.com/p/31726910
《知识图谱的技术与应用(18版)》是一个更为全面和详细的介绍:
https://zhuanlan.zhihu.com/p/38056557
机器学习中非常有名的理论或定理你知道几个?
https://mp.weixin.qq.com/s/e0VIymlr9_7d_d9vgwc5Bg
`
# PAC学习理论
当使用机器学习算法来解决某个问题时,通常靠经验或者多次实验来得到合适的模型,训练样本数量和相关的参数。但是经验判断成本较高,且不太可靠,因此希望有一套理论能够分析问题,计算模型能力,为算法提供理论保证。这就是计算学习理论(Computational Learning Theory),其中最基础的就是近似正确学习理论(Probably Approximately Correct, PAC)。
# 没有免费午餐定理
没有免费午餐定理(No Free Lunch Theorem,NFL)是由Wolpert和Macerday在最优化理论中提出的,NFL证明:对于基于迭代的最优化算法不会存在某种算法对所有问题(有限的搜索空间内)都有效。如果一个算法对某些问题有效,那么他一定在另一些问题上比纯随机搜索算法更差。也就是说,不能脱离具体问题来讨论算法的优劣,任何算法都有优劣性,必须要“具体问题具体分析”。
# 丑小鸭定理
丑小鸭定理(Ugly Duckling Theorem)是1969年由渡边慧提出的[Watan-able, 1969]。“丑小鸭与白天鹅之间的区别和两只白天鹅之间的区别一样大”。这个定理初看好像不符合常识,但是仔细思考后是非常有道理的。因为世界上不存在相似性的客观标准,一切相似性的标准都是主观的。如果以体型大小的角度来看,丑小鸭和白天鹅的区别大于两只白天鹅的区别;但是如果以基因的角度来看,丑小鸭与它父母的差别要小于他父母和其他白天鹅之间的差别。
# 奥卡姆剃刀
奥卡姆剃刀(Occam’s Razor)是由14世界逻辑学家William of Occam提出的一个解决问题的法则:“如无必要,勿增实体”。
奥卡姆剃刀的思想和机器学习上正则化思想十分相似:简单的模型泛化能力更好。如果有两个性能相近的模型,我们更倾向于选择简单的模型。因此在机器学习准则上,我们经常会引入参数正则化(比如L2正则)来限制模型能力,避免过拟合。
# 归纳偏置
在机器学习中,很多算法会对学习的问题做一些假设,这些假设就称为归纳偏置(Inductive Bias)。比如在最近邻分类器中,我们会假设在特征空间内,一个小的局部区域中的大部分样本都属于同一类。在朴素贝叶斯分类器中,我们会假设每个特征的条件概率是相互独立的。
归纳偏置在贝叶斯学习中也成为先验(priors)。
# 中心极限定理
中心极限定理是研究独立随机变量和的极限分布为正态分布的命题。经过科学家长期的观察和总结,发现服从正态分布的随机现象往往是由独立(或弱相依)的随机变量产生的。
`
Java自然语言处理NLP工具包
https://www.cnblogs.com/liinux/p/6309461.html
http://opennlp.apache.org/docs/1.9.1/manual/opennlp.html
http://alias-i.com/lingpipe/web/demos.html
7 TOP NLP LIBRARIES JAVA DEVELOPERS SHOULD KNOW IN 2019
https://analyticsindiamag.com/7-top-nlp-libraries-java-developers-should-know-in-2019/
`
1| Apache OpenNLP
2| Apache UIMA
3| GATE Embedded
4| LingPipe
5| MALLET
6| NLP4J
7| Stanford CoreNLP
`
Java or Python for Natural Language Processing [closed]
https://stackoverflow.com/questions/22904025/java-or-python-for-natural-language-processing
python:
TextBlob: http://textblob.readthedocs.org/en/dev/
Gensim: http://radimrehurek.com/gensim/
Pattern: http://www.clips.ua.ac.be/pattern
Spacy:: http://spacy.io
Orange: http://orange.biolab.si/features/
Pineapple: https://github.com/proycon/pynlpl
Java:
Freeling: http://nlp.lsi.upc.edu/freeling/
OpenNLP: http://opennlp.apache.org/
LingPipe: http://alias-i.com/lingpipe/
Stanford CoreNLP: http://stanfordnlp.github.io/CoreNLP/ (comes with wrappers for other languages, python included)
CogComp NLP: https://github.com/CogComp/cogcomp-nlp
适合初学者学习的NLP开源项目有哪些?
https://www.zhihu.com/question/264352009
`
那必须推荐一波kaggle上的competition了,理由主要是真实数据、丰富的讨论,较多的开源实现及kernel。先搬运一波,感兴趣的童鞋多的话再搬运一些说明、solution、github链接之类的。但是如果是为了练手,建议自己先做,再看别人的实现和讨论,循序渐进才能起到练习的效果。
`
https://www.kaggle.com/c/word2vec-nlp-tutorial
https://www.kaggle.com/c/sentiment-analysis-on-movie-reviews
https://www.kaggle.com/c/text-normalization-challenge-english-language
NLP上手教程
https://github.com/FudanNLP/nlp-beginner
A curated list of beginner resources in Natural Language Processing
https://github.com/gutfeeling/beginner_nlp
How to get started in NLP
https://towardsdatascience.com/how-to-get-started-in-nlp-6a62aa4eaeff
A Beginner’s Guide to Natural Language Processing (NLP)
https://skymind.ai/wiki/natural-language-processing-nlp
分析了自家150个ML模型之后,这家全球最大的旅行网站得出了6条经验教训
https://mp.weixin.qq.com/s/ylwfnKcUSJdDDxWFhfMYjg
`
在许多媒体文章中,我们都能看到「机器学习赋能 XX 行业」的字眼,但这种「能量」究竟体现在哪些方面,企业在引入机器学习模型的过程中要注意哪些问题,很多文章都没有说清楚。在今年的 KDD 大会接收论文中,全球最大的线上旅行代理网站 Booking.com(缤客网)贡献了一篇论文,分析了他们面向客户的 150 个成功的机器学习应用以及从中得到的六条经验教训。本文是对这篇论文的简短总结。
「150 successful Machine Learning models: 6 lessons learned at Booking.com」是一篇绝佳的综述,它结合了 Booking.com 大约 150 个面向客户的成功的机器成功应用以及从中得到的经验教训。奇怪的是,虽然论文的标题这么写了,在正文中却从未明确列出这 6 条经验教训。不过,我们可以从论文的划分中推断出这些部分,以下是我的解读:
* 使用机器学习模型的项目会创造巨大的商业价值
* 模型的性能不等同于经营业绩
* 弄清你正在尝试解决的问题
* 预测的延迟是个重要问题
* 及早获取模型质量的反馈
* 用随机对照试验测试你的模型的商业影响力
我们发现,发挥真实的商业影响力极为困难,更何况,将在建模方面所做的努力和观测到的影响力之间的联系分离开来好好理解原本就是一件难事。我们主要的结论是:要用机器学习打造出这 150 个成功的产品,其根本在于,要有一个迭代的、由假设驱动的流程,并结合其他学科。
`
150 Successful Machine Learning Models: 6 Lessons Learned at Booking.com
https://booking.ai/150-successful-machine-learning-models-6-lessons-learned-at-booking-com-681e09107bec?gi=68d2db9fc1e4
https://www.kdd.org/kdd2019/accepted-papers/view/150-successful-machine-learning-models-6-lessons-learned-at-booking.com
https://dl.acm.org/doi/abs/10.1145/3292500.3330744?download=true
https://blog.acolyer.org/2019/10/07/150-successful-machine-learning-models/
深度学习面试的12个基础问题,强烈推荐!
https://mp.weixin.qq.com/s/_jyIhPPBg82f5U6fp1vEig
`
问题1:阐述批归一化的意义
问题2:阐述偏置和方差的概念以及它们之间的权衡关系
问题3:假设深度学习模型已经找到了 1000 万个人脸向量,如何通过查询以最快速度找到一张新人脸?
问题4:对于分类问题,准确度指数完全可靠吗?你通常使用哪些指标来评估你的模型?
问题5:你怎么理解反向传播?请解释动作(action)的机制。
问题6:激活函数有什么含义?激活函数的饱和点是什么?
问题7:模型的超参数是什么?超参数与参数有何不同?
问题8:当学习率过高或过低时会怎样?
问题9:当输入图像的尺寸加倍时,CNN 参数的数量会增加多少倍?为什么?
问题10:处理数据不平衡问题的方法有哪些?
问题11:在训练深度学习模型时,epoch、batch(批)和 iteration(迭代)这些概念都是什么意思?
问题12:数据生成器的概念是什么?使用数据生成器需要什么?
`
https://medium.com/@itchishikicomm/12-deep-learning-interview-questions-you-should-not-be-missed-part-1-8a61f44cadac
我对安全与NLP的实践和思考
https://mp.weixin.qq.com/s/_q5s1fHc0DB3feSd4gQZyw
`
1. 能出框架的尽量造一个框架来满足各种需求,满足一类问题,而不是单个问题;
2. 上层应用能力能搞好当然很不错,但底层能力才能让你不断发展技术深度,避免落伍;
3. 持续思考,不断提升。对一件事物的认识,在不同阶段应该是不一样的,甚至可能完全推翻自己之前的认识。我们能做的,是保持思考,重新认识过去的经历,提升对事物的认知和认知能力。这个提升认知的过程,类似boosting的残差逼近和强化学习的奖惩,是一个基于不知道不知道->知道不知道>知道知道->不知道知道的螺旋式迭代上升过程。
`
一位中国博士把整个CNN都给可视化了,可交互有细节,每次卷积ReLU池化都清清楚楚
https://mp.weixin.qq.com/s/IxekW5Qefn-mDrQ27rUuiA
`
每一个对AI抱有憧憬的小白,在开始的时候都会遇到CNN(卷积神经网络)这个词。
但每次,当小白们想了解CNN到底是怎么回事,为什么就能聪明的识别人脸、听辨声音的时候,就懵了,只好理解为玄学。
好吧,维基百科解决不了的问题,有人给解决了。
这个名叫CNN解释器在线交互可视化工具,把CNN拆开了揉碎了,告诉小白们CNN究竟是怎么一回事,为什么可以辨识物品。
它用TensorFlow.js加载了一个10层的预训练模型,相当于在你的浏览器上跑一个CNN模型,只需要打开电脑,就能了解CNN究竟是怎么回事。
而且,这个网页工具还可以实现交互,只要点击其中任何一个格子——就是CNN中的“神经元”,就能显示它的输入是哪些、经过了怎样细微的变化。
甚至,连每一次卷积运算都能看得清。
`
CNN解释器
https://poloclub.github.io/cnn-explainer/
GitHub
https://github.com/poloclub/cnn-explainer
论文
https://arxiv.org/abs/2004.15004
ChatGPT: Optimizing Language Models for Dialogue
https://openai.com/blog/chatgpt/
ChatGPT
https://en.wikipedia.org/wiki/ChatGPT
Lightweight package for interacting with ChatGPT’s API by OpenAI. Uses reverse engineered official API.
https://github.com/acheong08/ChatGPT
ChatGPT ,能替代程序员吗?
https://www.v2ex.com/t/901052
ChatGPT在信息安全领域的应用前景
https://mp.weixin.qq.com/s/-T8IKaqlX89_U9NJzX6UCg
`
二. ChatGPT在安全行业的应用
2.1 安全工具开发
2.2 逆向分析
2.3 安全检查和漏洞挖掘
2.4 安全告警评估
三. 后记和展望
除了上面提到的几种应用之外,目前我们也正在尝试将ChatGPT用于二进制漏洞挖掘、渗透测试用例生成、项目交付报告编写等诸多细分领域。
风云变幻莫能测,且看今朝谁英雄。这份来自NLP学科的大礼包,也许能够给安全行业的发展带来一股新风。
`
ChatGPT 还不是最可怕的
https://www.v2ex.com/t/899927
`
# question
ChatGPT 有多牛逼,大家应该知道了。
GPT3 模型有 1750 亿个参数,ChatGPT 是基于 GPT3.5 。
但是即将发布的 GPT4 模型有 100 万亿个参数。
所有文本类(包括编程)工作,都降产生巨大的变革。。。而且这一切都会发生在 3 年内
# answer(s)
我一直有个想法:每个人从会说话开始就用一个 AI 收集他的信息,这样收集一辈子之后,后续和这个 AI 聊天可能就与本人差别不大了。另外,一些特别受欢迎的人,还可以卖自己的 AI ,让倾慕者有与他随时相伴的感觉。
==
ChatGPT 是 ChatGPT ,人类是人类。
ChatGPT 可以做到许多人类做不到的事,但人类一些最基础的功能 ChatGPT 也做不到,例如物体识别。
人类从出生到可以物体识别大概只需要几年时间,在这期间耗费的能量也就些食物的热量。训练个 ChatGPT 不知又许多多少块 GPU ,又耗费多少电能呢。
==
open ai 是不是在撞大运,每次搞个 demo 让别人挖掘用途,我不信他只是为了探索技术的极限或者提供公关价值。
==
作为 NLP 从业者,首先我对 GPT 系持怀疑态度,我就基于我的经验,发表一下个人愚见。
先不说文本生成这种难度较高的任务,就连文本分类这种最最基础的任务,在很多场景下达到 95% 以上的准确率仍然是很困难的( Bert 系),他就是学不会。楼上有人说模型参数量很大,有人说模型不是单纯记训练集,可是现实是,模型很可能就是在背书,参数量越大背得越好。
不知道大家有没有想过,GPT 这种 LLM ( Large Language Model )的训练集是非常之巨大的,那么在评测模型的时候,也就是在测试集中是不是有可能出现训练集中的数据或者类似数据?这个现象叫 benchmark data contamination 。GPT 的作者也发现了这个现象,但是他已经来不及重新训练了(费用太高)。
我个人认为,现阶段模型的作用已经相对较小了,最重要的是数据,也就是 Andrew Ng 所说的 data-centric AI ,正所谓 GIGO ( Garbage In Garbage Out ),构建一个成熟稳定强大的人工智能系统,现在重点和难点已经变成如何获取干净、有效、足够的数据。模型已经基本定型,小修小改影响不了多少。
关于背书和数据的重要性,还可以参见 GitHub Copilot ,是不是很多是直接拿的现有代码(训练集)?
希望模型在背背背之后,某一天可以突然真正理解其中奥义,那时候才是真正变成了自己的知识,就像我们小时候死记硬背古诗,长大后某天突然理解了真正含义。那要造成这个突变,是数据扮演了更重要的角色还是模型?以后还难说。
个人愚见。
==
1.目前地球上,在座的所有 AI ,包括 OpenAI 的 Chat ,都不是真正能进行自主分析的 AI ,充其量只是对大数据进行信息挖掘与拟合罢了。
2.你们的问题太简单,能在互联网上直接找到答案,所以 ChatAI 才能给出答案。
而我的问题,需要自己进行分析,并创造一个互联网上不存在的新回答,所以 ChatAI 也搞不定。
==
也不是完全没有意义,可以让大部分之前没有机会通过外包或是其它方式获取其他方向/专业资源的人,能通过类似 chatGPT 这样的工具便捷获取(也存在被服务提供者进行内容阉割的情况),获取到的结果可能比搜索引擎拿到的好也可能更差,说不清楚,但最终看来,还是依赖于使用的人。这种情况下,最好还是通过提升自身来解决,但类似 chatGPT 这种工具可以提高效率和扩展思路,加速自我提升的过程。
`
奇点临近:Copilot 与 ChatGPT
https://oldj.net/article/2022/12/09/the-singularity-is-approaching/
`
今年,有两个科技产品让我很受震撼,分别是辅助编程的的 Copilot 以及在线聊天的 ChatGPT,巧的是这两个产品都和 AI(人工智能)有关,且背后其实是一家公司提供的技术。
刚成为程序员的那几年,我曾经一度信奉工具极简化的理念,日常只使用 Vim 编程,几乎不用任何代码排版或自动完成工具,尽可能将写代码所需的一切都记在脑子里。
之所以这样做,一方面固然是相信这样对提升编程水平有帮助,另一方面也是因为那时的工作环境经常变化,有时在公司台式机上写代码,有时在家里自己的电脑上写代码,有时还要远程连到服务器上去编辑文件,保持工具的简单能保证换了环境后仍然能快速开始工作。
几年之后,我去了一个业内知名的团队,意外地发现那儿大部分人日常都使用功能强大的 IDE 来写代码,相互间还经常分享一些 IDE 的使用心得。抱着试试看的心态,我也安装了他们推荐的 IDE,并将工作环境从 Vim 切换到 IDE。
很快我就发现了新的世界:现代 IDE 的功能比 Vim 等上古工具强大太多了,很多原本我要费很大工夫才能完成的工作,在 IDE 里只需要点一个菜单项就能搞定,一些低级错误 IDE 中也能直接提示,减少了无意中出错的概率,同时,在处理复杂或大型项目时,IDE 明显要更方便,因为它能大大减轻用户的心智负担,让用户能将注意力集中到当前工作中,同时在需要时又能快速跳转到需要的地方。
没过多久,我就彻底转向了 IDE。
有人说,这些功能在 Vim 中也能做到,只要进行一些配置,或者安装一些插件。可是,一个配置很复杂并且安装了很多插件的 Vim,和 IDE 在本质上有什么不同呢?如果想用各种方法把 Vim 打造成 IDE,为什么不直接使用更现代化的 IDE 呢?
从此之后,我开始特别留意各种能提升效率的工具。古人说:“君子生非异也,善假于物也。”就是鼓励大家要善于利用外物(工具),这样才能做到从前做不到的事。
GitHub 刚推出 Copilot 的时候,我曾不以为然,因为在这之前,我也用过几个号称使用 AI 来自动完善代码的工具,还为一些付过费,和 IDE 自身的代码提示相比,它们的确要好那么一些,但却没有好得足够多,反而有时还会带来新的麻烦。
原以为 Copilot 也类似,或者只是再进步了一点点,但试用之后却让我眼前一亮,它的补全能力太强了,很多时候我只需要写一半代码,它会负责补全另一半,甚至有些时候我才写了一个函数名,它就能把函数的内容补全。
于是,Copilot 也成了我日常编程中一个重要的工具。现在我已经习惯了 Copilot 的辅助,写代码的时候,经常会不自觉地停一下,等待 Copilot 显示自动补全。和多年前从 Vim 转向 IDE 类似,Copilot 可以说一定程度上改变了我的习惯,让我的编程效率有了明显的提升。
然后就是最近火出圈的 ChatGPT 了。
AI 聊天机器人不是什么新鲜的概念,很早之前就有过很多这类产品,比如微软的小冰等等。但如果你玩过 ChatGPT,你就会发现它与之前的产品不一样,虽然仍然有很多问题它不知道,但大多数问题它都能给你一个还算不错的回答。
最近几天我问了 ChatGPT 很多问题,有纯属娱乐的,也有关于编程或写作的,甚至还让它修改润色了一些短文,很多问题它都答得像模像样,至少可以用作参考或者启发的素材。
ChatGPT 并不完美,但用作 AI 助理,它已经足够令人激动了,如果进行商业化,一定有很多人愿意付费。
人们常说“量变引起质变”,看起来 ChatGPT 就处于正在发生质变的阶段,AI 近年的进展也表明现在的研究方向是可行的,也许几年之后,AI 就会给我们的世界带来巨大的改变。
`
君子性非异也,善假于物也。
+
注意力集中,专注于当下。
+
量变引起质变。