=Start=
缘由:
很早就想了解一下eBPF的相关概念了,但一直都没有时间也没有动力,近期趁着稍微有点时间,通过检索到的一些文章简单了解学习一下eBPF的相关概念,方便后面有需要的时候再深入学习了解。
正文:
参考解答:
1. BPF是什么?
BPF(Berkeley Packet Filter),中文翻译为伯克利包过滤器,是类 Unix 系统上数据链路层的一种原始接口,提供原始链路层封包的收发。1992 年,Steven McCanne 和 Van Jacobson 写了一篇名为《BSD数据包过滤:一种新的用户级包捕获架构》的论文。在文中,作者描述了他们如何在 Unix 内核实现网络数据包过滤,这种新的技术比当时最先进的数据包过滤技术快 20 倍。BPF 在数据包过滤上引入了两大革新:
- 一个新的虚拟机 (VM) 设计,可以有效地工作在基于寄存器结构的 CPU 之上;
- 应用程序使用缓存只复制与过滤数据包相关的数据,不会复制数据包的所有信息。这样可以最大程度地减少BPF 处理的数据;
由于这些巨大的改进,所有的 Unix 系统都选择采用 BPF 作为网络数据包过滤技术,直到今天,许多 Unix 内核的派生系统中(包括 Linux 内核)仍使用该实现。
我们熟悉的 tcpdump 就是基于 BPF 技术。
2. eBPF是什么?
简而言之,eBPF是一套通用执行引擎,提供了一种在内核事件和用户程序事件发生时安全注入代码的通用能力,让这种通用能力的使用者不再局限于内核开发者。
eBPF 比起传统的 BPF 来说,传统的 BPF 只能用于网络过滤,而 eBPF 则可以用于更多的应用场景,包括网络监控、安全过滤和性能分析等。另外,eBPF 允许常规用户空间应用程序将要在 Linux 内核中执行的逻辑打包为字节码,当某些事件(称为挂钩)发生时,内核会调用 eBPF 程序。此类挂钩的示例包括系统调用、网络事件等。
2014 年初,Alexei Starovoitov 实现了 eBPF(extended Berkeley Packet Filter)。经过重新设计,eBPF 演进为一个通用执行引擎,可基于此开发性能分析工具、软件定义网络等诸多场景。eBPF 最早出现在 3.18 内核中,此后原来的 BPF 就被称为经典 BPF,缩写 cBPF(classic BPF),cBPF 现在已经基本废弃。现在,Linux 内核只运行 eBPF,内核会将加载的 cBPF 字节码透明地转换成 eBPF 再执行。
eBPF 新的设计针对现代硬件进行了优化,所以 eBPF 生成的指令集比旧的 BPF 解释器生成的机器码执行得更快。扩展版本也增加了虚拟机中的寄存器数量,将原有的 2 个 32 位寄存器增加到 10 个 64 位寄存器。由于寄存器数量和宽度的增加,开发人员可以使用函数参数自由交换更多的信息,编写更复杂的程序。总之,这些改进使 eBPF 版本的速度比原来的 BPF 提高了 4 倍。
3. eBPF为什么会出现?
eBPF的出现本质上是为了解决内核迭代速度慢和系统需求快速变化的矛盾,在eBPF领域常用的一个例子是eBPF相对于Linux Kernel类似于Javascript相对于HTML,突出的是可编程性。一般来说可编程性的支持通常会带来一些新的问题,比如内核模块其实也是为了解决这个问题,但是他没有提供很好的边界,导致内核模块会影响内核本身的稳定性,在不同的内核版本需要做适配等。eBPF采用Verifier、JIT编译器、bpf Helpers限制、maps/per-event等策略,使得其成为一种安全高效地内核可编程技术。
4. eBPF的应用场景是什么?
Networking – 网络
The combination of programmability and efficiency makes eBPF a natural fit for all packet processing requirements of networking solutions. The programmability of eBPF enables adding additional protocol parsers and easily program any forwarding logic to meet changing requirements without ever leaving the packet processing context of the Linux kernel. The efficiency provided by the JIT compiler provides execution performance close to that of natively compiled in-kernel code.
Security – 安全
Building on the foundation of seeing and understanding all system calls and combining that with a packet and socket-level view of all networking operations allows for revolutionary new approaches to securing systems. While aspects of system call filtering, network-level filtering, and process context tracing have typically been handled by completely independent systems, eBPF allows for combining the visibility and control of all aspects to create security systems operating on more context with better level of control.
Observability & Monitoring – 可观测性和监控
Instead of relying on static counters and gauges exposed by the operating system, eBPF enables the collection & in-kernel aggregation of custom metrics and generation of visibility events based on a wide range of possible sources. This extends the depth of visibility that can be achieved as well as reduces the overall system overhead significantly by only collecting the visibility data required and by generating histograms and similar data structures at the source of the event instead of relying on the export of samples.
Tracing & Profiling – 跟踪和优化
The ability to attach eBPF programs to trace points as well as kernel and user application probe points allows unprecedented visibility into the runtime behavior of applications and the system itself. By giving introspection abilities to both the application and system side, both views can be combined, allowing powerful and unique insights to troubleshoot system performance problems. Advanced statistical data structures allow to extract meaningful visibility data in an efficient manner, without requiring the export of vast amounts of sampling data as typically done by similar systems.
5. eBPF的架构
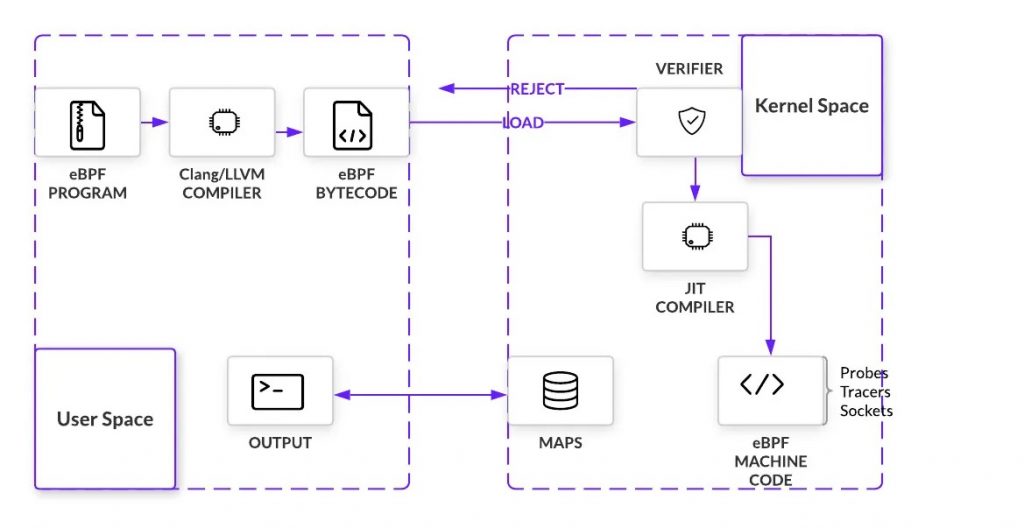
The important takeaway here is understanding that eBPF unlocks access to kernel level events without the typical restrictions found when changing kernel code directly. Summarizing, eBPF works by:
- Compiling eBPF programs into bytecode
- Verifying programs execute safely in a VM before being being loaded at the hook point
- Attaching programs to hook points within the kernel that are triggered by specified events
- Compiling at runtime for maximum efficiency
- Calling helper functions to manipulate data when a program is triggered
- Using maps (key-value pairs) to share data between the user space and kernel space and for keeping state.
6. eBPF的简单示例
step1. 准备工作,确保内核已经支持 eBPF 功能(如果还不支持,可能需要升级内核或是在内核配置文件中启用相关配置并重新编译内核)
ls /sys/fs/bpf
lsmod | grep bpfstep2. 编写 eBPF 程序
$ cat py_tcp_sendmsg_stat.py
#!/usr/bin/python3
from bcc import BPF
from time import sleep
# 定义 eBPF 程序
bpf_text = """
#include <uapi/linux/ptrace.h>
BPF_HASH(stats, u32);
int count(struct pt_regs *ctx) {
u32 key = 0;
u64 *val, zero=0;
val = stats.lookup_or_init(&key, &zero);
(*val)++;
return 0;
}
"""
# 编译 eBPF 程序
b = BPF(text=bpf_text, cflags=["-Wno-macro-redefined"])
# 加载 eBPF 程序
b.attach_kprobe(event="tcp_sendmsg", fn_name="count")
name = {
0: "tcp_sendmsg"
}
# 输出统计结果
while True:
try:
#print("Total packets: %d" % b["stats"][0].value)
for k, v in b["stats"].items():
print("{}: {}".format(name[k.value], v.value))
sleep(1)
except KeyboardInterrupt:
exit()step3. 运行 eBPF 程序
考虑到默认情况下的内核版本以及系统安装ISO镜像大小,我最后还是下载了 ubuntu-22.04.1-desktop-amd64 来作为学习测试环境(本来是想下载CentOS的)。
$ sudo apt install python3-bpfcc
$ chmod +x py_tcp_sendmsg_stat.py
$ sudo ./py_tcp_sendmsg_stat.py从上面的代码可以大概的看出编写 eBPF 程序的一个基本方法——在Python里向内核的某些事件挂载一段 “C语言” 的方式就是 eBPF 的编程方式。实话实说,这样的代码很不好写,可能会出现很多非常诡异的东西,一般人是很难驾驭的。好在这样的代码已经有人写了,我们不必再写了,在 Github 上的 bcc 库下的 tools 目录有很多……
- bcc-tools:一个包含许多常用的 BCC 工具的软件包。
- bpftrace:一个高级语言,用于编写和执行 BPF 程序。
- tcptop:一个实时监控和分析 TCP 流量的工具。
- execsnoop:一个用于监控进程执行情况的工具。
- filetop:一个实时监控和分析文件系统流量的工具。
- trace:一个用于跟踪和分析函数调用的工具。
- funccount:一个用于统计函数调用次数的工具。
- opensnoop:一个用于监控文件打开操作的工具。
- pidstat:一个用于监控进程性能的工具。
- profile:一个用于分析系统 CPU 使用情况的工具。
如果你想自己从头写 eBPF 程序,要么就是用 Python + bcc ,要么就是用 C/C++ + libbpf ,当然也可以选择 Golang + ebpf-go/libbpfgo ,或多或少都还是有一定学习门槛的,但能力和经验也是在踩坑和填坑的过程中得到成长的,如果说你的工作内容就是和这个非常相关,或者你当前有额外的时间和精力就是想要学习这门技术,还是非常推荐的,但具体到我自己身上,好像这2点都不是,那就只能先浅浅的了解一下——大概知道eBPF是什么、能做什么、大概需要做哪些才能实现相关的功能。以后如果真的有机会,再好好深入学习一下吧。
7. eBPF的最佳实践是什么?
寻找内核的插桩点
1、内核中都有哪些内核函数、内核跟踪点或性能事件?
2、对于内核函数和内核跟踪点,在需要跟踪它们的传入参数和返回值的时候,又该如何查询这些数据结构的定义格式呢?
寻找应用的插桩点
1、如何查询用户进程的跟踪点?
静态编译语言
非静态编译语言——解释型语言
非静态编译语言——即时编译型语言
2、选择跟踪点时的注意事项有哪些?
可以参考BCC的应用程序跟踪,用户进程的跟踪,本质上是通过断点去执行 uprobe 处理程序。虽然内核社区已经对 BPF 做了很多的性能调优,跟踪用户态函数(特别是锁争用、内存分配之类的高频函数)还是有可能带来很大的性能开销。因此,我们在使用 uprobe 时,应该尽量避免跟踪高频函数。
关联问题与插桩点
一个理想的状态是所有问题都清楚应当观察哪些插桩点,但是这个要求技术人员对端到端的软件栈细节都了解十分透彻,实际情况是很难满足的,一个更加合理的方法是二八法则,将软件栈数据流的最核心的80%脉络抓住,保障出现问题一定会在这个脉络被发现即可。此时再使用内核栈和用户栈来查看具体的调用栈即可发现核心问题。
x. 写在最后
用好eBPF的前提是对需求和目标环境的理解
通过上面的介绍,对eBPF已经有了一定的理解,eBPF提供的只是一个框架和机制,核心还是需要用eBPF的人对需求和目标环境的理解,找到合适的插桩点,能够和应用问题进行关联。
eBPF的杀手锏是全覆盖,无侵入,可编程
1、全覆盖
内核,应用程序插桩点全覆盖。
2、无侵入
不需要修改任何被hook的代码。
3、可编程
动态下发eBPF程序,边缘动态执行指令,动态聚合分析。
参考链接:
一文搞懂 | eBPF的来龙去脉
https://mp.weixin.qq.com/s/Rma1sKFzee3WvStl8t8hZA
一文读懂eBPF的前世今生
https://mp.weixin.qq.com/s/ww510TUdLG8jd6VzfQnjxw
EBPF 介绍
https://coolshell.cn/articles/22320.html
A Gentle Introduction to eBPF
https://www.infoq.com/articles/gentle-linux-ebpf-introduction/
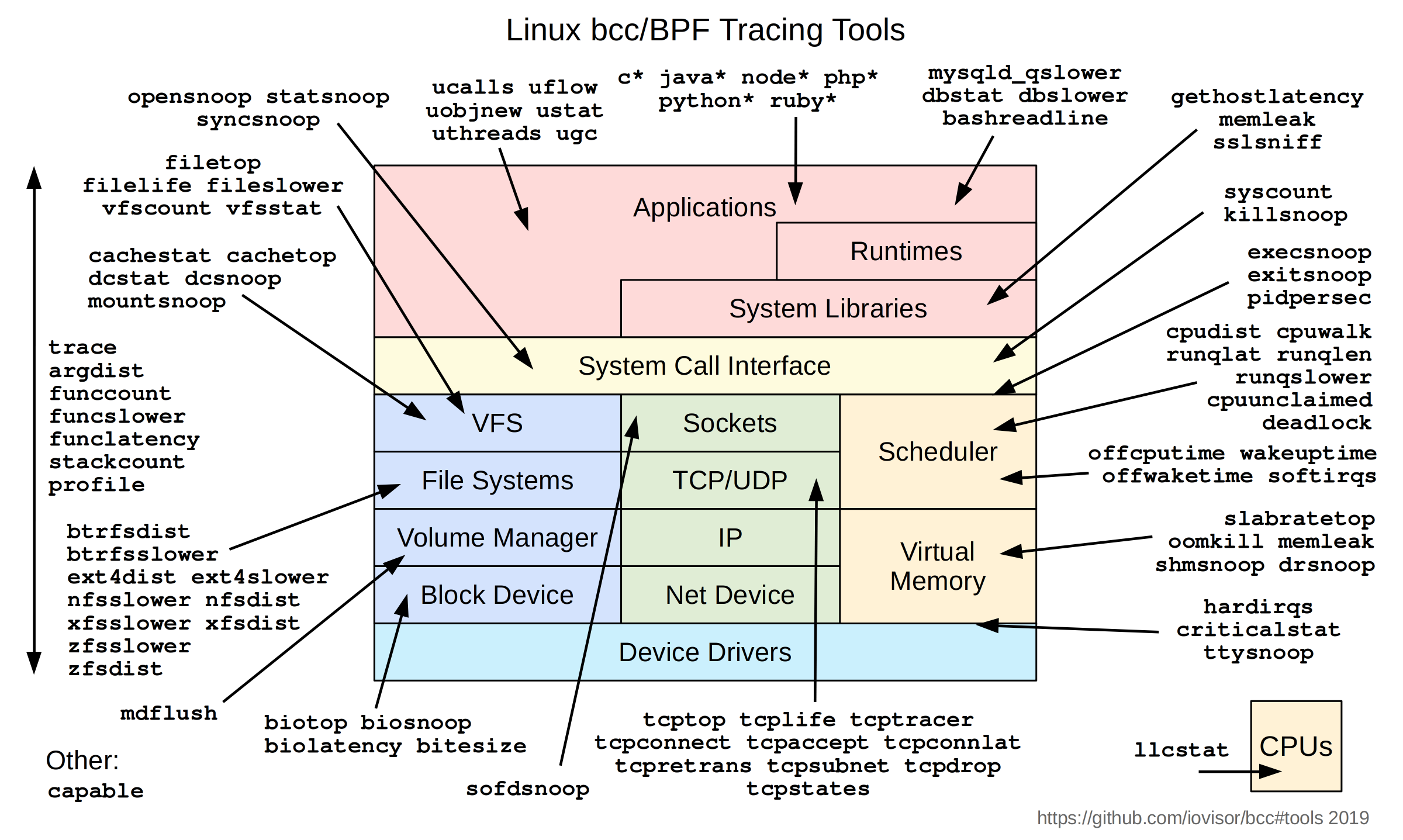
Linux bcc/bpf tracing tools
https://raw.githubusercontent.com/iovisor/bcc/master/images/bcc_tracing_tools_2019.png
{kind=link}
A curated list of awesome projects related to eBPF.
https://github.com/zoidbergwill/awesome-ebpf
深入浅出eBPF|你要了解的7个核心问题
https://mp.weixin.qq.com/s/Xr8ECrS_fR3aCT1vKJ9yIg
一文详解用eBPF观测HTTP
https://mp.weixin.qq.com/s/2ncM-PvN06lSwScvc2Zueg
如何使用eBPF观测用户空间应用程序
https://mp.weixin.qq.com/s/7SRHUPer58KlJZhn9y8kDg
一文看懂eBPF|eBPF的简单使用
https://mp.weixin.qq.com/s/V-5k1mX5JRA0lWLXJ2AxpA
一文看懂eBPF|eBPF实现原理
https://mp.weixin.qq.com/s/rvXIC96iDclB0tRX2JirUg
eBPF 技术报告(上)
https://mp.weixin.qq.com/s/rQ8paKRhS9RTSk2zR1cAEg
Tetragon – 盯向内核的眼睛
https://mp.weixin.qq.com/s/0IXlHu0LdQi1ttlcfSz1fg
=END=
《 “eBPF简单了解” 》 有 2 条评论
基于 Ubuntu 21.04 BPF 开发环境全攻略
https://www.ebpf.top/post/ubuntu_2104_bpf_env/
“`
# 安装 bpftool
$ sudo apt install linux-tools-generic
$ bpftool version
# 查看系统支持的eBPF程序类型
$ sudo bpftool feature probe | grep program_type
# 安装 bpftrace
$ sudo apt install bpftrace
# 查询所有内核插桩和跟踪点
sudo bpftrace -l
# 使用通配符查询所有的系统调用跟踪点
sudo bpftrace -l ‘tracepoint:syscalls:*’
# 使用通配符查询所有名字包含”open”的跟踪点
sudo bpftrace -l ‘*open*’
“`
eBPF入门文献汇总
https://mp.weixin.qq.com/s/ZqsxwaGcOLRp5cUJvquC4Q
`
☆ eBPF
1) bpftrace
1.1) 查看安装版bpftrace版本
1.2) 自编译bpftrace
1.3) tracepoint:*
1.3.1) tracepoint:syscalls:*
1.3.2) tracepoint:raw_syscalls:*
1.4) kprobe:*/kretprobe:*
1.4.1) BTF
1.4.2) override (修改返回值)
1.4.2.1) Inside override
1.4.2.2) connect_block.bt
1.4.3) kprobe:some+off
1.5) uprobe:*/uretprobe:*
1.5.2) uprobe:some+off
1.5.3) uprobe:addr
1.5.4) int3
1.5.5) endbr64
1.6) kfunc:*/kretfunc:*
1.9) bpftrace自带.bt
2) BCC
2.1) bpfcc-tools自带.py
2.1.1) bcc tools (git版)
2.2) ttysnoop
3) BPF Performance Tools
4) unprivileged_bpf_disabled
5) Offensive BPF
5.5) 检测恶意eBPF
5.5.1) bpftool
5.5.2) crash
5.5.3) bpf_probe_write_user
5.6) 嗅探口令明文
6) Bad BPF
6.2) 示例
7) libbpf (eBPF loader)
7.1) arg0 type FWD is not a struct
7.2) connect_block.bpf.c
7.2.1) bpf_strncmp
7.3) pamsnoop.bpf.c
7.4) 基于eBPF的后门口令
7.4.2) _unix_verify_password
7.4.4) 用stap查看相关函数调用栈回溯
7.4.5) verify_pwd_hash
7.4.6) pamtamper.bpf.c
7.4.7) 用ftrace/uprobe_events嗅探明文口令
7.4.8) 基于pam_permit.so的后门
7.5) ttysnoop.bpf.c
8) libbpf-bootstrap
8.1) 编译
8.2) eBPF代码兼容性
9) 其他文献
10) eBPF入门小结
10) eBPF入门小结
我将eBPF视作调试工具,对直方图之类的统计功能毫无兴趣,前面是我推荐的学习路线。从实践角度看,eBPF涉及bpftrace、BCC Python Bindings、libbpf编程。底层ftrace值得了解一下。若有DTrace、SystemTap经验,学习eBPF会省些事,没有也无所谓。简而言之,依次学习bpftrace、BCC、libbpf。可以预设一些具体小目标,实践之。
最初我对libbpf不感冒,后来发现,libbpf最具实用性,尤其当你的eBPF代码需要在陌生环境中运行时。不像bpftrace、BCC需要一大堆依赖,特别重型,静态链接libbpf的ELF可以随身携带。对于ttysnoop、pamsnoop、pamtamper这类功能来说,显然libbpf化才有实战意义。
`