=Start=
缘由:
最近在全面整理各大数据存储/处理系统的架构、日志记录和安全监控能力,这次是 Hive ,先整理学习一下 Hive 的基本原理及其架构,方便理解一些问题和设计思路,也方便后面有需要的时候参考。
正文:
参考解答:
Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类 SQL 查询功能。其本质是将 SQL 转换为 MapReduce/Spark 的任务进行运算,底层由 HDFS 来提供数据的存储,说白了 Hive 可以理解为一个将 SQL 转换为 MapReduce/Spark 的任务的工具,甚至更进一步可以说 Hive 就是一个 MapReduce/Spark Sql 的客户端。
Hive 的主要组件
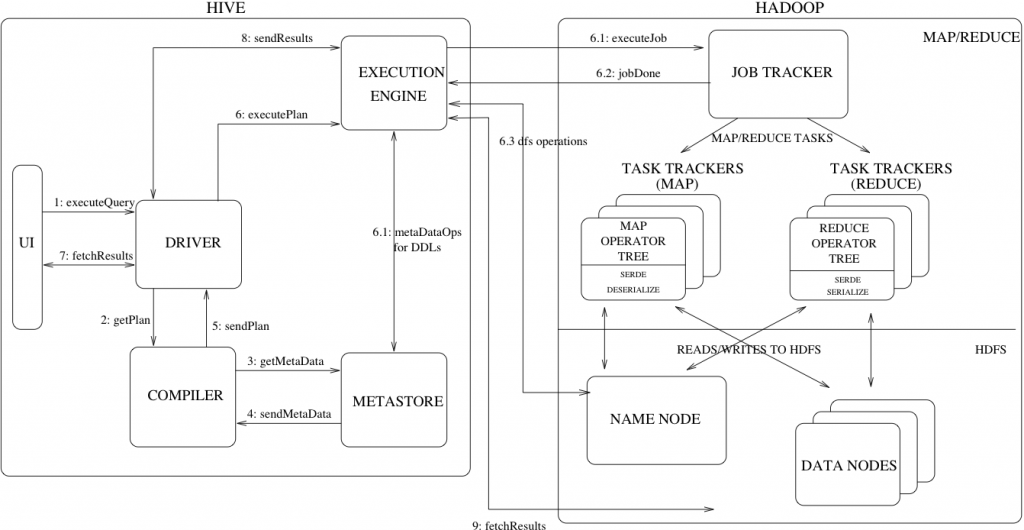
UI – The user interface for users to submit queries and other operations to the system.
用户界面(UI)–用户向系统提交查询和其他操作的用户界面。
Driver – The component which receives the queries. This component implements the notion of session handles and provides execute and fetch APIs modeled on JDBC/ODBC interfaces.
驱动程序 – 接收查询的组件。该组件实现会话句柄的概念,并提供以 JDBC/ODBC 接口为模型的执行和获取 API。
Compiler – The component that parses the query, does semantic analysis on the different query blocks and query expressions and eventually generates an execution plan with the help of the table and partition metadata looked up from the metastore.
编译器 – 该组件负责解析查询,对不同的查询块和查询表达式进行语义分析,并借助从元存储中查找的表和分区元数据最终生成执行计划。
Metastore – The component that stores all the structure information of the various tables and partitions in the warehouse including column and column type information, the serializers and deserializers necessary to read and write data and the corresponding HDFS files where the data is stored.
元存储 – 存储仓库中各种表和分区的所有结构信息的组件,包括列和列类型信息、读写数据所需的序列化器和反序列化器以及存储数据的相应 HDFS 文件。
Execution Engine – The component which executes the execution plan created by the compiler. The plan is a DAG of stages. The execution engine manages the dependencies between these different stages of the plan and executes these stages on the appropriate system components.
执行引擎 – 执行编译器创建的执行计划的组件。该计划是由多个阶段组成的 DAG。执行引擎管理计划不同阶段之间的依赖关系,并在适当的系统组件上执行这些阶段。
Hive与Hadoop的交互流程
上图还显示了一个典型查询是如何在系统中流动的。
用户界面调用驱动程序的执行接口(上图中的步骤 1)。
驱动程序为查询创建会话句柄,并将查询发送给编译器以生成执行计划(步骤 2)。
编译器从元存储中获取必要的元数据(步骤 3 和 4)。
元数据用于对查询树中的表达式进行类型检查,并根据查询谓词剪切分区。编译器生成的计划(步骤 5)是一个阶段 DAG,每个阶段可以是一个 map/reduce 作业、一个元数据操作或 HDFS 上的一个操作。
对于映射/还原阶段,计划包含映射运算树(在映射器上执行的运算树)和还原运算树(用于需要还原器的操作)。
执行引擎会将这些阶段提交给相应的组件(步骤 6、6.1、6.2 和 6.3)。
在每个任务(映射器/还原器)中,与表格或中间输出相关的反序列化器用于从 HDFS 文件中读取行,并通过相关的运算树。输出生成后,将通过序列化器写入临时 HDFS 文件(如果操作不需要还原,则在映射器中进行)。临时文件用于为计划的后续映射/还原阶段提供数据。对于 DML 操作,最终临时文件会被移动到表的位置。该方案用于确保不读取脏数据(文件重命名在 HDFS 中是原子操作)。对于查询,执行引擎直接从 HDFS 读取临时文件的内容,作为从驱动程序获取调用的一部分(步骤 7、8 和 9)。
1、 executeQuery:用户通过Hive界面(CLI/Web UI)将查询语句发送到Driver(驱动有JDBC、ODBC等)来执行;
2、 getPlan :Driver根据查询编译器解析query语句,验证query语句的语法、查询计划、查询条件;
3、 getMetaData:编译器将元数据请求发送给Metastore;
4、 send MetaData:Metastore将元数据作为响应发送给编译器;
5、 send Plan:编译器检查要求和重新发送Driver的计划。至此,查询的解析和编译完成;
6、 execute Plan:Driver将执行计划发送给执行引擎;
6.1、 MetaDataOps for DDLs:执行引擎发送任务的同时,对hive元数据进行相应操作(直接对数据库表进行操作的(创建表、删除表等),直接与MetaStore进行交互)。
6.1、 execute Job:mapreduce执行job的过程。执行引擎发送任务到resourcemanager,resourcemanager将任务分配给nodenameger,由nodemanager分布式执行mapreduce任务。
6.2、 任务执行结束,返回执行结果给执行引擎,同步执行6.3;
6.3、 找Namenode获取数据
7、fetch Results:执行引擎接收来自数据节点(data node)的结果
8、sendResults:执行引擎发送这些合成值到Driver
9、sendResults:Driver将结果发送到hive接口
一个简化版本的示意图:
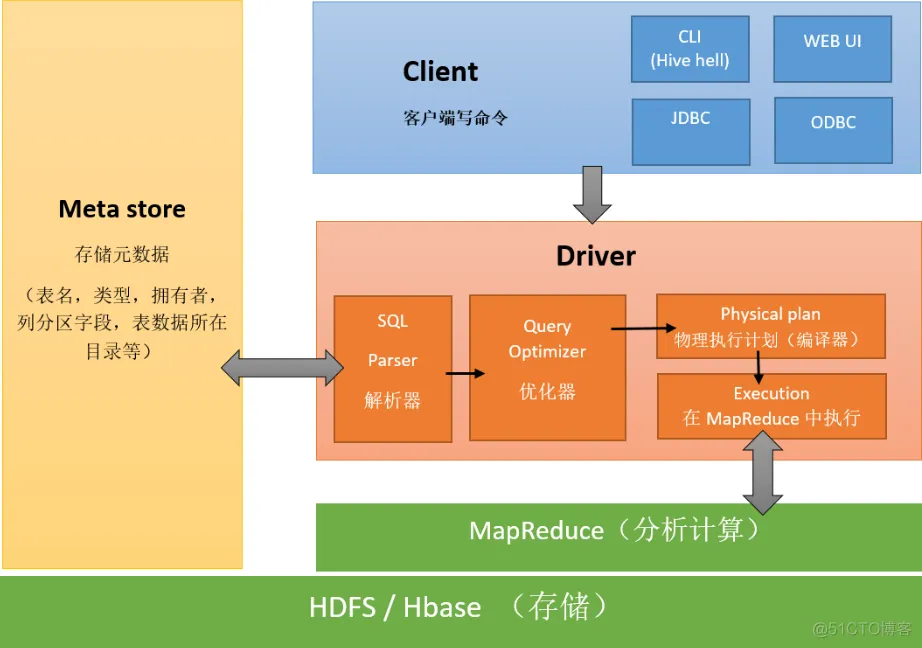
上面的MapReduce可以替换成Tez、Spark。
参考链接:
一文弄懂Hive基本架构和原理
https://blog.csdn.net/oTengYue/article/details/91129850
Apache Hive
https://cwiki.apache.org/confluence/display/Hive/Home
Hive design and architecture
https://cwiki.apache.org/confluence/display/Hive/Design
10、Hive核心概念和架构原理
https://blog.51cto.com/u_10312890/2465756
Hive的架构剖析
https://jiamaoxiang.top/2020/06/27/Hive%E7%9A%84%E6%9E%B6%E6%9E%84%E5%89%96%E6%9E%90/
一篇文章搞懂 Hive 的系统架构
https://blog.csdn.net/Shockang/article/details/118035262
Hive 架构与表类型
https://xie.infoq.cn/article/6949b16d4ebaeef022c003834
Hadoop之Hive架构与设计
https://www.cnblogs.com/thesungod/p/17612231.html
Hive service, HiveServer2 & MetaStore service?
https://stackoverflow.com/questions/49799838/hive-service-hiveserver2-metastore-service
How HiveServer2 Brings Security and Concurrency to Apache Hive
https://blog.cloudera.com/how-hiveserver2-brings-security-and-concurrency-to-apache-hive/
Securing Apache Hive
https://docs.cloudera.com/cdw-runtime/1.5.1/securing-hive/hive_securing_hive.pdf
A Deep Dive into Apache Hive Architecture: From Data Storage to Data Analysis with SQL-like Hive Query Language
https://nexocode.com/blog/posts/what-is-apache-hive/
Architecture and Working of Hive
https://www.geeksforgeeks.org/architecture-and-working-of-hive/
Hive,Hive on Spark和SparkSQL区别
https://www.cnblogs.com/lixiaochun/p/9446350.html
大数据时代的技术hive:hive介绍
https://www.cnblogs.com/sharpxiajun/archive/2013/06/02/3114180.html
Hive与Hadoop的交互流程
https://www.cnblogs.com/MrFee/p/hive_hadoop.html
Hive架构原理-官网中文翻译
https://blog.csdn.net/JacksonKing/article/details/89637131
hive基本概念原理与底层架构
https://blog.csdn.net/u013129109/article/details/81453582
Hive 架构
https://www.hadoopdoc.com/hive/hive-architecture
=END=
《 “Hive的基本原理和架构学习” 》 有 5 条评论
Hive架构理解
Hive service, HiveServer2 & MetaStore service?
https://stackoverflow.com/questions/49799838/hive-service-hiveserver2-metastore-service
`
I am trying to understand hive in terms of architecture, and I am referring to Tom White’s book on Hadoop.
我试图从架构的角度来理解 hive ,我参考了 Tom White 关于 Hadoop 的书。
Referring to below diagrams from the Book (Hadoop: The definitive Guide).
请参阅《Hadoop:权威指南》一书中的以下图表。
==
# Hive Services Hive服务
* HiveServer2 Hive服务器2
* Hive Metastore Hive元数据库
* HCatalog + WebHcat
* Beeline & Hive CLI
* Thrift client
* FileSystem :: HDFS and other compatible filesystems like S3 文件系统:HDFS 和其他兼容文件系统,如 S3
* Execution engine :: MapReduce, Tez, Spark 执行引擎:MapReduce、Tez、Spark
* Hive Web UI (added in Hive 2.x). Maybe also Tez or Spark UI, but not really Hive Web UI(在 Hive 2.x 中添加)。也许还有 Tez 或 Spark UI,但不完全是
# Driver 驱动
The JDBC/ODBC or Thrift interfaces have drivers. JDBC/ODBC 或 Thrift 接口都有驱动程序。 There are also the processes that interpret the query and compile it down to the execution engine code. I personally call that an interpreter or compiler, not a driver 此外,还有解释查询并将其编译为执行引擎代码的过程。我个人称之为解释器或编译器,而不是驱动程序。
# Metastore Server 元存储服务器
Not part of HiveServer2. It is literally a process running on top of an RDBMS (yes, you still need these when running Hive & Hadoop). 不属于 HiveServer2 的一部分。它实际上是运行在 RDBMS 上的一个进程(是的,在运行 Hive 和 Hadoop 时仍然需要这些)。
Supported Remote Metastore servers = Oracle, MySQL, Postgres 支持的远程元存储服务器 = Oracle、MySQL、Postgres Embedded Metastore (not recommended for production) = Derby 嵌入式 Metastore(不建议用于生产)= Derby
See Hive Wiki 参见Hive维基
# Metastore JVM 元存储 JVM
The orange boxes are showing you can deploy these services as part of the same JVM as the driver (interpreter) or as a remote server. The wiki describes these setups. 橙色方框显示您可以将这些服务作为驱动程序(解释器)或远程服务器部署到同一 JVM 中。维基介绍了这些设置。
I believe this is a side-car process that maps the HiveServer2 queries to the MetaStore queries. For example, how do you translate the HiveQL into a process that reads metadata from MySQL or Postgres? 我认为这是一个将 HiveServer2 查询映射到 MetaStore 查询的侧载流程。例如,如何将 HiveQL 转换为从 MySQL 或 Postgres 读取元数据的流程?
It can run on the server-side, yes, but this is not a recommended setup for fault tolerance and performance reasons. 是的,它可以在服务器端运行,但出于容错和性能方面的考虑,不建议这样设置。
HiveServer1 is deprecated. Feel free to read about it, but don’t use it. HiveServer1 已被弃用。请随意阅读,但不要使用。
==
The functionality is spread across all components. The HiveServer2 accepts a query request, contacts the metastore, computes some query optimizations, then submits YARN containers for the appropriate execution engine. Results are fed back to the HiveServer2, and collected as a resultset to the client
这些功能分布在所有组件中。HiveServer2 接受查询请求,联系元存储,计算一些查询优化结果,然后将 YARN 容器提交给相应的执行引擎。结果将反馈给 HiveServer2,并作为结果集收集到客户端
==
Beeline is a JDBC Driver, so yes. Again, I would not call that orange box a Driver. It’s essentially a SQL compiler into the execution engine runtime, which is not a client side action
Beeline 是一个 JDBC 驱动程序,所以是的。同样,我不会把那个橙色的盒子称为驱动程序。它本质上是一个 SQL 编译器,用于执行引擎运行时,而不是客户端操作。
`
Hive日志记录
HiveServer2 Logging
https://cwiki.apache.org/confluence/display/hive/hiveserver2+clients#HiveServer2Clients-HiveServer2Logging
`
Starting with Hive 0.14.0, HiveServer2 operation logs are available for Beeline clients. These parameters configure logging:
* hive.server2.logging.operation.enabled
* hive.server2.logging.operation.log.location
* hive.server2.logging.operation.verbose (Hive 0.14 to 1.1)
* hive.server2.logging.operation.level (Hive 1.2 onward)
HIVE-11488 (Hive 2.0.0) adds the support of logging queryId and sessionId to HiveServer2 log file. To enable that, edit/add %X{queryId} and %X{sessionId} to the pattern format string of the logging configuration file.
`
hive.server2.logging.operation.level
https://cwiki.apache.org/confluence/display/Hive/Configuration+Properties#ConfigurationProperties-hive.server2.logging.operation.log.location
`
hive.server2.logging.operation.level
* Default Value: EXECUTION
* Added In: Hive 1.2.0 with HIVE-10119
HiveServer2 operation logging mode available to clients to be set at session level.
For this to work, hive.server2.logging.operation.enabled should be set to true. The allowed values are:
* NONE: Ignore any logging.
* EXECUTION: Log completion of tasks.
* PERFORMANCE: Execution + Performance logs.
* VERBOSE: All logs.
`
Add sessionId and queryId info to HS2 log
https://issues.apache.org/jira/browse/HIVE-11488
Spark与MapReduce的区别是什么?
https://zhuanlan.zhihu.com/p/364290009
`
Spark 和 MapReduce 的异同
总结:
与Hadoop的MapReduce相比,Spark基于内存的运算要快100倍以上,基于硬盘的运算也要快10倍以上。Spark实现了高效的 DAG执行引擎,可以通过基于内存来高效处理数据流。
两者速度差异的关键点在于:
Spark基于DAG(有向无环图)的任务调度机制优于MapReduce(一般而言,DAG相比MapReduce在大多数情况下可以减少 shuffle 次数);
同时还提供内存计算,将中间结果直接放到内存中,带来了更高的迭代运算速度。
==
Spark把中间计算结果存放在内存中,减少迭代计算过程中的数据落地,运算效率高。MapReduce中的计算中间结果是保存在磁盘上的,运算效率差。
==
spark适合迭代,mapreduce不适合迭代
spark是一种基于内存的计算框架(有时也会用磁盘-spark shuffle )
spark 的优点:
1. 虽然它的计算模式也属于map – Reduce,但又不局限于map – Reduce。
2. 提供内存计算,中间结果直接放到内存中,带来了更高的迭代运算
3. spark基于DAG(有向无环图)的任务调度机制优于mapreduce
mapreduce表达能力有限,磁盘I/O开销也大,延迟也高。(必须基于磁盘以及大量的网络传输)
其实mapreduce适合处理速度不敏感的离线批处理。
总结起来,任务逻辑需要多次map reduce才能完成时,spark远快于mr,如果任务只是单次map reduce,spark大概率也是更快(dataset等结构是精心设计过的,mr没有规定数据格式),但是肯定没有复杂任务那么悬殊
Spark快是很多因素综合的结果,不仅仅是因为内存计算。
Spark 计算比 MapReduce 快的根本原因在于 DAG(有向无环图)计算模型。一般而言,DAG 相比MapReduce 在大多数情况下可以减少 shuffle 次数。Spark 的 DAGScheduler 相当于一个改进版的 MapReduce,如果计算不涉及与其他节点进行数据交换,Spark 可以在内存中一次性完成这些操作,也就是中间结果无须落盘,减少了磁盘 IO 的操作。但是,如果计算过程中涉及数据交换,Spark 也是会把 shuffle 的数据写磁盘的!有一个误区,Spark 是基于内存的计算,所以快,这不是主要原因,要对数据做计算,必然得加载到内存,Hadoop 也是如此,只不过 Spark 支持将需要反复用到的数据给 Cache 到内存中,减少数据加载耗时,所以 Spark 跑机器学习算法比较在行(需要对数据进行反复迭代)
`
Apache Spark vs MapReduce: A Detailed Comparison
https://www.knowledgehut.com/blog/big-data/apache-spark-and-mapreduce-comparison
Spark与MapReduce的区别是什么?
https://zhuanlan.zhihu.com/p/364290009
Hadoop vs. Spark: What’s the Difference?
https://www.ibm.com/cloud/blog/hadoop-vs-spark
Difference between MapReduce and Spark
https://www.tutorialspoint.com/difference-between-mapreduce-and-spark
Apache Spark Vs. Hadoop MapReduce – Top 7 Differences
https://www.analyticsvidhya.com/blog/2022/06/apache-spark-vs-hadoop-mapreduce-top-7-differences/
Difference Between MapReduce and Apache Spark
https://www.geeksforgeeks.org/difference-between-mapreduce-and-apache-spark/
【面试题】MapReduce和Spark的区别与联系
https://blog.csdn.net/weixin_43230682/article/details/105548049
Spark 简单介绍 基本概念 和MapReduce的区别
https://blog.csdn.net/qq_35260875/article/details/124071029