=Start=
缘由:
前段时间因为部分工作内容涉及到Linux系统的CPU、内存资源占用分析,所以简要回顾了一下之前整理的文章,内容其实没啥大问题,但太简单和基本,只是简单介绍了一下系统负载的概念以及查看方法,缺少了具体场景下的分析思路和方法,没有什么实际的指导意义,所以近期又通过搜索找到了一批不错的文章(主要是 CPU飙高,系统性能问题如何排查? 和 一文带你全面了解 Load Average (负载) 这两篇)进行学习,以期能够解答我的一些疑问,同时方便后面有需要的时候进一步参考。
我的问题:
- 多核Linux系统上CPU使用率和负载的关系?
- 机器告警CPU使用率过高或负载过高时,该如何快速定位大体原因以指导程序改进?
正文:
参考解答:
得到的相关解答:
1、同等压力下,不论核数多少,load average数值是一样的,但是cpu idle不一样,核数多的机器空闲率高,表示可以承载更多的计算任务。
2、单线程任务只会使用一个CPU,不管CPU核数有多少。
3、多核CPU,满负荷状态的数字为“1.00 * CPU核数”,即双核CPU为2.00,四核CPU为4.00。
4、SLEEP态(S/D)进程不会占用任何CPU资源。
5、Linux系统的load在Linux中体现的是系统整体负载(R+D),即CPU负载 + Disk负载 + 网络负载 + 其余外设负载,并不完全等同于CPU使用率(这种情况只出现在Linux中,其余系统比如Unix,Load还是只代表CPU负载),而且一般是会高于CPU使用率的,因为多包含了IO等待等进程。
6、Load Average、CPU、IO和系统是否卡顿之间的一般关系:
- CPU使用率高,IO无作业,Load Average低,系统反应颠簸(响应时慢时快)——这种场景,通常是计算密集型任务,即大量生成耗时短的计算任务。这种任务会占满CPU资源,造成系统响应速度颠簸,但由于每个任务能快速计算完成,不会在运行队列堆积,所以在Load Average里不会体现出来。
- CPU使用率高,IO繁忙/等待,Load Average高,系统卡——这种场景,通常是服务混部,即IO、计算密集型任务混部在一起,相当于CPU、IO都处于高负荷状态,那么Load Average 自然很高。
- CPU使用率低,IO等待,Load Average高,系统不卡——这种场景,通常是IO密集型任务,如果大量请求都集中于相同的IO设备,超出设备的响应能力,会造成任务在运行队列里堆积等待,也就是D状态的进程堆积,那么此时Load Average就会飙高。但由于任务都处于sleep等待状态,所以Load Average的值虽然很高,但系统响应速度不受影响。
- CPU使用率低,IO繁忙,Load Average低,系统卡——这种场景,通常是低频大文件读写,由于请求数量不大,所以任务都处于R状态,Load Average数值反映了当前运行的任务数,不会飙升,IO设备处于满负荷工作状态,导致系统响应能力降低。
1. 基础知识储备
Linux进程状态
Linux 2.6以后的内核中,进程一般存在7种基础状态:D-不可中断睡眠、R-可执行、S-可中断睡眠、T-暂停态、t-跟踪态、X-死亡态、Z-僵尸态,这几种状态在ps命令中有对应解释,下面是具体的解释和中文翻译:
$ man ps
...
PROCESS STATE CODES
Here are the different values that the s, stat and state output specifiers (header "STAT" or "S") will display to describe the state of a process:
D uninterruptible sleep (usually IO) TASK_UNINTERRUPTIBLE,不可中断睡眠态。一般由I/O等待(比如磁盘I/O、网络I/O、外设I/O等)引起,出现时间非常短暂,大多很难被PS或者TOP命令捕获(除非I/O HANG死)。SLEEP态进程不会占用任何CPU资源。
R running or runnable (on run queue) TASK_RUNNING,可执行态。这种状态的进程都位于CPU的可执行队列中,正在运行或者正在等待运行,即不是在上班就是在上班的路上。
S interruptible sleep (waiting for an event to complete) TASK_INTERRUPTIBLE,可中断睡眠态。不同于D,这种状态的进程虽然也处于睡眠中,但是是允许被中断的。这种进程一般在等待某事件的发生(比如socket连接、信号量等),而被挂起。一旦这些事件完成,进程将被唤醒转为R态。如果不在高负载时期,系统中大部分进程都处于S态。SLEEP态进程不会占用任何CPU资源。
T stopped by job control signal __TASK_STOPPED,暂停态。暂停态一般由于收到SIGSTOP、SIGTSTP、SIGTTIN、SIGTTOUT四种信号被停止。暂停态进程会释放所有占用资源。
t stopped by debugger during the tracing __TASK_TRACED,跟踪态。进程处于运行停止的状态。跟踪态是由于进程被另一个进程跟踪引起(比如gdb断点)。暂停态进程会释放所有占用资源。
X dead (should never be seen) EXIT_DEAD,死亡态。进程的真正结束态,这种状态一般在正常系统中捕获不到。
Z defunct ("zombie") process, terminated but not reaped by its parent EXIT_ZOMBIE,僵尸态。这种状态的进程实际上已经结束了,但是父进程还没有回收它的资源(比如进程的描述符、PID等)。僵尸态进程会释放除进程入口之外的所有资源。
...SLEEP态进程不会占用任何CPU资源。
Linux系统的load计算方法
以下为Linux内核源码中Load Average计算方法——除了可执行态进程,不可中断睡眠态进程也会被一起纳入计算,即:
LoadAverage = calc_load(TASK_RUNNING + TASK_UNINTERRUPTIBLE, n)在上面 Linux进程状态 中有提到过,不可中断睡眠态的进程(TASK_UNINTERRUPTIBLE)一般都在进行I/O等待,比如磁盘、网络或者其他外设等待。由此我们可以看出,Linux系统的load在Linux中体现的是系统整体负载,即CPU负载 + Disk负载 + 网络负载 + 其余外设负载,并不完全等同于CPU使用率(这种情况只出现在Linux中,其余系统比如Unix,Load还是只代表CPU负载),而且一般是会高于CPU使用率的,因为多包含了I/O等待等进程。也就导致了存在load很高,但是CPU使用率并不高的情况——一般是卡在了I/O那里。
CPU使用率
CPU的时间分片一般可分为4大类:用户进程运行时间 – UserTime, 系统内核运行时间 – SystemTime, 空闲时间 – IdleTime, 被抢占时间 – StealTime。除了IdleTime外,其余时间CPU都处于工作运行状态。
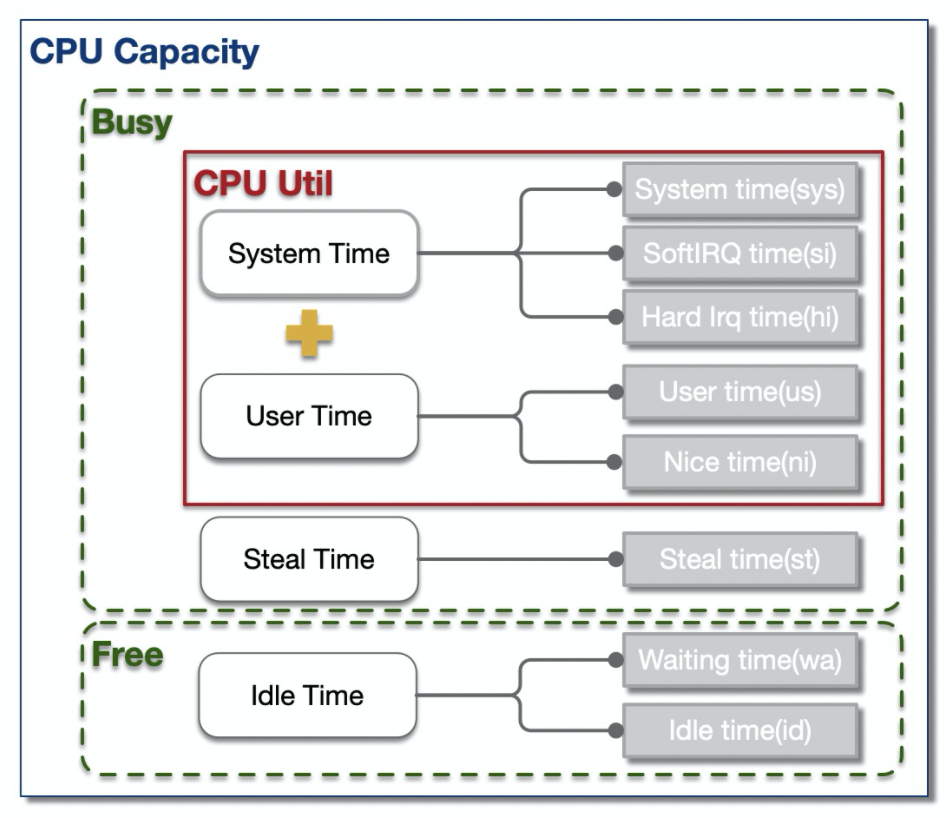
通常而言,我们泛指的整体CPU使用率为 UserTime 和 SystemTime 占比之和(例如tsar中CPU util),即:
CPUutil = (UserTime + SystemTime) / (UserTime + SystemTime + IdleTime + StealTime)
为了便于定位问题,大多数性能统计工具都将这4类时间片进一步细化成了8类,如下为top命令对CPU时间片的分类:
$ man top
...
As a default, percentages for these individual categories are displayed. Where two labels are shown below, those for more recent kernel versions are shown first.
us, user : 用户进程空间中未改变过优先级的进程占用CPU百分比(time running un-niced user processes)
sy, system : 内核空间占用CPU百分比(time running kernel processes)
ni, nice : 用户进程空间内改变过优先级的进程占用CPU百分比(time running niced user processes)
id, idle : 空闲时间百分比(time spent in the kernel idle handler)
wa, IO-wait : 空闲&等待I/O的时间百分比(time waiting for I/O completion)
hi : 硬中断时间百分比(time spent servicing hardware interrupts)
si : 软中断时间百分比(time spent servicing software interrupts)
st : 虚拟化时被其余VM窃取时间百分比(time stolen from this vm by the hypervisor)
...这8类分片中,除 wa 和 id 外,其余分片CPU都处于工作态。
2. 资源&瓶颈分析
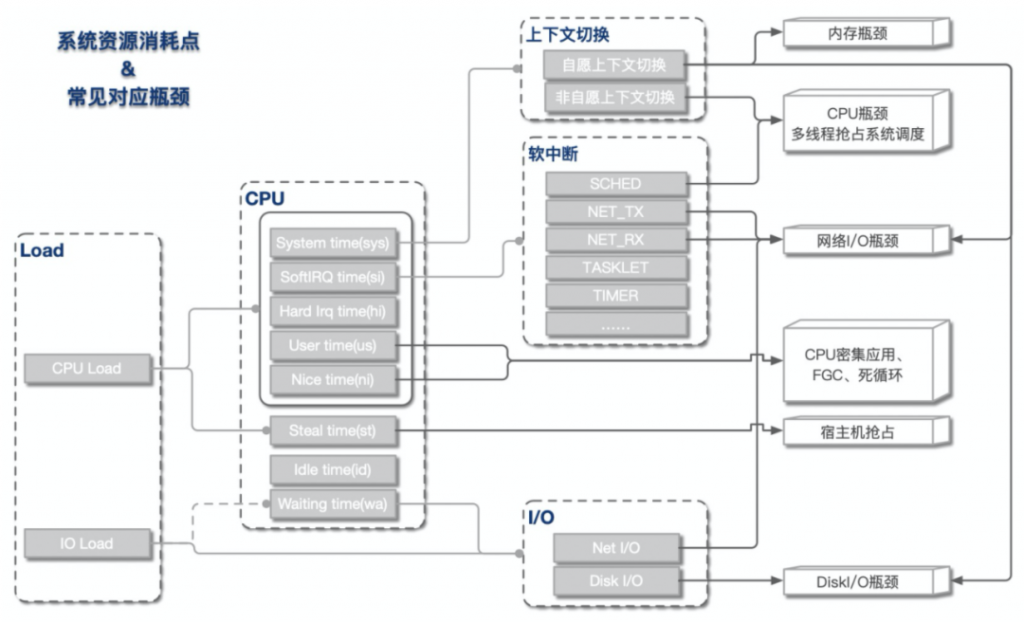
Load高 & CPU高
这是我们最常遇到的一类情况,即load上涨是CPU使用率上升导致。根据CPU具体资源分配表现,可分为以下几类:
- CPU sys高
这种情况CPU主要开销在于系统内核,可进一步查看上下文切换情况。
- 如果非自愿上下文切换较多,说明CPU抢占较为激烈,大量进程由于时间片已到等原因,被系统强制调度,进而发生的上下文切换。
- 如果自愿上下文切换较多,说明可能存在I/O、内存等系统资源瓶颈,大量进程无法获取所需资源,导致的上下文切换。
如何判断是自愿的上下文切换,还是非自愿的上下文切换?
- CPU si高
这种情况CPU大量消耗在软中断,可进一步查看软中断类型(cat /proc/softirqs)。一般而言,网络I/O或者线程调度引起软中断最为常见:
- NET_TX & NET_RX。NET_TX是发送网络数据包的软中断,NET_RX是接收网络数据包的软中断,这两种类型的软中断较高时,系统存在网络I/O瓶颈可能性较大。
- SCHED。SCHED为进程调度以及负载均衡引起的中断,这种中断出现较多时,系统存在较多进程切换,一般与非自愿上下文切换高同时出现,可能存在CPU瓶颈。
- CPU us高
这种情况说明资源主要消耗在应用进程,可能引发的原因有以下几类:
- 死循环或代码中存在CPU密集计算。这种情况多核CPU us会同时上涨。
- 内存问题,导致大量FULLGC,阻塞线程。这种情况一般只有一核CPU us上涨。
- 资源等待造成线程池满,连带引发CPU上涨。这种情况下,线程池满等异常会同时出现。
Load高 & CPU低
这种情况出现的根本原因在于不可中断睡眠态(TASK_UNINTERRUPTIBLE)进程数较多,即CPU负载不高,但I/O负载较高。可进一步定位是磁盘I/O还是网络I/O导致。
3. 具体排查策略
从问题发现到最终定位,基本可分为四个阶段:
- 资源瓶颈定位
这一阶段通过全局性能检测工具(top、vmstat、tsar、/proc/softirqs、/proc/interrupts、iostat、dstat),初步定位资源消耗异常位点。
- 热点进程定位
定位到资源瓶颈后,可进一步分析具体进程资源消耗情况(pidstat、pidstat、iotop、ps),找到热点进程。
- 线程&进程内部资源定位
找到具体进程后,可细化分析进程内部资源开销情况(pidstat、lsof)。
- 热点事件&方法分析
获取到热点线程后,我们可用trace或者dump工具,将线程反向关联,将问题范围定位到具体方法&堆栈。
但具体的问题排查和定位经验需要通过案例不断进行积累,只了解基本概念和知识是远远不够的,记忆也不深刻,所以每一次问题的排查都是学习和提高的机会,把握住了才能有进步和提高。
top命令的一些使用经验备忘录
1. 按内存占用排序、按CPU使用率排序
2. 查看各CPU的使用率,看是否存在不均衡的情况(在top命令界面中按下数字1即可打开/关闭)
进入top命令的界面之后,按下 h 键弹出帮助文档,下面捡几个最近了解到的有用的指令记录一下
1
f #按下之后会进入字段显示管理的界面,上下键用于导航,s用于指定排序的键,d用于显示或不显示列,q用于回到主界面(默认是根据CPU使用排序,但有些时候需要根据内存使用情况排序,还是很有用的)
x #用于高亮显示当前排序的列
k #用于杀掉指定任务,键入k之后会提示你输入pid,默认是当前排第一的pid,(Send pid xxx signal [15/sigterm])
L #用于进行任务定位,根据输入字符串进行查找(但是实际使用还是建议先退出去)
Help for Interactive Commands - procps-ng version 3.3.10
Window 1:Def: Cumulative mode Off. System: Delay 3.0 secs; Secure mode Off.
Z,B,E,e Global: 'Z' colors; 'B' bold; 'E'/'e' summary/task memory scale
l,t,m Toggle Summary: 'l' load avg; 't' task/cpu stats; 'm' memory info
0,1,2,3,I Toggle: '0' zeros; '1/2/3' cpus or numa node views; 'I' Irix mode
f,F,X Fields: 'f'/'F' add/remove/order/sort; 'X' increase fixed-width
L,&,<,> . Locate: 'L'/'&' find/again; Move sort column: '<'/'>' left/right
R,H,V,J . Toggle: 'R' Sort; 'H' Threads; 'V' Forest view; 'J' Num justify
c,i,S,j . Toggle: 'c' Cmd name/line; 'i' Idle; 'S' Time; 'j' Str justify
x,y . Toggle highlights: 'x' sort field; 'y' running tasks
z,b . Toggle: 'z' color/mono; 'b' bold/reverse (only if 'x' or 'y')
u,U,o,O . Filter by: 'u'/'U' effective/any user; 'o'/'O' other criteria
n,#,^O . Set: 'n'/'#' max tasks displayed; Show: Ctrl+'O' other filter(s)
C,... . Toggle scroll coordinates msg for: up,down,left,right,home,end
k,r Manipulate tasks: 'k' kill; 'r' renice
d or s Set update interval
W,Y Write configuration file 'W'; Inspect other output 'Y'
q Quit
( commands shown with '.' require a visible task display window )
Press 'h' or '?' for help with Windows,
Type 'q' or <Esc> to continue参考链接:
CPU飙高,系统性能问题如何排查? #nice
https://mp.weixin.qq.com/s/fzLcAkYwKhj-9hgoVkTzaw
一文带你全面了解 Load Average (负载) #nice
https://mp.weixin.qq.com/s/qqimEIOKjMJe7DHyXT09fA
Linux Load Averages: Solving the Mystery
http://www.brendangregg.com/blog/2017-08-08/linux-load-averages.html
What exactly is a load average?
http://linuxtechsupport.blogspot.com/2008/10/what-exactly-is-load-average.html
对cpu与load的理解及线上问题处理思路解读
https://mp.weixin.qq.com/s/ENGcqDABD9TLD6gjM0Jegw
【Linux负载系列-1】Linux 系统的平均负载(Load Avarage)
https://www.ebpf.top/post/linux_load_avg/
How to display top results sorted by memory usage in real time?
https://unix.stackexchange.com/questions/128953/how-to-display-top-results-sorted-by-memory-usage-in-real-time
=END=
《“Linux服务器的CPU使用率和load负载之间的关系”》 有 1 条评论
Linux Load Average:算法、实现与实用指南(2023)
http://arthurchiao.art/blog/linux-loadavg-zh/
`
借着遇到的一个问题,研究下 loadavg 的算法和实现。
1 一次 load spike 问题排查
1.1 现象
1.2 排查
1.2.1 宿主机监控:load 和 running 线程数量趋势一致
1.2.2 定位到进程(Pod)
1.2.3 Pod 监控:大量线程周期性状态切换
1.2.4 交叉验证
1.3 进一步排查方向
1.4 疑问
2 loadavg:算法与内核实现
2.1 原理与算法
2.1.1 有活跃线程:load 指数增长
2.1.2 无活跃线程:load 指数衰减
2.1.3 Load 测试与小结
2.2 内核基础
2.2.1 运行/调度队列 struct rq
2.2.2 Load 计算相关的全局变量
2.2.3 内核时间基础:HZ/tick/jiffies/uptime
2.3 算法实现
2.3.1 调用栈
2.3.2 一些实现细节
runqueue load 字段初始化
判断是否由当前 CPU 执行 load 计算
do_timer()
calc_global_load() -> calc_load()
2.4 考古
2.4.1 计入不可中断 sleep
2.4.2 Linux vs. 其他 OS:loadavg 区别
3 讨论
3.1 Load 很高,所有进程都会受影响吗?
3.1.1 模拟:单个 CPU 把系统 load 打高上百倍
3.1.2 cpuset vs. cpu quota
3.2 僵尸进程
3.3 Load != CPU 利用率
3.4 Load 是否是一个很好的告警指标?
4 实用指南
4.1 USE (Used-frequency, Saturation, Errors) 方法论
4.2 指标
4.2.1 Used-frequency 指标
4.2.2 Saturation 指标
5 结束语
References
`