=Start=
缘由:
在翻笔记的时候看到之前临时整理的一个“OLAP数据库的发展历程”的文档,之前本来是想记录到博客里面的,但一直没有动手,可能觉得主要内容是看文章看的,包含信息的部分都是参考链接中的文章里的,我只是摘录了一部分我觉得写的好的或是对我有启发的内容;但后来又想了想,就知识点而言我自己重新在这里记录一遍并没有必要,意义也不大,因为现在网上的内容非常多,资源/信息获取非常方便,IT/互联网行业发展又特别快,现在有效的信息可能过几年就过时没法用了。
但,如果我在记录这些信息的过程中加入一些自己的思考和实践,这个事情就产生了意义,首先,经验的分享是非常个人的,基本不存在重复一说,而且有些场景下经验往往比具体的操作指令或步骤对人的帮助更大;其次,互联网上的内容虽多,但鱼龙混杂,好的不少但明显差的更多,对不少人来说想找到好的内容还是有一定门槛和需要花费一定时间精力成本的,经过我自己筛选和验证过的,起码可以保证在当时那个情况下是OK的,不清楚对于其它人会怎么样,但对我自己来说,还是能降低检索成本和提高效率的。因此最后还是决定记录一下,方便后面回顾和参考,不经过整理和放出来,之前在这上面花费的时间和精力就太浪费了。
这里先记录一下数据库的分类,主要是MySQL和NoSQL的内容,下次再把OLAP的整理出来。
正文:
参考解答:
数据库是相关数据记录的有组织集合。数据库管理系统管理和操作数据库中的信息。
数据库的分类
根据不同的划分逻辑会产生不同的分类:
| 划分逻辑 | 数据库分类 |
|---|---|
| Model | 关系型数据库 Relational |
| Model | 非关系型数据库 Not-only/Non-Relational (NoSQL) |
| Design | Operational (OLTP) |
| Design | Analytical (OLAP) |
| …… | …… |
SQL和NoSQL数据库的区别
| 异同点 | SQL数据库 | NoSQL数据库 |
|---|---|---|
| Data Storage Model 数据存储模式 | Tables with fixed rows and columns 行列固定的表格 | 文档类型:文档 键值类型:键值对 宽列类型:具有动态列的表格 图类型:节点和边 |
| Development History | Developed in the 1970s with a focus on reducing data duplication 重点在于减少数据重复 | Developed in the late 2000s with a focus on scaling and allowing for rapid application change driven by agile and DevOps practices. 重点在于可扩展性和允许程序快速变更 |
| Examples | Oracle, MySQL, Microsoft SQL Server, and PostgreSQL | Document: MongoDB and CouchDB, Key-value: Redis and DynamoDB, Wide-column: Cassandra and HBase, Graph: Neo4j and Amazon Neptune |
| Primary Purpose | General purpose | Document: general purpose, Key-value: 数据量大,查询模式简单large amounts of data with simple lookup queries, Wide-column: 数据量大,查询模式可预测large amounts of data with predictable query patterns, Graph: 分析和遍历连接数据之间的关系analyzing and traversing relationships between connected data |
| Schemas | Rigid | Flexible-灵活 |
| Scaling | Vertical (scale-up with a larger server) 垂直扩展,换更大更好的服务器 | Horizontal (scale-out across commodity servers) 水平扩展,加更多的服务器就行 |
| Multi-Record ACID Transactions | Supported | Most do not support multi-record ACID transactions. However, some — like MongoDB — do. |
| Joins | Typically required | Typically not required |
| Data to Object Mapping | Requires ORM (object-relational mapping) | Many do not require ORMs. MongoDB documents map directly to data structures in most popular programming languages. |
NoSQL相比SQL数据库的优势:
- Flexible data models 灵活的数据模型
- Horizontal scaling 水平扩展
- Fast queries 快速查询
- Easy for developers 方便开发人员
| 类型 | 常见数据库 | 说明 |
|---|---|---|
| 键值数据库 | Redis,Memcached,Amazon DynamoDB | 它以键值对(Key-Value)的方式来存储和操作数据。 |
| 文档数据库 | MongoDB,CouchDB,Couchbase,ArangoDB | 文档数据库数据是一种类似于JSON或BSON(二进制JSON)的文档格式存储。这些文档可以包含各种类型的数据,如字符串、数值、数组、嵌套文档等。文档之间不需要遵循固定的模式,每个文档可以具有不同的字段和结构。 |
| 列式数据库 | HBase,Cassandra,BigTable | 它基于列族(column family)的概念来组织和存储数据 |
| 图数据库 | Neo4j,ArangoDB,InfoGrid | 图形数据库是一种特殊类型的NoSQL数据库,专门用于存储和处理图形数据。 |
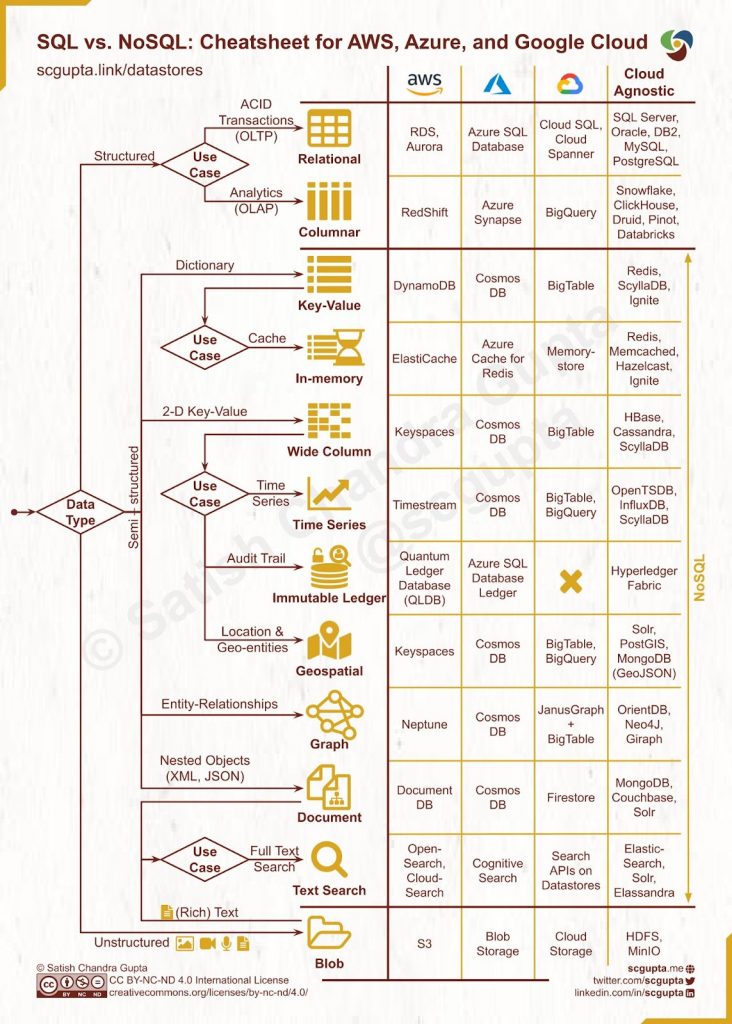
数据库选型时需要考虑的因素

在选择数据库时,需要考虑以下因素:
- 功能需求:根据项目的功能需求,选择具备所需功能的数据库。
- 性能要求:评估数据库的性能指标,包括读写速度、吞吐量和响应时间。
- 可扩展性:考虑数据库的扩展性,以便在需要时能够处理增长的数据量和用户访问量。
- 数据模型:根据数据的结构和关系,选择适合的数据模型(表格、文档、图形等)。
- 成本效益:综合考虑数据库的许可费用、维护成本和云服务费用等方面的成本。
- 社区支持和生态系统:选择具有活跃社区和完善生态系统的数据库,以便获取支持和扩展功能。
通过综合评估以上因素,可以做出明智的决策,选择适合项目的数据库。
参考链接:
SQL和NoSQL数据库的便捷速查表
https://mp.weixin.qq.com/s/gvKAO7PeL9ZdQ5hpIxwKew
Understanding Database Types
https://blog.bytebytego.com/p/understanding-database-types
SQL vs. NoSQL Database: When to Use, How to Choose
https://towardsdatascience.com/datastore-choices-sql-vs-nosql-database-ebec24d56106
https://www.ml4devs.com/articles/datastore-choices-sql-vs-nosql-database/
Types of Databases
https://www.javatpoint.com/types-of-databases
Types of Databases
https://www.mongodb.com/databases/types
NoSQL vs. SQL Databases
https://www.mongodb.com/nosql-explained/nosql-vs-sql
Database Types Explained
https://phoenixnap.com/kb/database-types
数据库存储选型经验总结
https://mp.weixin.qq.com/s/_uNHR1nkEt43Mle0Vpi-og
=END=
《 “数据库的分类和选型” 》 有 2 条评论
一文读懂内存数据库
https://mp.weixin.qq.com/s/MJnGKJutU8EqDeOv9aa7Vg
`
# Redis虽然好,但阿里云为何还力推Tair?
对Key-Value数据库大家可能了解还是比较多,比如:
Aerospike
LevelDB
Scalaris
Project Voldemort
HyperDex
Berkeley DB
Apache Accumulo
Apache Cassandra
Redis
MongoDB
Memcached
其中,在近年来,Redis的表现尤为突出。这是为什么呢?
没有比较就没有鉴别。那么,我们拿Memcached与Redis做一个简单的对比分析。作为一个高性能的key-value存储系统,Redis和Memcached有点类似,为了保证数据读写效率,在内存中实现了数据的缓存。
但是,Redis实现了更好的功能。
Redis虽好,然而开源Redis作为云内存数据库,却有着比较大的局限性。
其一,在Redis Class下构建大容量服务,成本问题已经出现。在分片数较少,单个分片较大情况下,调用Fork同步操作带来服务不稳,同时持久化带来服务恢复缓慢,虽然采用主多从的形式来保证服务的可用性,但在多实例下,其管理成本和内部通信成本的开销增大。
其二,Redis本身持久化数据的能力有限,最新版本推出了RDB和AOF两种模式来提升持久化能力。然而在实际应用中,Everysecond每秒持久化的形式十分不利于实际应用,特别是将Redis已经作为最终存储数据的数据库在应用,一旦出现问题,将波及大量的整体数据。“在一个如10万TPS高吞吐的场景下,一秒的数据丢失可能就意味着数万条数据记录的丢失。”对数据可靠性要求很高的用户来说,这是最大的问题。此外Redis缓存+主存储方式来提升持久化,也带来数据一致性、主从数据库开销等系列问题。
# 青出于蓝而胜于蓝,十二年认真锤炼Tair
2018年,Tair正式开始投入Intel AEP的研究和使用落地。并成功应用于当年双11的电商商品核心集群中,大幅降低了成本,成为中国首个在生产环境正式部署应用Intel AEP的产品。不过,当时的Tair软件层并没有在AEP上做相关数据持久化和恢复的特性,仅作为缓存使用。
2019年4月,阿里云的云数据库Redis产品在Redis开源社区贡献排名第三。
2020年9月,Tair正式推出持久存储系统形态,加速进入多存储引擎时代。随着云上环境的成熟,Tair基于AEP,全新研发了数据持久落地的自研引擎,并融入神龙裸金属服务器和云原生数据库管理系统的技术优势。整体能力上,获得了近似内存的性能,90%的吞吐能力,而成本降低了30%。同时,从内存的易失性到AEP的持久能力,Tair自研引擎的每个操作都能持久化,大幅降低数据丢失的风险。
……
在硬件选择上,持久内存型采用了Intel 傲腾持久内存(AEP),容量存储型采用了阿里云ESSD云盘。
英特尔傲腾(AEP)持久内存架构的特点突出,在DRAM内存和块存储之间,加入大容量持久内存层,数据不会丢失,同时以高性价比提供出色性能。Tair持久内存型采用Intel 傲腾(AEP)持久内存技术后,兼容绝大部分Redis数据结构和命令,借助AEP的App Direct模式,实现了高性能下的命令级持久化能力。在价格上,Tair持久内存型相当于阿里云社区版Redis价格的70%左右,适用于要求高吞吐、低延迟同时对数据可靠性要求高的热数据存取场景。
然而,对于温冷数据存取场景,用户要求更高的数据持久化,以及更高的存储密度,数据访问频率也相对较低。基于阿里云ESSD云盘技术,推出的Tair容量存储型,兼容Redis核心数据结构与命令,满足用户超大容量、平均性能有所妥协的温冷数据存取服务。
……
`
数据仓库–通用的数据仓库分层方法 #nice,详细全面
https://www.cnblogs.com/itboys/p/10592871.html
`
0x01 为什么要进行数据分层?
数据分层并不能解决所有的数据问题,但是,数据分层却可以给我们带来如下的好处:
清晰数据结构:每一个数据分层都有它的作用域和职责,在使用表的时候能更方便地定位和理解
减少重复开发:规范数据分层,开发一些通用的中间层数据,能够减少极大的重复计算
统一数据口径:通过数据分层,提供统一的数据出口,统一对外输出的数据口径
复杂问题简单化:将一个复杂的任务分解成多个步骤来完成,每一层解决特定的问题
0x02 一种通用的数据分层设计
为了满足前面提到数据分层带来的好处,我们将数据模型分为三层:数据运营层(ODS)、数据仓库层(DW)和数据应用层(APP)。简单来讲,我们可以理解为:**ODS层存放的是接入的原始数据,DW层是存放我们要重点设计的数据仓库中间层数据,APP是面向业务定制的应用数据**。
一、数据运营层:ODS(Operational Data Store)
“面向主题的”数据运营层,也叫ODS层,是最接近数据源中数据的一层,数据源中的数据,经过抽取、洗净、传输,也就说传说中的 ETL 之后,装入本层。本层的数据,总体上大多是按照源头业务系统的分类方式而分类的。
一般来讲,为了考虑后续可能需要追溯数据问题,因此对于这一层就不建议做过多的数据清洗工作,原封不动地接入原始数据即可,至于数据的去噪、去重、异常值处理等过程可以放在后面的DWD层来做。
二、数据仓库层:DW(Data Warehouse)
数据仓库层是我们在做数据仓库时要核心设计的一层,在这里,从 ODS 层中获得的数据按照主题建立各种数据模型。DW层又细分为 DWD(Data Warehouse Detail)层、DWM(Data WareHouse Middle)层和DWS(Data WareHouse Servce)层。
1. 数据明细层:DWD(Data Warehouse Detail)
该层一般保持和ODS层一样的数据粒度,并且提供一定的数据质量保证。同时,为了提高数据明细层的易用性,该层会采用一些维度退化手法,将维度退化至事实表中,减少事实表和维表的关联。
另外,在该层也会做一部分的数据聚合,将相同主题的数据汇集到一张表中,提高数据的可用性,后文会举例说明。
2. 数据中间层:DWM(Data WareHouse Middle)
该层会在DWD层的数据基础上,对数据做轻度的聚合操作,生成一系列的中间表,提升公共指标的复用性,减少重复加工。
直观来讲,就是对通用的核心维度进行聚合操作,算出相应的统计指标。
3. 数据服务层:DWS(Data WareHouse Servce)
又称数据集市或宽表。按照业务划分,如流量、订单、用户等,生成字段比较多的宽表,用于提供后续的业务查询,OLAP分析,数据分发等。
一般来讲,该层的数据表会相对比较少,一张表会涵盖比较多的业务内容,由于其字段较多,因此一般也会称该层的表为宽表。
在实际计算中,如果直接从DWD或者ODS计算出宽表的统计指标,会存在计算量太大并且维度太少的问题,因此一般的做法是,在DWM层先计算出多个小的中间表,然后再拼接成一张DWS的宽表。由于宽和窄的界限不易界定,也可以去掉DWM这一层,只留DWS层,将所有的数据在放在DWS亦可。
三、数据应用层:APP(Application)
在这里,主要是提供给数据产品和数据分析使用的数据,一般会存放在 ES、PostgreSql、Redis等系统中供线上系统使用,也可能会存在 Hive 或者 Druid 中供数据分析和数据挖掘使用。比如我们经常说的报表数据,一般就放在这里。
四、维表层(Dimension)
最后补充一个维表层,维表层主要包含两部分数据:
高基数维度数据:一般是用户资料表、商品资料表类似的资料表。数据量可能是千万级或者上亿级别。
低基数维度数据:一般是配置表,比如枚举值对应的中文含义,或者日期维表。数据量可能是个位数或者几千几万。
`